[Paper] Interpretability In The Wild: A Circuit for Indirect Object Identification in GPT-2 Small
[Natural Language Processing]
[Paper] Interpretability In The Wild: A Circuit for Indirect Object Identification in GPT-2 Small 리뷰
- link: https://arxiv.org/pdf/2211.00593
- Reasons for read: Integrate the techniques to finding a circuit with interpretability field, concise hypothesis with some evidence and validate it, what is the crucial and important attention heads to perform specific tasks?
1. Introduction
- Transformer-based language models 는 여러 태스크에서 놀라운 능력을 보여주고 있지만, largely remain black boxes
- Work in mechanistic interpretability: discover, understand, verify the algorithms that model weights implement by reverse engineering model computation into human-understandable components -> forward 가 아닌 reverse engineering 을 통해 각 모델의 가중치가 어떻게 작동하는지, 인간이 알아들을 수 있는 형태들의 요소로 바꾸는 것.
- Circuit analysis 의 처음은 아님; identifying induced subgraph of model's computation that is reponsible for completing the task.
- 그러나 circuit analysis 를 함에 있어 path pathching을 도입한 첫 논문. (output 인 logit 으로부터 이에 중요한 영향을 미친 components 를 알아내기 위해.)
Task 는 다음과 같다.
- Indirect Object Identification: 간접목적어 예측
- "When Mary and John went to the store, John gave a drink to”라는 문장이 있다면 다음 단어는 'Mary'여야 함.
- 언어학적으로 의미있는 태스크이고, 알고리즘적으로 확인할 것이 있다. (한 문장에 2개 이름 등장, 마지막 절의 subject 가 아닌 이름을 선택해야 함.)
결과는 다음과 같다.
- 전체 12 layer에 각 레이어당 12 heads 로 144개 X (token position) 이 head 들이 주어진 문장에서 모두 관여한다고 할 때 26개의 attention heads 만 bulk of this task 라 보았음.
- 이 head 은 서로 다른 name token 을, end position 까지 끌고와서, output 으로 예측하는데 핵심적인 역할.
또한, 적절히 이를 평가하는데 criteria 도입.
- faithfulness: whole model 과 비교했을 때 찾아낸 circuit 이 성능적으로 task 를 수행함에 있어 떨어지지 않는지.
- completeness: the circuit contains all the nodes used to perform the task: 빠뜨린 건 없는 지.
- minimality: the circuit doesn't contain nodes irrelevant to the task: 불필요하게 포함한 건 없는 지.
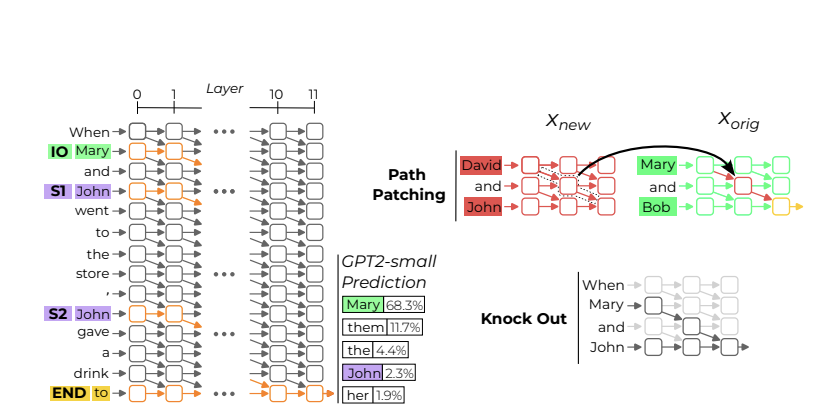
그림을 통해 가볍게 이해해보자.
- GPT-2 small 모델은 전체 12개의 레이어와 12개의 heads 로 이루어져 있는데, 이 중 특정 노드 (여기선 IO와 S, END 토큰이 주인공)에 작용해서 circuit 을 이루는 head 들을 찾아내겠다는 것.
- IOI task 에서 중요한 것은 일단 END 토큰 다음으로 사람이름이 나오도록 하는 것, 그 다음 예측하는 사람이름이 IO일 것. (IO와 S 의 logit difference 가 클수록 좋음)
- 중요한 circuit 을 알아내기 위해 path patching 과 knock out 을 이용. knock out 은 특정 head 를 아예 제거하는 것이고 (주로 circuit 만 두고 나머지를 제거해 validate 한다.), path patching 은 주어지는 input 을 달리해 얻은 attention head 를 가지고 와 갈아끼우는 것이다. (주로 해당 circuit 이 진짜 의미있는 것인지 확인하는데 쓴다.)
