
이전 글 보기
1. Attention Mechanism
2. Bahdanau Attention
BiLSTM + Bahdanau Attention
1, 2 글에서 학습한 어텐션 메커니즘에 + BiLSTM 을 사용한 구조를 통해 분류 문제를 풀어보자.
from tensorflow.keras.datasets import imdb
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.sequence import pad_sequences
필요한 것들을 가져오자.
- 케라스 데이터셋에서 imdb 데이터셋을 가져오자
vocab size는 10,000 으로 제한하고, 훈련 데이터와 테스트 데이터를 가져오자.
vocab_size = 10000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words = vocab_size)X_train 훈련 데이터 전부를 돌며 가장 긴 리뷰와 평균 길이를 확인해보자.
print('리뷰의 최대 길이 : {}'.format(max(len(l) for l in X_train)))
print('리뷰의 평균 길이 : {}'.format(sum(map(len, X_train))/len(X_train)))

가장 긴 리뷰는 2494 의 단어로 이루어져있고, 평균적으로는 238개의 단어가 포함되어 있었다.
데이터 패딩은 평균보다 긴 500을 주었다. 패딩을 하기 위해선 케라스에서 전처리 모듈을 불러와 pad_sequence 로 처리할 수 있다! X변수에 대해서 적용시켜줬다.
max_len = 500
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)

Bahdanau Attention 선언
바다나우 어텐션의 스코어 함수를 보고 어텐션 메커니즘을 구현하자. 바다나우 어텐션 스코어함수는 다음과 같았다.
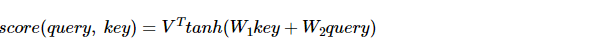
- V, W1, W2 는 학습 가능한 가중치 행렬이었고
- 쿼리는 St-1, 키는 H였다.
구현된 바다나우 어텐션은 아래와 같다.
import tensorflow as tf
class BahdanauAttention(tf.keras.Model):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = Dense(units)
self.W2 = Dense(units)
self.V = Dense(1)
def call(self, values, query): # 단, key와 value는 같음
# query shape == (batch_size, hidden size)
# hidden_with_time_axis shape == (batch_size, 1, hidden size)
# score 계산을 위해 뒤에서 할 덧셈을 위해서 차원을 변경해줍니다.
hidden_with_time_axis = tf.expand_dims(query, 1)
# score shape == (batch_size, max_length, 1)
# we get 1 at the last axis because we are applying score to self.V
# the shape of the tensor before applying self.V is (batch_size, max_length, units)
score = self.V(tf.nn.tanh(
self.W1(values) + self.W2(hidden_with_time_axis)))
# attention_weights shape == (batch_size, max_length, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
- init 함수에서는 W1, W2, V 가중치 행렬만 가져온다.
- call 함수는 실제로 위의 식을 계산해 attention score 를 계산하기 위한 함수이다.
- W1 가중치와는 value 값(= key)을 곱하고, W2 가중치와는 hidden 값 (=쿼리) 를 곱하고
- 소프트맥스 적용 후
- value 와 다시 곱하면 Context vector 가 된다.
모델 설계
본격적으로 전체 모델 설계에 들어가자!
from tensorflow.keras.layers import Dense, Embedding, Bidirectional, LSTM, Concatenate, Dropout
from tensorflow.keras import Input, Model
from tensorflow.keras import optimizers
import os
sequence_input = Input(shape=(max_len,), dtype='int32')
embedded_sequences = Embedding(vocab_size, 128, input_length=max_len, mask_zero = True)(sequence_input)입력층과 임베딩 층을 선언했다.
- 입력층에선 shape (500, ) 짜리를 받을 것이다. (한 행에 한 단어)
- 임베딩은 입력 단어를 가져와 10,000 단어, 128 차원 벡터에서 임베딩하도록 설계했다.
2개의 층을 쌓을 것이다.
- 첫번째 층을 쌓아보자. 층 2개를 쌓을 것이므로 return_sequence 를 True 로 해주자. 입력은 embedded_sequence
- 두번째 층은 값을 반환받을 것이므로 h, c 정보를 모두 가져온다. return_state = True 로 준다. 입력은 lstm. 순서대로 순방향 LSTM 의 은닉상태와 셀 상태, 역방향 LSTM 의 은닉상태와 셀 상태를 뜻한다.
- lstm 의 경우에는 500 단어를 128 차원으로 표현한다. 순방향이든 역방향이든 은닉상태가 존재!
lstm = Bidirectional(LSTM(64, dropout=0.5, return_sequences = True))(embedded_sequences)
lstm, forward_h, forward_c, backward_h, backward_c = Bidirectional \
(LSTM(64, dropout=0.5, return_sequences=True, return_state=True))(lstm)은닉상태는 은닉상태끼리, 셀 상태는 셀 상태끼리 Concat. (실제로 들어가는 입력은 은닉상태)
state_h = Concatenate()([forward_h, backward_h]) # 은닉 상태
state_c = Concatenate()([forward_c, backward_c]) # 셀 상태
따라서 Attention 모델 전에 들어갈 입력 => 임베딩 => lstm => state_h 추출이 모두 완료가 되었다. 이제 lstm과 stae_h 를 입력으로 주고, context_vector 을 받아오면 된다!
받아온 context_vector 을 가지고 최종 출력층을 한 번 통과시키는 것까지 보자.
attention = BahdanauAttention(64) # 가중치 크기 정의
context_vector, attention_weights = attention(lstm, state_h)
dense1 = Dense(20, activation="relu")(context_vector)
dropout = Dropout(0.5)(dense1)
output = Dense(1, activation="sigmoid")(dropout)
model = Model(inputs=sequence_input, outputs=output)
모델을 컴파일하고, 훈련시키자.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs = 3, batch_size = 256, validation_data=(X_test, y_test), verbose=1)

Mathematics, Algorithm, and IDEA for AI research🦖
좋은 글 감사합니다.