
Sequence to Sequence Learning with Neural Networks 논문 리뷰를 해보자. 인코더-디코더 모델에, LSTM 구조를 사용한 기본적인 seqeunce-to-sequence 를 최초로 제안한 논문이다!
Abastract
이 논문에서는 기존 DNN 으로 라벨링된 데이터만 학습시킬 수 있었던 방법론에서 벗어나, end-to-end approach to seqeunce learning that makes minimul assumptions on the sequence structure 를 제시하고 있다.
논문인 시퀀스를 LSTM 으로 매핑하고 / LSTM 을 가지고 벡터에서 시퀀스로 디코딩하는 과정까지 제시한다.
당시 WMT'14 dataset 에서, 번역에 대한 BLEU score 34.8을 달성했다. LSTM이 sensible phrase, sentence representation 을 단어 순서에 따라 더 잘 잡을 수 있으며 따라서 모든 source 문장들을 아예 reversing 해서 input 으로 주는 새로운 방법론을 제시한 논문이기도 하다.
1. Introduction
당시에는 Neural Networks 라는 개념 자체가 새롭게 등장하여 성능을 갈아엎던 시기라, 이에 대한 설명을 하고 있다.
기존의 문제는 DNN이 계산에 있어서 뛰어난 성능과 속도를 보여줌에도 한정된 문제에서만 적용될 수 있다는 것이었다. 고정된 차원이 필요했으며, 인풋과 타겟이 쉽게 벡터로 인코딩 될 수 있는 환경. 따라서 시퀀스 - 길이가 고정되지 않은 - speech recognition, machine translation, Question Answering 등의 문제에서는 적용되지 못하는 상황이었다.
논문에서는 이러한 문제를 LSTM 을 결합하여 인풋 시퀀스를 읽고(다양한 길이의 인풋을 받을 수 있게되었다), 현재 시점을 다음시점으로 계산하는 과정을 반복한 후에야 고정된 차원의 벡터로 변환하는 방법론을 제시했다. 그리고 나서 해당 벡터를 가지고 LSTM이 디코딩하면 된다. (이때 두번째 LSTM의 경우 인풋 시퀀스에 영향을 받는 RNN이어야 한다.)
그럼 왜 하필 LSTM일까?🤔 LSTM은 당시(혹은 여전히) 긴 range 의 데이터에서 temporal dependencies 를 학습할 수 있다고 여겨졌기 때문이다. 따라서 input 와 output 의 시간적 격차 - 이건 neural network 에서 계산의 시점을 말할 것이다 - 를 극복하고 자연스런 선택을 할 수 있도록 도울 것이다.
논문의 main results 는 WMT'14 English to French translation task 에서 기록한 BLEU score 34.81 기록이다.
- ensembles of 5 deep LSTMs
- 384M parameters
- 8,000 dimensional state each
- left-to-right beam search decoder
논문에서는 LSTM이 장기의존성 문제를 피하도록 source 문장의 단어들을 아예 거꾸로 뒤집어 훈련했다. 이렇게 함으로써, 마지막 주어진 정보를 더 잘 기억하고 (실제로는 가장 앞에 오는 단어) 번역할 문장의 첫 단어를 예측할 수 있었다.
2. The model
standard RNN 의 계산을 보자. 시퀀스가 주어질 때 output (y1, ... , yt) 는 다음과 같이 계산한다.
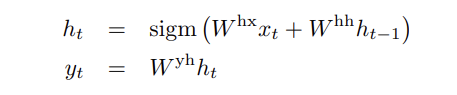
그러나 RNN을 인풋과 아웃풋 길이가 고정되지 않고 가변적으로 변하는 문제에 대해서 어떻게 적용할지는 여전히 미지수였다. 가장 간단한 방법은, 시퀀스 learning 에서도 인풋을 고정된 크기의 벡터로 변환하는 것이다. 그리고 벡터 하나를 가지고 출력하는데, 이 경우에 긴 길이의 시퀀스가 하나의 벡터로 압축되지 않고 정보의 손실이 일어나는 long term dependencies(장기의존성) 문제가 발생했다.
여기에 이 논문은 LSTM(Long Short-Term Memory)라고 하는, long range temporal dependencies 학습이 가능한 셀을 도입한다. LSTM은 (x1,...,xt)가 인풋으로, y1,...,yt 가 대응하는 아웃풋으로 주어질 때 conditional probability 를 추정하는 것이 목표이다. 이때 LSTM이 conditional prob 을 계산할 때 먼저 시퀀스에 대한 고정된 차원의 벡터 v를 얻고 (이는 lSTM의 마지막 hidden state 에서 가져온다) LSTM-LM formulation 을 통해 출력의 확률을 계산한다.
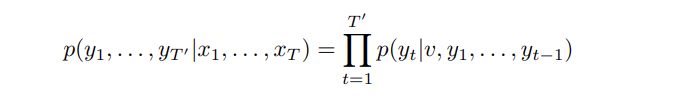
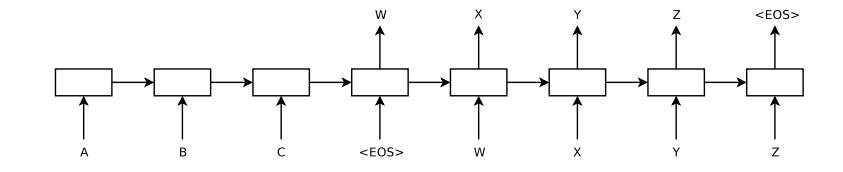
조건부 학률은 우변과 같이 yt 를 계산할 때 v,와 yt-1까지를 보고 softmax 확률들을 곱한 것으로 정리할 수 있다. 여기에 중요하게 필요한 것이 EOS, speical end-of-sentence symbol 이다. EOS 를 추가해야 모델이 가능한 (다양한 길이)를 계산할 수 있을 것이다. 가장 위의 LSTM 사진을 다시 보자. 이때 LSTM은 A, B, C, EOS 의 표현을 계산하고 이것들을 가지고 W, X, Y, Z, EOS 의 확률을 계산한다.