2 Background
잠깐 IOI 태스크에 대해 다시 설명해보자.
- 주어지는 문장은 "When Mary and John went to the store, John gave a drink to" 와 같으며, 따라서 initial dependent clause 과 따라오는 main clause 로 이루어진다.
- Initial clause 는 IO Mary 와 Subject 1 John 을 언급하고, main clause 는 subject 2 John 을 언급한다.
- IOI task 는 따라서, 문장의 마지막 토큰 예측이 IO가 되도록 하는 것.
- IO, S1, S2 에 들어가는 각 이름을 달리하여 성능을 측정할 수 있다. 이렇게 이름이 차있는 상태에서 각 문장에 대한 distribution 을 pIOI 라 한다. (여기서 샘플링한 문장 vs. pABC에서 샘플링한 문장을 비교하여 path pathching 하는데 쓸 것.)
- 성능 측정은, Logit difference 과 IO probability로 한다.
- 1.두 개의 이름이 등장하므로, 이들 간의 차이를 계산.- 2.전체 예측 중 IO token 의 예측 확률도 계산.
Transformer architecture 에 대해 약간 되짚어보고 오자.
- Decoder- only Transformer-based 의 GPT-2 small은 12개의 레이어, 각 레이어당 12개의 head 로 이루어져있다.
- Input x0이 들어오면 기본 token embeddings 와 position encoding 을 합하여 N X d 짜리 실수 행렬을 반환한다. N은 x0의 token 수이고, d는 model dimension. 또한 이 값은 residual stream 의 초깃값이기도 하다.
- attention layer i 은 이 값을 인풋으로 받는다 (x0, x1, x2...) = residual stream at layer i 값과 같다.
- 하나의 attention layer output 은 attention heads 의 sum으로 볼 수 있는데, 표시는 hi,j. 로 한다. i번째 레이어의 j번째 head 라는 것.
- 하나의 attention layer 의 output 은 그러면 xi를 인풋으로 받고, hi,j 를 j에 대해 summation 한 값 yi다. 그러면 residual stream 은 xi + yi 로 값을 업데이트하게 된다.
- 각 head 안에서 무엇이 일어나는지 간략히 해보자. 4개의 matrices Q, K, O, V가 있으며, QK matrix 는 attention pattern of head (i,j)를 계산한다. OV matrix 는 residual stream 으로 무엇이 쓰여져야 하는지를 결정한다.
Cicuits and knockouts 에 대해 알아보고 가자. 여기까지의 내용은, 논문에서 새롭게 제시된 것이 아닌 이전의 정의를 소개한다.
(Cirucit C의 definition)
- If we think of a model as computational graph M, where noes are terms (neurons, attention heads, embeddings) and edges are the interacton between those terms (residual connections, attention, projections)
- a circuit C is a subgraph of M responsible for some behavior
(Knockouts의 definition)
- Circuit 을 사용한 개념으로, input x를 model에 집어넣은 것을 M(x)라 표현한다면, circuit C에 대해선 a function C(x) via knockouts 로 표시할 수 있음.
- 이는 knockouts, 즉 전체 모델 M에서 set of nodes K를 제거한 것. (nodes in K를 제거해도 M과 같은 computation 을 할 수 있도록 하는 것이 목표)
- C(x)의 다른 정의로는, "knocking out all nodes in M\C and taking the resulting logit outputs in the modified computational graph."가 있음.
- knockouts 의 구체적 방법으로는 1) zero ablate K (단순 nodes in K를 0으로 채우는 것) 과 2) mean ablation (reference distribution 의 average value로 채우는 것) 이 있음. 이 연구에선 2)를 택했고, 이 distribution 은 pIOI에서 pABC로 바꿔 얻은 distribution 임.
- 바꿔말하면, circuits C를 정하고 나머지 nodes 를 knockout 한다고 했을 때, 이 knockout 들은 pABC로 얻은 (head, token position) 으로 replacing 한다는 것. 따라서 교체된 노드들은 IOI task 를 위해 충분한 정보를 제공하지 않으면서도 random A, B, C에서도 template 은 유지되므로 그 자리에 이름이 들어가야 한다 정도는 인식 가능.
