Seq2Seq 은 인코더 디코더를 기반으로 하는 네트웍 모델의 이름이다. 임의의 길이의 입력이 들어오면, 임의의 길이의 출력을 생성하는 네트웍이라 이해하자!
- encoder: 임의 길이 입력을 하나의 벡터 표현으로
- decoder: 하나의 벡터 표현을 가지고 임의 길이 출력으로
하나씩 활용을 알아보자!
1. RNN based Encoder-decoder
1) Encoder-decoder Network Concept
기계번역은 시퀀스를 입력으로 하고 시퀀스를 출력으로 하는 대표적인 예시이므로 이에 적합하다. 예컨대 한국어 문장을 하나의 벡터를 만들고, 벡터를 가지고 영어 문장을 만들어낼 수 있다.
2) document summarization
문서요약 또한 여러 단어가 긴 문장 형태로 들어오고, 짧은 문장으로 출력해주는 것이 필요하므로 사용될 수 있다.
3) Question Answering System
질의응답은 질문을 입력으로 하나의 벡터로 만들고, 하나의 벡터를 가지고 답(answering)을 시퀀스로 출력하는 형태이므로 이에 해당한다 할 수 있다.
++ Statistical Machine Translation
통계 모델 기반의 기계번역이라 하는, 병렬 코퍼스를 기반으로 구축된 통계모델이다. 2016년까지에도 Google Translate, Microsoft Translate 에 사용되었다. (그 후 Neural network으로 전환되긴했다.)

- source 에 대한 시퀀스가 들어왔을 때 target 시퀀스를 구하고자 하는 식이다
- 확률값을 크게 하는 것을 고른다
- 베이지안 이론을 이용해 우변의 식으로 바꾼다.
- 영어, 한국어를 병렬로 줄세운다
- source 의 어떤 언어가 target의 어떤 단어에 해당하는지 alignment (단어단위 매핑)
- alignment 로 확률 p(s|T) 를 구함. (target 이 들어왔을 때 source 의 확률)
- Target 언어에 대한 확률 p(T)를 구함
- 따라서 p(s), p(T), p(S|T) 만으로 P(T|S) 를 구한다.
이를 비례 관계로만 전환하면 P(T)P(S|T) 와 같이 되므로, 정말 좋아 -> really love / really like 를 확정짓기 위해서는 P(really love)P(정말 좋아|really love) 와 P(really like)P(정말 좋아|really like) 를 비교하면 된다.
이때 target 이 등장할 때 source 가 등장할 확률을 비교하는 것 뿐만 아니라 target 자체의 등장확률을 비교하는 이유는 그런 단어 집합(n-gram)이 실제로 쓰이는 지까지 따지는 것이다. 만약 really love 라는 집합보다 reaaly like 가 더 많이, 자연스럽게 쓰인다면 조금 더 확률로써 가중치를 더 주는 식이다.
✅ RNN Encoder-decoder
input-encoder-context-decoder-output 으로 이루어진 구조를 제안한 논문이다.
- Encoder: 입력 시퀀스를 읽기 위한 RNN이다. 입력 시퀀스의 길이는 가변길이인데, 이를 고정된 사이즈의 임베딩으로 변환한다.
- Context: 압축된 정보로써, 항상 같은 크기의 고정된 사이즈 임베딩을 뜻한다.
- Decoder: 출력 시퀀스를 생성하기 위한 RNN으로써, 고정된 임베딩을 받아서 가변길이 아웃풋을 낸다.
추가적으로 Encoder-decoder의 특징으로, encoder 의 가장 마지막 RNN의 hidden state 를 decoder 로 inital hidden state 가 된다는 점, encoder 와 decoder 은 별도의 RNN 구조임을 알아두자.
이를 그림으로 확인하자!
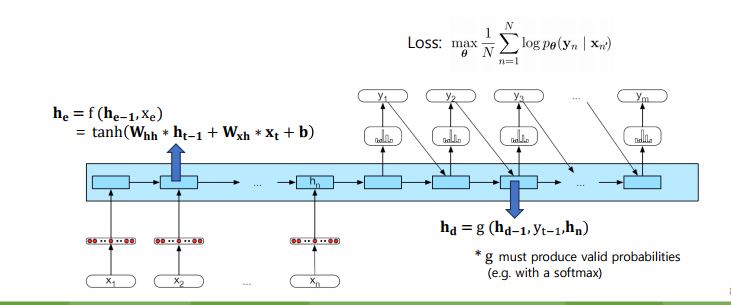
- input: word embedding sequence
- output: 현재 time step 에서 출력 확률이 가장 높은 단어
- Loss: 예측 문장과 실제 정답 문장과의 CE loss 를 매 스텝에서 계산하고, 이를 더해서 단어 시퀀스의 길이 n으로 나눈다.
