[Paper] Rethinking Interpretability in the Era of Large Language Models
[Natural Language Processing]
[Paper] Rethinking Interpretability in the Era of Large Language Models 논문 리뷰
- 링크: https://arxiv.org/abs/2402.01761
- Reasons for read: rejected by TMLR. While this paper has some critical issues to introduce interpretability in a concise and formal manner, but try to expalin the interpretabilty such an intuitive way, focusing on high-level survey on recent papers.
1. Introduction
Interpretability of LLM 을 이야기 하기 전, Interpretable ML 에 대해서...
- Inherently interpretable models 를 쓰는 방법: sparse linear models, generalized additive models, decision trees (그 자체로 설명이 되는 모델을 쓰거나)
- post-hoc interpretability: 모델이 학습 된 후 설명을 시도하는 것. 여기에는 feature importance, model visualizations, interpretable distilation(⭐) 등이 포함.
Interpret LLM 이 중요해진 이유
- LLM은 이제 복잡하고 다양한 task 를 수행할 수 있음을 계속해서 보여주고 있음.
- 그러나 현재는 이 모델들이 왜 잘하는지를 설명하지 못하며, 이는 이 모델들을 high-stakes application 에 적용하는 것을 꺼리는 이유가 됨. (medicine 등.)
- 또한 regulatory pressure 도 더해지게 되어, safety, alignment 등과 강하게 연결되어 있음. (⭐)
- 따라서 여기서의 목표는 deploy LLM 이 아니라 elicit trustworthy interpretation 임.
LLM hold the opprotunity to rethink interpretability with more ambitious scope.
- 저자들은 동시에 LLM이 interpretability 의 막힌 혈(?) 을 뚫어줄 수 있다고 본 것 같음.
- 가장 중요한 근거로는, LLM이 자연어로 소통이 가능하기 때문.
- interpretable ML 은 saliency maps 처럼 한정된 인터페이스에 머물렀다면 LLM은 직접 그 결과와 결과 산출의 이유 (즉 interpretation 그 자체)에 대해 natural language 로 물어볼 수 있음.
- Can you explain your logic?, Why didn’t
you answer with (A)?, or Explain this data to me., - 그러나 여기서는, hallucinated explanations 을 조심해야 할 필요.
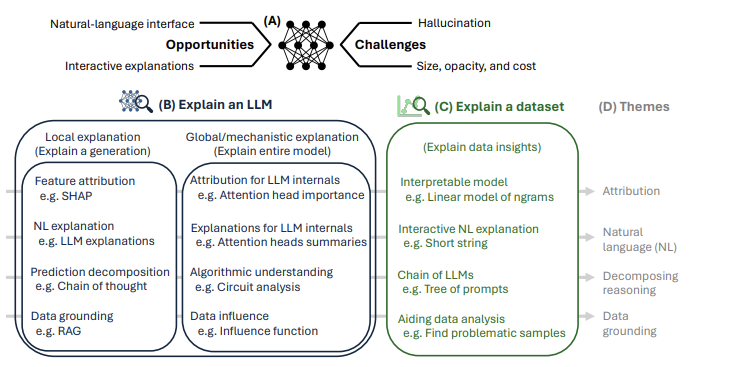
(Categorization of LLM interpreation research)
- 나는 이 카테고리가 꽤 잘 짜여졌다고 생각한다.
- 먼저, Explaining an LLM 의 대분류를 Local explanation (explain a single generation from an LLM) 과 Global/mechanistic explanation (LLM in its entirely) 로 분류한 것. 여기에 데이터셋 설명의 범주를 추가한 것.
- theme 으로 attribution, NL, decomposing reasoning, data grounding 으로 나눈 것이, 그래도 괜찮은 분류라고 본다.
- 그 중에서도 dataset explanation 은, 물론 이 논문이 약간은 용두사미가 된 느낌이 없지않아 있지만, LLM을 활용하여 from science to statistics 를 할 수 있는 방법을 연 것 (faciliate the processs of scientific discovery, data analysis, model building 등.) 에서 의미가 있다고 본다.
2. Background: definitions and evaluation
(Define LLM interpretation)
- "extraction of relevant knowledge from an LLM concerning relationships either contained in data or learned by the model" 이라고 정의.
- 여기서 나는 data 와의 관계에선 LLM '이' data를 설명하는데 쓰이는 방향으로, 'model' 에선 LLM '을' 설명함이라는 방향으로 이해했다.
- 물론 이 논문에서도 'interpreting an LLM'과 'using an LLM to generate explanations' 두 관점을 계속해서 가져가고 있음.
(Evaluating LLM interpretations)
- 해석, 설명에 대한 평가는 그 설명이 'real-world setting with humans'에 얼마나 유용한지를 바탕으로 측정.