3. Discovering the Circuit
본격적으로 Circuit 을 어떻게 찾는 지 알아보자. 이 글에서는 단순 논문 이해, 즉 어떻게 Circuit 을 찾았는지 방법론을 이해하기도 하면서, 약간은 더 나아간 인사이트, 후속 연구, 기존 연구와 결합한 아이디어 등을 제시할 수 있다.
(약간은 끼워맞춘 느낌이 들긴 하지만) “When Mary and John went to the store, John gave a drink to”. 문장을 보고, 사람이 다음 단어를 예측할 때 어떤 작업들을 수행하는 지 펼쳐보면..
[Human interpretable algorithm suffices to perform the tasks...]
1. Identify all previous names in the sentence (Mary, John, John). -> 문장 내 나타난 모든 이름을 확인하고
2. Remove all names that are duplicated (in the example above: John). -> main clause 에서 반복된 이름을 제거한다
3. Output the remaining name. -> 마지막으로 남은 이름을 output 으로 copy 한다.
논문은 각 세 단계의 작업을 다른 head 가 담당하며, 위의 순서대로 동작하는 head 들을 찾았다고 말한다.
-
Duplicate Token Heads: 문장 내 이미 나타난 토큰에 대해 확인한다. S2 token 에서 활성화되며, S1 token 의 정보를 가지고 오고, 반복된 토큰의 위치 정보와 함께 token duplication 이 발생했음을 알린다.
-
S-Inhibition Heads: END 토큰에서 홀성화되며, S2 토큰 정보를 받고, Name Mover Heads 의 query 를 작성한다. (S1, S2 토큰에 가해지는 attention 을 감소시킨다.)
-
Name Mover Heads: output 직전 이름을 결정하는 head이다. END 토큰에서 활성화되며, 문장 내 모든 이름 정보를 받고, 결정하는 이름을 copy 한다. S-Inhibition Heads 때문에 IO token 의 확률을 S1, S2 token 보다 높게 예측하도록 할 수 있다.
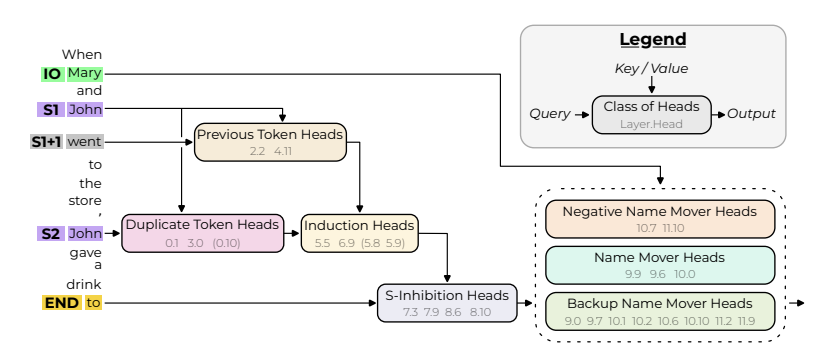
- 오른쪽 위는 head 의 역할을 조사할 때 Query 또는 Key/Value 조사의 차이를 보여준다. Query 는 조사하는 head 에 누가 영향을 미쳤는지를 따라갈 때 사용할 수 있다. Key/Value 는 이 head 가 어떤 stream 으로부터 정보를 읽었는지 조사할 때 사용할 수 있다. (그래서 보통 logit 으로부터 reverse 로 조사한다고 할 때 query 를 사용하면서 뒤로 쫓아가다가 token level 과 가까워지는 시점에선 Key/Value 를 이용한다.)
나아가 더 많은 head 들의 발견이 있었다. (minor classes of heads)
-
Previous Token Heads: token S1의 정보를 S1+1, S2 로 copy 한다. (🤔 약간 애매하긴 한데.. IO token 의 정보는 쓰지 않는 것인가? 아직 그에 대한 이야기는 없다.)
-
Induction Heads: Duplicate Token Heads 와 비슷한 역할을 수행한다. S2 위치에서 활성화되며, S1+1에서의 정보를 가져다 쓴다. S1+1에는 이미 S1 의 정보를 Previous Token Head 가 카피해뒀으므로, S1의 위치정보 뿐 아니라 S가 반복되었다는 사실을 전달할 수 있다.