✅ Seq2Seq
인코더-디코더 구조를 동일하게 하되, LSTM을 사용한 논문이 첫 시작이었다. Seq2Seq 의 contribution 을 보자.
-
eos 토큰을 문장의 끝에서 사용함으로써 문장 길이를 적당한 선에서 끝낼 수 있게되었다.
-
당시 Neural Machine Translation 기반의 번역 중 최고 성능을 기록했다.(end-to-end NMT, BLEU score:34.81)
-
입력 시퀀스를 반대로 뒤집어 사용했다. (I drink milk -> milk drink I 를 입력으로) 따라서 출력을 만들어내는 데 있어서 시작할 때 정보 (I 를 뜻하는 target lg. 로 시작해야 하므로) 를 바로 전 정보 (I로 끝남) 를 잘 가져올 수 있게 하였다.
-
첫 단어를 디코딩할 때 디코딩 하려는 time step 단어와 중요한 단어를 찾아야 한다는 아이디어의 근간이 된 논문이기도 하다. (attention 이 떠오른다.)
🤔 BLEU (Bilingual Evaluation Understudy)
기계 번역에서 자주 사용하는 성능 측정 점수이다. (최근에는 많이 쓰이지 않고 보조적 수단으로 사용한다.)
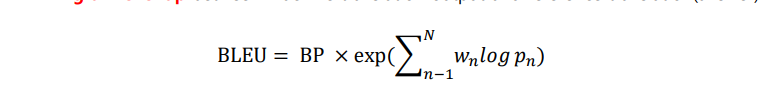
- BP: 후보 번역(예측)의 길이와 정답의 길이 비교. 후보 번역이 더 길때는 1, 참조 코퍼스의 길이가 더 길 땐 e^(1-r/c).
- n-gram 을 가지고 precision.
✅ Limitaitons of RNN Based Encoder-decoder
- On the Properties of Neural Machine Translation: Encoder–Decoder Approaches 논문에서, RNN 기반의 인코더-디코더가 문장 길이가 길어질수록 성능이 떨어지는 것을 확인했다.
- vanishing gradient 문제, LSTM 을 추가하여도 여전히 문제.
- 하나의 context vector 에 입력을 모두 압축하므로 정보 손실 발생 (bottleneck problem) -> 어떤 정보가 더 중요한지 알 수 없다. (attention 이 또 떠오른다)
2. Attention Mechanism
어텐션의 목표는, 예측해야 할 단어와 연관있는 입력 단어에 더 많이 집중하자는 것이다. (기존 RNN의 입력 문장을 단순히 하나의 벡터로 바꾸고 그것만 가지고 예측하는 것과는 차이가 있다.) 이렇게 예측하는 시점에서 입력 단어와의 연관성을 계산함으로써 얻을 수 있는 이점은
- 긴 문장의 번역도 잘 처리할 수 있으며
- 정보가 하나의 고정 값으로 압축되는 encoder-decoder 구조를 개선할 수 있다.
이렇게 Attention 이 나오게 된 근간에는 RNN 의 seq2seq 논문에서 순서를 뒤집어 입력으로 줬을 떄 아이디어를 가져온 것으로 예측해볼 수 있다. 예측을 함에 있어서 입력 단어들을 단순히 줘서는 안된다는 것.
- Neural Machine Translation by Jointly Learning to Align and Translate(Bahdanau D. et al.)
- Effective Approaches to Attention-based Neural Machine Translation(Luong, M.et al.)
두 논문은 비슷한 아이디어를 담고 있는데, 결국 앞에서 이야기 한 것처럼 현재 시점에서 예측해야 할 단어와 연관있는 입력 단어에 집중한 정보를 참고하는 아이디어를 사용한다.
✅ 구조
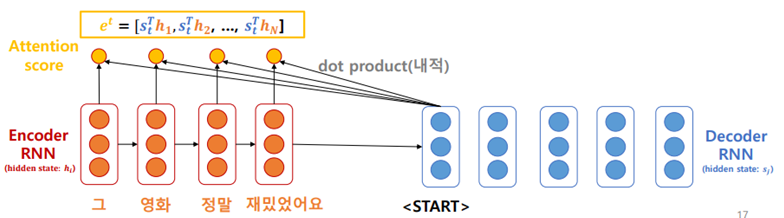
- 인코더 hiddent stage hi, 디코더 hidden state si 으로 표시한다.
- 인코더의 state 들과 디코더의 현재 시점에서의 hidden state 와 각각 내적한다. 이 값이 Attention score: . 결국 Attention score 는 현재 시점에서 예측하려고 하는 단어와 입력 시퀀스의 각 단어와의 연관도 점수이다.
