[Paper] Representation Engineering: A Top-Down Approach to AI Transparency
[Natural Language Processing]
[Paper] Representation Engineering: A Top-Down Approach to AI Transparency
- Link: https://arxiv.org/pdf/2310.01405
- Reason for read: Top-Down Approach to Interpretability of AI / RepE paper / throwing important questions: human brains and neural networks performing is just consist of bumbping information from neuron to neuron, or more than that?
1. Introduction
- RepE places representation at the center of analysis, monitoring and manipulating high-level cognitive phenomena in deep neural networks
The approaches to increasing the transparency of AI system
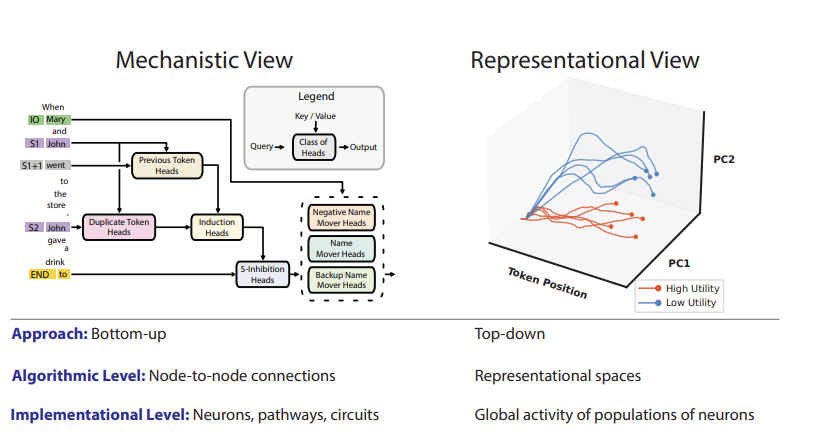
- 1) mechanistic interpretability
- understanding neural networks in temrs of neurons and circuits- Sherringtonian view in cognitive mechanisms
- 2) Hopfieldian view
- higher-level cognition- sees cognition as product of representational spaces, implemented by patterns of activity aross populations of neurons
이와 관련한 관점들...
- "More is Different". Nobel Laureate P. W. Anderson
- 복잡한 시스템이나 현상들은 bottom-up으로 설명될 없다는 것.
- 대신, top-down 으로 접근하며, 설명에 적절한 unit 을 선택해서 generalizable rules 를 최대한 high-level에서 추출하는 것.
- 따라서 mechanistic interpretability 나 Sherrington view 는 뉴런이나 그들의 연결의 주요 연구 유닛으로 삼고, 이들을 분석하면 전체 인지 작용을 알 수 있다고 주장.
- Hopfieldian view 는 representations 을 주요 연구 단위로 삼고 이러한 방법이 high-level cognition within AI system 을 이해하고, control 할 수있는 방법이라 본다.
그 와중 이 논문이 주장한 representation engineering (RepE)는 top-down transparency 를 따르는 것이며, Hopfieldian view 의 철학을 본받은 것이다. 구체적으로
- reading and controling representation 의 더 나은 방법을 소개했고
- RepE techniques 가 매우 다양한 safety-relevant 문제들을 해결할 수 있음을 보였다. (truthfulness, honesty, hallucination, utility estimation, knowledge editing, jailbreaking, memorization, tracking emotional states, and avoiding power-seeking tendencies)
2. Related Work
(2.1 Emgergent Structure in Representations)
이 단락에선 representation 을 통한 해석 가능성의 증거들을 제시하고 있다.
- learned text embeddings 가 특정 개념을 explicitly 하게 가르친 것이 아님에도 commonsense morality 를 따라 cluster 되는 경향.
- 예컨대, reviews data 에 대해 simply by training to predict next token 하면, sentiment-tracking neurons 가 emerged 된다고 확인.