-
Backup Name Mover Heads: 그야말로 백업 성격의 Heads 들이다. 만약 regular Mover Heads 라고 밝혀진 노드들이 knock out 된다면, 대신 이 역할을 수행하는 것이 실험적으로 밝혀짐.
3.1 Which Heads Directly Affect the Output? (Name Mover Heads)
(Tracing back the Information flow.)
모델의 logits 에 직접적으로 영향을 미친 attention heads h를 알아보자. 보다 직접적인 영향을 알기 위해, 이 연구에선 path pathching 이용.
Path pathching: Xorg과 Xnew 가 있을 때, runs in Xorig에서 측정을 하는데 path는 h와 그에대한 activations 를 Xnew 에서 가져온 것으로 갈아끼우는 것. 이때 path 는 그 경로상의 attention heads, residual connections and MLPs 를 포함한다.
이때, 이 연구에선 찾아낸 Circuit 이 task 에 사용되는 지 검증하기 위해 '있다가 없을 때~' 의 방법론을 취한다. 즉, Xorig from pIOI를 통해 runs 를 main 으로 하되, Xnew 는 pABC 이름에 대한 정보가 없을 때의 경로들로 다 갈아끼운다음 성능을 측정한다. 만약, 그 경로가 중요한 경로 (attention heads)라고 한다면 IOI task 를 수행함에 있어 pABC가 중요한 정보를 삭제했으므로 large drop in logit difference 를 보일 것이다.
Logits 모델의 말단에 해당하는 정보에 대해 한 칸 후진 하기 위해 END position 에서 h -> Logits 로 향하는 경로에 해당하는 heads를 pathcing 하는 실험을 했다. 구체적으로 9.6, 9.9, 10.0 을 교체했을 때 large drop 을 보였으며, 10.7, 11.10 은 반대로 large increase 를 보였다.
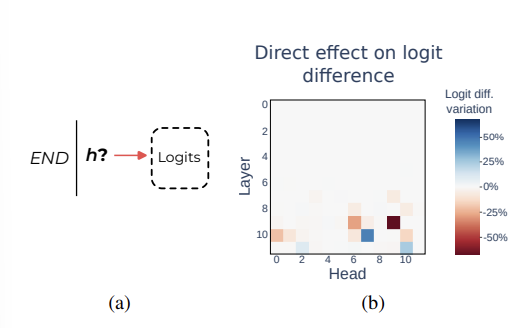
Name Mover Heads
이 헤드의 역할을 1) 올바른 이름으로부터 정보를 가져오고 2) copy 한다고 가정하고, 이를 verify 했다.
Wu를 unembedding matrix 라고 하고, 이에 W[IO], W[S] 등을 vectors 로 얻는다고 해보자. 그리고 나서, attention probability on Name 과 이것이 높고 낮게 변화할 때 head output along W[IO], W[S] 의 projection 이 어떻게 변화하는지 살펴보자.
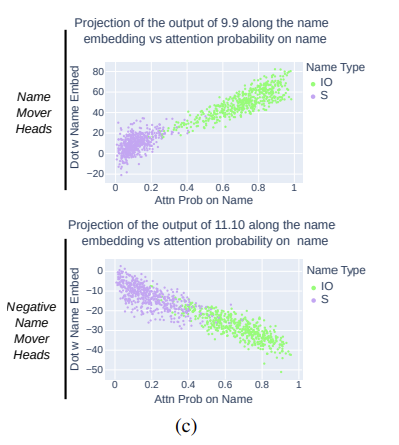
결과는 각각 다음과 같다. IO와 S token 에 대한 attention probability 가높음은, higher output in the direction of the name 과 correlated 되어 있다. (attention 이 높을 때->두 벡터가 가깝게 정렬되어 있는 h(x)와 W[IO]와 연관, attention 이 낮을 때->두 벡터가 다르게 정렬되어 있는 h(x)와 W[S]와 연관) 따라서, h(x)에 어떤 인풋을 넣으면 그 값은 최대한 IO output 을 writing 하려고 하며, 이는 attention probabilty 가 증가함에 따라 더욱 그러함을 보여준다고 이해할 수 있다.