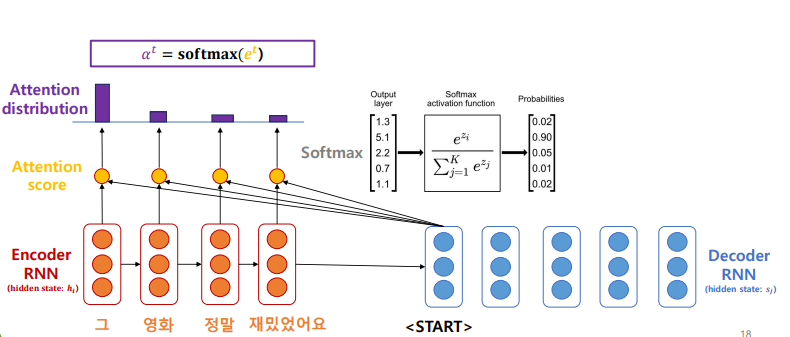
- 해당 attention score 값에 softmax (다 더하면 1)를 취하여 Attention distribution 값을 가져온다. 이 Attention distrubution 은 현재 시점에서 예측을 하려고 할 때 인코더의 어떤 단어에 더 집중할 지 확률적으로 파악한다는 것이다. 이떄 중요한 것은 Attention distribution 은 각 단어의 의미적 정보가 아닌 현재 시점에서 예측하려고 하는 단어와 연관이 있을 확률만 예측한다. 따라서 가중합에 있어서 의미를 다시한번 곱해주는 과정이 필요하다.
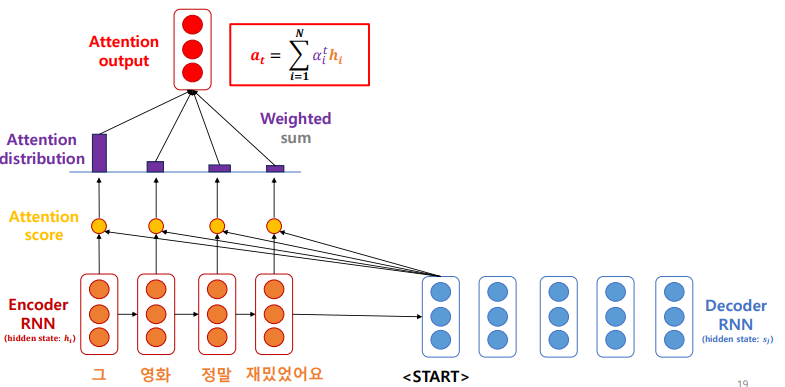
- 가중합을 계산하는데, 가중합을 계산할 때 Attention distribution 에 또다시 Encoder RNN의 입력이 되는, 즉 입력 문장의 임베딩 값을 곱해준다. 이 Attention output은 하나의 context 벡터인데, 그 시점에서만의 context 벡터라 생각하면 된다. 따라서 Attention output 은 입력 시퀀스 각 단어의 의미에 X 예측 시점의 단어와 연관 확률을 곱하므로 의미, 확률 모두 포함한 정보가 된다.
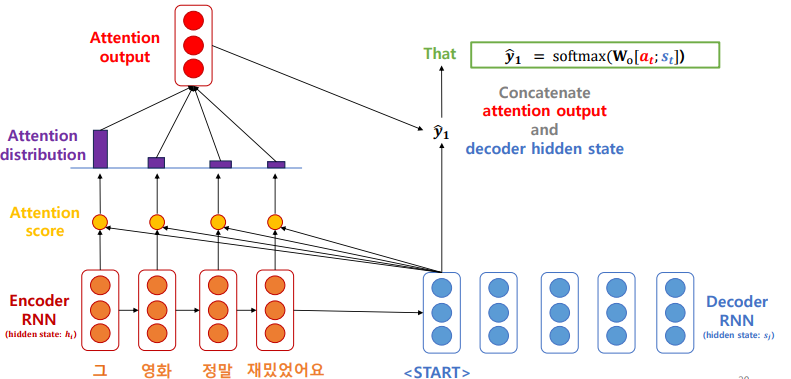
- 이렇게 계산한 attention output 과 decoder hidden state(여기선 sos 토큰일 것이다.) 를 concatenatem 한 후, 가중치를 곱하고, softmax 를 씌워 예측 하나를 만들게 된다.
✅ Results
- NMT 성능을 크게 향상시켰고,
- 긴 문장 처리의 어려움 문제를 해결했다.
- 또한 낮은 Interpretability 문제를 해결했다.
✅ Attention score 계산 Variation

✅ Visual Attention
이미지에 캡션을 다는 문제에서도 사용이 가능하다. 모델의 출력이 어떻게 나온 값인지 이해하기 쉽다?
✅ Implementation
할 일
아래 링크들을 읽어보고, 필요하다면 정리하자.