- 그렇다면 다른 safety-relevant concepts 들도 이를 통해 확인하고, 처리하면 어떨까? -> monitor and control these aspects of model cognition via RepE
(2.2 Approaches to Interpretability)
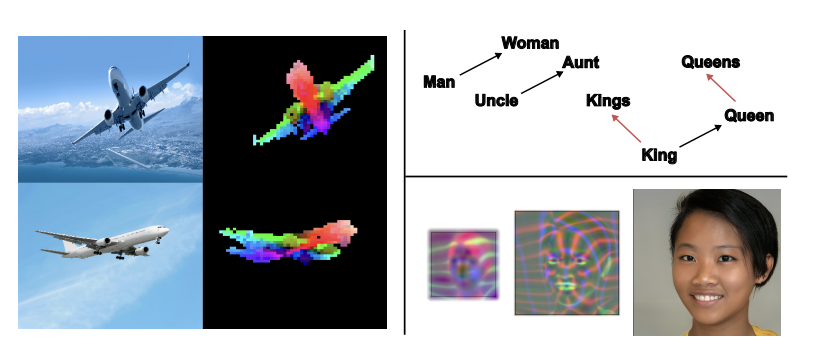
- Saliency maps: 모델이 어느 영역에 집중하는지를 시각화하여 만든 maps 이다.
- Feature Visualizations: representative input 들에 대해 모델의 서로 각기 다른 feature 에서 어떤 서로 다른 정보를 capture 하는지 시각화한 것이다.
- Mechanistic Interpretability: 앞의 두 접근과는 다른 접근으로, reverse-engineering 에 영향을 받은 것이다. circuits 를 찾고, node-to-node connections between neurons or features 를 설명한다.
3 Representation Engineering
RepE의 큰 두가지 카테고리는, Reading 과 Control 이다.
Representation Reading
-
Representation reading 은 network 상에 high-level concepts 오 functions 의 위치를 찾는 것이다. 예컨대 concepts 는, 이 논문에선 truthfulness, utility, probability, morality, and
emotion 관련 개념을 찾길 시도하고 있다. -
분석의 tool 로 제시한 방법은 Linear Artificial Tomography (LAT)이며, 어렵지 않게 이해할 수 있다. 세가지 steps 으로 이루어진다.
Step1: Designing Stimulus and Task
-
Stimulus and tasks 는 distinct neural activity for the concept and function 을 추출하기 위해 짜여진다.
-
적절한 stimulus 와 task 를 설정하는 것은 Representation reading 에 매우 중요.
-
Capture concepts 를 위한 template 은 다음과 같다.

-
단 template 에서 label 된 데이터는 포함하지 않고 unsupervised setup 을 유지함.
-
Fucntions 을 포착하기 위한 템플릿은 살짝 다른데, experimental tasks (궁금한 tasks, 그 function 이 반드시 필요한) 와 reference tasks (반대되는, 그 function 이 필요가 없는 tasks)로 상반되게 구성. 따라서 다음과 같다.

Step2: Collecting Neural Activity
- 앞서 소개한 template 이 주어졌을 때 모델이 어떤 neural activity 를 활성화시키는 지 관찰하기 위한, 추출.
- Transformer-based 모델에 집중. 이 모델들은 MLM objective 나 Next Token Prediction 을 사용하기 때문에..
- Collecting neural activity 하기에 가장 좋은 토큰은 step 1의 concept template에선 concept임.
- 만약 truthfulness 처럼 3가지로 쪼개지는 형태라면 truth 와 같이 중심 단어의 token representation 을 추출하거나 / mean representation 추출.
- 또는, decoder model 을 많이 사용하는데 이때는, 가장 마지막 토큰으로 추출. 따라서 formal 하게 표현하면 다음과 같다.
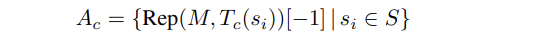
- Function 의 경우에 Activity+와 -가 있다. 각각 experimental and reference sets 에 대응되는 것인데, 이 역시 qestion-answer 데이터셋을 스캔하면서 가장 마지막 토큰을 가져오는 것으로.
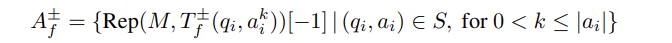
Step3: Constructing a Linear Model
- 이제 represenation 을 얻었으니 개념 또는 함수를 적절하게 반영하는 방향을 찾아야 함.
- 이때 선택한 방법으론 Unsupervised linear model 중 하나인 Principal Component Analysis (PCA) 를 사용하는 방법.
- 차의 벡터에 PCA를 적용하는 것이 효과적. (stimuli in each pair 가 유사도를 보일 경우...)