3.2 Which Heads Affect the Name Mover Head's attention? (S-Inhibition Heads)
다음으로 논문은 이 Name Mover Heads 에 누가 영향을 미쳤는지를 알기 위해 각 head, QKV를 모두 조사했는데, query vector + END position에 집중하기로 결정 (아마 다른 head 로부터 정보를 query 로 한 번 더 가져오고, IO에 대한 직접적인 정보는 Key, Value 로 부터 받는다고 가정한 것 같다). END position 이 주어졌을 때, h -> Name Mover Heads 를 patch 하여 logit difference 를 측정.
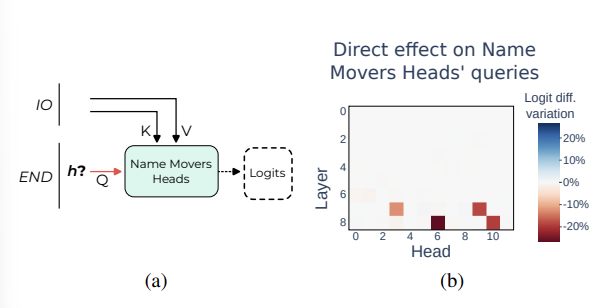
이때의 그림을 잘 보면, Name Mover Heads 를 layer 9부터 찾아냈었기 때문에 이번엔 9 이상 layer는 아예 제외한 것을 확인할 수 있고, 7.3, 7.9, 8.6, 8.10이 directly 하게 영향을 미쳤음을 알 수 있다.
조금 더 잘 이해하기 위해 여기서 포함된 head 들이 patching (pIOI에서 pABC의 head 정보로) 되었을 때 어떻게 변하는 지 그래프로 나타낸 것이 있다.
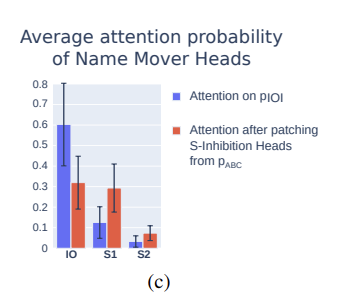
- patching 이후 IO에 해당하는 attention 은 매우 줄고, S1, S2에 해당하는 attention 은 굉장히 증가함을 확인할 수 있다.
- 따라서 S-Inhibition heads 는 정확히 같은 동작, S의 예측 확률을 낮추는 역할을 한다고 볼 수 있음.
- 다른 수치 실험을 종합하면, S-Inhibition heads 는 END부터 S2 token 까지 0.51의 avg.attention 으로 attend 하며, 구체적으로는 token signal (token S value) + position signal (position of the S1 token) 을 이미 가지고 있는 것으로 나타남.
- 이는... S1 위치+값 정보를 전달하는 previos token heads, 이를 copy 하고 duplicate 되었음을 알리는 Induction heads 로부터 얻은 정보로 보인다.
3.3 Which Heads Affect S-Inhibition Values?
- S-Inhibition Heads 에 어떤 정보가 영향을 미쳤는지 알아보기 위해 quries, keys, values 각각에 대해 path patching 을 했고, 이번엔 그 중에서도 values 가 가장 중요함을 알아냄.
- 이번엔 head와 head 를 연결하는 quries 로써가 아닌 token 정보를 직접적으로 받고 이를 head 가 읽는 형태일 것이기 때문이라고 생각이 가능하다.
- formal 하게 표현하면, h -> S-Inhibition Heads' values 에 해당하는 경로를 path patching 함.
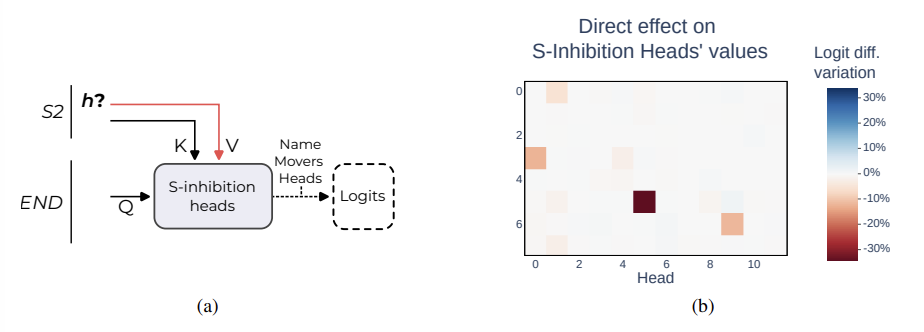
4가지 중요한 head 들이 발견되었는데, S2부터 S1까지 정보를 살피는 부류와, S2부터 S1+1까자 살피는 부류가 있었음.