- complementarily (LLM의 설명이 human performance -여기서는 효율성이 어울리겠다- 을 얼마나 올려주는 지.)
- faithfulness (자연어 설명이 얼마나 신뢰도가 있는지. 이는 LLM bias 와도 연관이 있다. LLM이 만든 content 에 대해 LLM은 좋게 평가한다는 연구 결과가 이미 있음.)
- improve model performance (그 설명을 썼을 때 자기 자신 성능도 올리면 좋단느 것. 예컨대 few-shot explanations during inference 나, 설명을 통해 overcome specific shortcomings of a model 할 수 있는 현상들.)
특히나 평가에 있어서 1, 2 는 trade-off 와도 같은 것. 마치 확통에서 신뢰구간을 추정할 때 신뢰도가 높은 추정일수록 추정 구간이 길어지는 (넓어지는 것과 유사한 원리다.) 또, 기상청에서 100% 확률로 '내일은 비가 오거나 오지 않거나' 예측하는 것과 같다. 만약 그 설명이 신뢰도가 높을 경우, 이와 대비하여 그 설명이 유용할 가능성이 낮아지는 것.
또 여기서 나는 다음과 같은 생각을 해봤다.
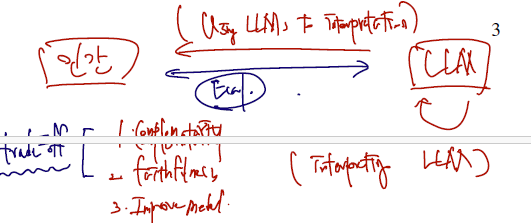
- LLM -> 인간 방향의 화살표는 LLM을 사용하여, 무언가를 해석하는데 사용하는 것이다. (dataset 해석도 여기에 포함, 이미 많은 일들에 쓰고 있으나 퀄리티 발전이 필요.)
- LLM -> LLM (interpreting LLM에 해당하는 부분, LLM을 가지고 LLM을 해석하는데 사용하는 것이며, 적절한 프롬프팅을 통해 왜 그 결과에 이르게 됐는지, 해석/설명해내는 것이다.)
- 반면 평가는 양쪽 화살표 (상호작용, 앞에서 언급한 3가지) 를 통해 함.
3. Unique opportunities and challenges of LLM interpretation
(이전 interpretable ML 필드와 비교했을 때 LLM을 도입할 경우의 기회는 무엇인가?)
- natural language interface (자연히 자연어를 썼을 때 human 과의 bridge 가 견고해진다. DNA, chemical compounds, images 등을 해석하는데 LLM을 갖다쓴다.)
- Interactive explanation (follow-up question 가능)
(그러나 여전히 문제)
- hallucination (LLM 자체가 hallucination 이 있는데, 설명이라고 없을까!/less grounded in evidence)
- immensity and opaqueness of LLMs (LLM을 도입하며 너무 커진 모델 사이즈, 해석이 가능하긴 한가)
4. Explaining an LLM
화살표 중 LLM -> LLM 에 해당하는 화살표다. LLM을 LLM을 해석하는데 쓰는 것. LLM 발전 / Using LLM to interpret 으로 나아가는 수단으로 쓰여야 할 것이며 그러나 매우 중요한 수단이 될 것이다. (여전히 발전이 필요한 분야이기도 하다.) 대분류는, Local vs. Global(mechanistic) Explanation
Local explanation
- explaining a single generation from an LLM (하나의 generated 된 예측에 대해 설명을 시도)
- feature attribution for input tokens (인풋에 대한 고려를 포함. 인풋마다 결과가 달라지기에 local 인 점도 있음.)
- purturbation-based methods, gradient-based methods, linear approximations 등이 여기에 속한다.
- 단순 feature 뿐 아니라 attention mechanism 의 경우 LLM generation 시 각 token contribution 을 시각화할 수도 있고,
- LLM can generate post-hoc attributions of important features through prompting 도 가능.
- feature attribution for input tokens (인풋에 대한 고려를 포함. 인풋마다 결과가 달라지기에 local 인 점도 있음.)
- generate local explanations directly in natural language
- 예측에 대한 이유를 제시하거나, 심지어는 counterfactual scenarios 를 짜기도 하고, uncertainty 에 대한 표시를 하기도 한다. (⭐여기서의 uncertainty 가 단순 예측에 대한 것인지 예측의 설명에 대한 것인지 확인해보고 싶다.)
- generate local explanations directly in natural language
- Chain-of-thought
- 위가 자연어로 된 설명 정도에 그친다면, 적절한 prompting 과 결합되었을 때 (answer-generation 과정에 편입되어) 예측에 대한 좋은 설명을 제시할 수도 있다.