정리하면, 기존의 모델들과 차이점은 다음과 같다.
- 서로 다른 두 LSTMs (number of parameters negligible cost, multiple languages)
- deep LSTM outperformed shallow LSTM, so four LSTM layers
- valuable to reverse the order of the words of the inputs
3. Experiments
메인 실험은 WMT'14 English to French MT taxk 에 대해 이루어졌다.
- Data) train models subset of 12M setences consisting of 348M French, 304M English words
- Architecture) training large deep LSTM on many pairs
- Objective) maximizing the log probability of correct translation T, given source sentence S
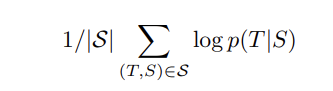
- Inferences) Once training is complete, produce translations by finding the most likely (according to LSTM:)
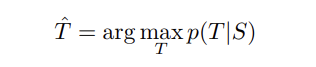
- Internal Code) EOS symbol appended to a hypothesis, removed from the beam and added to the set of complete hypothesis
추가적으로 앞에서도 논의되었던 Reversing the source sentences 에 대해 알아보자. LSTM 자체로도 장기 의존성 문제를 해결했다고 보았지만, 실험을 통해 논문은 LSTM이 source sentece 를 거꾸로 해서 input 으로 줬을 때 더욱 잘 학습했다고 주장한다. (ppl 5.8 -> 4.7 / BLEU scores 25.9 -> 30.6)
논문에선 이러한 결과의 이유로 many short term dependencies to the dataset을 꼽고 있다. 소스와 타겟을 concate 할 때 자연히 소스의 특정 단어들은 타겟의 단어들과 멀어지는 문제가 생기는데 소스문장 자체를 뒤집음으로써 (평균 거리는 변하지 않지만) first few words 에 대해 target lg.와 매우 작은 거리를 유지할 수 있게 된다. 이는 backpropagation 에 있어서 establishing communication 을 쉽게한다. (성능의 향상, better memory utilization)
Results
결과는 다음과 같다.
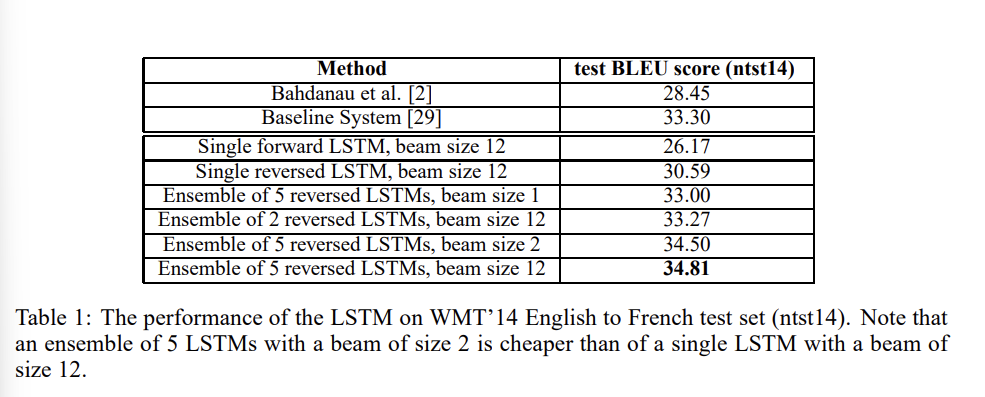
main 실험에서 제시된 바다나우 어텐션보다 점수가 평균적으로 높으며, LSTM을 deep 하게 쌓았을 때가 그렇지 않았을 때보다 점수가 높은 것을 확인할 수 있다.

LSTM ensemble 이 WMT'14 sysytem 의 성능을 뛰어넘지는 못하고 있지만, pure neural translation system 이 phrase-based SMT baseline 을 large scale MT 에서 뛰어넘은 첫 기록이었기에 의미가 있다고 할 수 있다.
Model Analysis
논문의 가장 주요한 성과라 할 수 있는 시퀀스 단어들을 고정된 벡터로 변환하는 능력을 보자. two-dimensional projections by PCA.
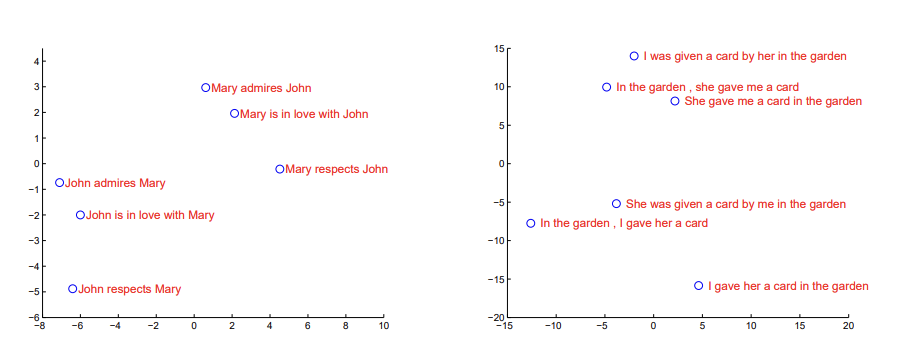
표현 자체가 단어의 순서에 민감하고 / active voice 를 passive voice 로 바꾼 것에는 둔감함을 확인할 수 있다.