Duplicate Token Heads
- S2부터 S1까지 attend.
- 이 head 의 역할은 S1으로 가 정보를 읽은 다음 이 정보를 S2까지 copy 해오는 것, 반복이 일어났음 전달. (attention patterns 을 분석함.)
Induction Heads and Previous Token Heads
- S2부터 S1+1까지 attend
- Induction Heads 는 ABBA 패턴을 인식하고 (정보 종합; B는 반복이 일어났고, A는 이전에 등장.), B를 예측하는데 도움.
- Previous Token Heads 는 [A][B] [B][A] 구조가 반복될 때, residual stream B에 A에 관련한 정보를 write 할 수 있음.
이때 Locating the position signal 하는 것은 Duplicate Token Heads 와 Induction Heads 임이 드러남. path patching 방법을 적용할 때 다른 위치의 문장으로 얻은 두 head information 으로 갈아끼우면, logit difference 에 large drop 이 있었음. 그런데 단순 S1, S2 를 다른 이름으로 교체하는 데이터셋으로 replacing 했을 경우는 drop 이 없었음.
3.4 Did we miss anything? The Story of the Backup Moveres Heads
- 문제는 가장 핵심으로 알려진 Name Mover Heads 를 한 번에 knock out 해도, 5%의 logit difference 차이밖에 보이지 않았다는 것.
- 이후 같은 방법을 반복해 logit 에 영향을 준 새로운 heads 를 다시 찾아냄.
- 이때 8개의 heads 를 찾아냈으며, 이를 Backup Name Mover Heads 라 이름 붙임.
- 이를 저자들은 dropout during traning 으로부터 일어난 보상효과라 봤지만. (dropout 자체가 훈련 중 노드 몇개를 랜덤으로 제외하고 훈련하고, 반복하다보니)
생각.
- 이 부분에서 이상함을 감지한 듯 하다. 아무리 그래도 마지막 logit 에 영향을 미치는 heads 를 다 제거했는데 왜 성능이 유지되지..? 하면서, 이를 future work 로 남겨두었다. (if such compensation effects can be observed beyond our special case)
- 의심이 드는 건, 저자들이 과연 이 Circuit 을 통째로 제거하는 실험은 안해봤을까..? 그때 결과가 비슷하게 유지되어 finding circuit 이 의미없는 것으로 돌아갈까봐, 숨긴 것이 아닐까 했는데
- 그런데 아래 minimality 결과를 보니 그건 아닌 것 같다. Duplicate 만 제거해도, 30% 이상 drop 이 일어나고..
- 그러면 제시할 수 있는 건 말단에서 Name Mover Heads 보다 오히려 초장의 neurons/heads 들이 제대로 일을 안한다면 해당 tasks 를 시작조차 할 수 없어서 성능상 drop 이 일어난다는 것.
- compensation effects 와 관련해서 생각해볼 수 있는 건..
- 보상작용으로 나타난 '다음 번 일하는 노드들' 을 반복해서 제거하고 run 하면 어떻게 될까?- 지금 드는 생각으론, 해당 태스크를 수행하기 위해 더 많은 head 들이 가담되어야 할 것이고, 그렇게 많은 사람이 일을 해도 성능상 drop 은 계속해서 일어날 것이다.
- 이걸 반복하면 첫 번째 일하는 노드들, 두 번째 일하는 노드들, 세 번째 일하는 노드들.. 해서 특정 task 에 대해 (부지런히 일하는 노드들 <------> 게으른 노드들) 을 몇 가지 층위로 정의할 수 있을 것이다. (피라미드처럼!)
- 학습상 가장 그 task 를 수행하기 적절한 (layer, heads 번호를 모은 다음,) dataset 으로 분리하여 학습시키고, head 를 각각 뗴어오면 무슨 일이 일어날까? 또는 compression 방법으로 사용하면 어떨까 하는데, compression 쪽은 이미 있을 것 같다.
- 또는 pIOI와 pABC의 템플릿을 다양화하는 건 어떨까.. 지금은 너무 단순하다.