- variant 가 여긴 많다. tree-of-thought 라든지, graph-of-thought 라든지.. (⭐)
- Chain-of-thought
- RAG
- 마지막은 RAG 의 도입인데, 다른 목적보다도 특히나 예측에 대한 설명을 잘 할 수 있다는 관점에서 RAG의 도입이다. RAG에서는, decision making process에서 retrieval step 을 포함하는데, 이때 searching a reference corpus 또는 knowledge base using text embeddings 하는 것이다. 따라서 output 에 대해 도대체 이런 예측을 어떤 source 를 보고 하는지를 쭉 지켜보다보면, 설명의 폭도 넓어질 것이라는 것.
- 내가 느끼기엔, 이건 좀 추상적이다.
- RAG
Global and mechanistic explanation
-
보다 전역적인 서술을 포함. 따라서 개별 output (또는 input)의 원인을 따라가기 보단, 모델이 이러이러 해서, 모델의 보다 넓은 메커니즘이 이러이러 하기 때문에~ 라는 서술을 시도한다.
-
나는 이걸 귀납적인 서술과 반대되는 연역적 서술로 이해했다. input-output 의 증거를 모으기보단, 내부적인 원칙(또는 기능)을 추정하고 이게 모델의 (핵심적인) 작동원리라고 추정하는 것.
-
이런 설명들은 generalization 을 넘어 bias, privacy, safety, build LLMs more efficient/trustworthy 에 대한 것들이 가능해지도록 돕는다.
-
따라서 이들은 mechanistic understanding 을 포함한다.
-
- Probing
- LLM과 관련해서는 attention heads (⭐), embeddings, controllable aspects of representation (⭐) 을 포함한다.
- 특정 위치의 특정 레이어를 가지고 직접 decode 하는 과정 포함.
- Probing
-
- (more granular level) Decoding concepts from individual neurons, or explaining function of attention heads
- 어떻게 각 뉴런들이 조합되는지? (fiding a circuit for multiple purposes ⭐)
- 전체가 아닌 기능들을 localize 시도: localizing factual knowledge within an LLM (⭐)
- localize 한다는 것은, 국소화된 설명을 뜻하는 것은 아니고 모델 전체를 보되 모델 전체에서 국소화된 부분이 특정 기능을 담당한다~ 라는 서술을 시도하는 것.
- (more granular level) Decoding concepts from individual neurons, or explaining function of attention heads
-
- uses miniature LLMs
- 2-layer transformer
- helps identify key components (induction heads or ngram heads) ⭐
- uses miniature LLMs
이렇게 얻어진 인사이트들은 보다 모델을 발전시키는데 쓸 수 있다. 특히 2, 3과 같은 경우 모델의 어떤 부분이 어느 기능을 담당하고, 어느 부분이 더/덜 중요한 지 알 수 있기 때문에 그 동작원리를 알면 simplify 도 가능해진다; model editing / improving instruciton follwing / model compression 과 같은 연구와 맞닿아있다.
(데이터셋은 생략. 만약 이 논문을 소개하게 된다면 돌아올 것.)
관심 논문 리스트 🤗🤗🤗.
[1] (Distill-and-Compare:
Auditing black-box models using transparent model distillation.): interpretable ML 의 고전/기본적인 방법 소개에서, 특히 post-hoc 사후적인 설명 중 distilation 을 사용한 것. 도대체 어떻게 하는지 와닿지 않는다.
[2] (Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs.): 설명에 대한 uncertainty 는 아니었고 output 그 자체에 대한 uncertainty 표현인 것 같긴하다. 그래도 시간 내에 읽어보자.
[3] (Relying on the unreliable: The impact of language models’ reluctance to express uncertainty): 2024 acl, uncertainty 에 관한 논문. 이것도 읽어보자.
[4] (CIRCUIT COMPONENT REUSE ACROSS TASKS IN TRANSFORMER LANGUAGE MODELS): indirect object identification tasks에서 (task 다양화 부족이 있긴하지만) 찾은 circuits 를 확장하려는 시도이고, 각 뉴런들이 어떻게 결합되는지를 서술한 논문이다. ⭐⭐ (어렵다면 Interpretability in the wild: a circuit for indirect object identification in GPT-2 small 이것 먼저 읽을 것!)
[5] (Representation engineering: A top-down approach to AI transparency): meachanistic 접근을 따르기보다 representation transparency 를 주장하며 top-down 으로 해석하기를 주장한 논문. 이 논문도 신선하고 인기가 많기에 읽어볼 가치가 있다. ⭐⭐
[6] (Locating and Editing Factual Associations in GPT): GPT 모델에서 factual knowledge 를 담당하는 곳은 어디인지, 이를 editing 할 수 있을 지 분석한 논문. 인용수도 많다.
