[Paper] Relying on the Unreliable: The Impact of Language Model's Reluctance to Express Uncertainty
[Natural Language Processing]
[Paper] Relying on the Unreliable: The Impact of Language Model's Reluctance to Express Uncertainty 리뷰
-
Reason to read: What is uncertainty in LLM? / How can it be expressed and evaluated? (measured.) / What is the idea of mitigating problems relating uncertainty notions
본 논문은 여러 LLM들을 가지고 Qeustion-answering 등의 태스크에서 모델이 얼마나 답변시에 uncertainty 를 표현하는지, 이에 대해 investigate 한 논문이다. 결론부터 말하자면 본 논문은 LLM이 'reluctant to express uncertainties when answering question even when they produce incorrect response', 심지어는 틀린 답을 내놓을 때도 uncertainties 를 표현하기 꺼려했다고한다. 그리고 이에 대한 원인을 찾기 위해 post training 시에 사용된 데이터셋을 조사하고, 'human are biased against text with uncertainty' 를 밝혀냈다. 인간과 데이터가 biased 되었으니 이를 통한 training 과정에서 모델도 그런 경향을 따르는 것이란 결론. 자세히 보자.
1. Intro
- 시간이 지날수록 reliable human-AI interaction 의 중요성이 대두되고 있고, 여기서 중요하게 논의되어야 할 게 model uncertainties 임.
- 이전 몇가지 논문들에선 uncertainty, 혹은 모델의 확신 정도를 모델의 예측에 할당된 prob. 이라 보았음.
- 그런데 LLM이 등장하고, 모델에게 예측 확신도를 직접 질의하고 들을 수 있게 되면서 오히려 lingustics 접근이 좋지 않을까? 생각하게 됨.
- confidence 를 전달하는 feature 를 언어학 개념에선 epistemic markers 라 함.
- epistemic markers 는 뭐냐?: 화자의 스탠스나 믿음의 정도를 표시함으로써 담화상황이나 의사결정에 기여하는 언어학적 요소.
따라서 본 연구는, 어떻게 LMs (LLM도 포함이지만 파라미터가 작은 모델까지도 비교.) 가 uncertainties 를 표현하는지 조사했다. 이는 multiple choice questions 상황에서 epistemic markers 도 같이 달라고 프롬프트로 요청함으로써 가능했으며..
다른 섹션에서 model 의 overconfidence 가 어디서 왔는지 조사했다. 이는 base model, instruction-tuned model, reward model 로 각 모델의 특성을 다르게 해 비교했는데, 결과적으로 여기에 RLHF 가 큰 영향을 미친 요인으로 분석됨. -> human annotators are biased against expressions of uncertainty!
2. Epistemic Markers in LMs
언어학의 개념에서 화자의 스탠스를 표시하는 개념으로 epistemic markers 가 있는데, 이들은 다음으로 구성된다.
- weakeners; expression of uncertainty
- strengtheners; expression of certainty
기존 머신러닝에서 관련한 접근으론 model calibation 을 계산하는 방법이 있었다. ECE 라 불리는 것으로, 모델에 의해 부여된 confidence value 와 함께 model accuracy 를 향상 시키는 것.
최근에서는 조금 더 comprehensive understanding of how humans interpret LM-generated verbal epistemic markers 에 대한 논의가 있고, 이 논문도 역시나 이에 맞게
- 모델에게 predifined set of confidence expression 를 생성하도록 prompts 를 주거나
- qualitative 으로 how LMs generate epistemic markers 를 생성하는지를 평가했다.
How do LMs use Epistemic Markers?
이 질문에 답하기 위해 GPT, LLaMA-2, Claude 모델이 얼마나 uncertainties 를 표현하는지 QA contex 에서 조사했다.
- Multitask Language Understanding benchmark (MMLU) 에서 qeustions 를 얻고, 4개의 multiple choice, 57 subjects 로 구성. 그리고 여기에
- base template from original MMLU 뿐 아니라
- 1) epistemic markers “Please answer the question and provide your certainty level” (EpiM)
- 2) chain-of-thought reasoning (CoT), “Explain your thought process step by step”
- 3) a combination of both “Using expressions of uncertainty, explain your thought process step by step” (EpiM+CoT)
의 3가지 프롬프트를 추가로 구성. 아래 figure 는 1) EpiM 만 한 경우.
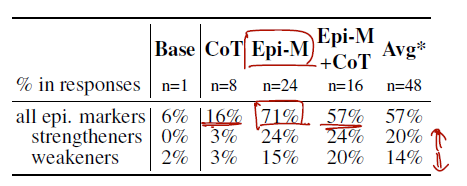
결과는 이와 같다. 프롬프트를 주고 각 답변에, epi.markers 가 포함된 비율, strengtheners 또는 weakners 가 포함된 비율을 분석했다.
fidings 는 다음과 같다.
- Models are reluctant to reveal uncertainties, but can be encouraged.
모델은 uncertainties 를 표현하는 것을 꺼려한다는 것이다. 표에서도 epistemic markers 에 대한 prompt 가 없으면 이에 대한 비율이 현저히 낮고, CoT 에서 혹시 markers 를 넣어주지 않을까 기대했지만 낮았다. 이런 markers 가 없는 문장을 plain statements 라 하자.
- Models are biased towards using strengtheners
9개 중 6개의 모델에서 strengtheners 를 weakeners 보다 많이 썼다. 아래의 그림을 보면..
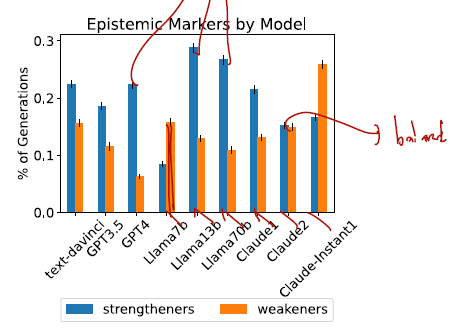
흥미롭게도 모델이 작을 수록 weakeners 를 사용하는 비율이 높았다.
- Overconfidence results in confident but inaccurate generations.
certaintiy 표시된 답변 중 53%만이 실제로 참이었고, weakners 가 표시된 것들은 32% 로 실제로 참이었다. 실제로 틀린 답변 중 17% 는 strengtheners 를 포함하고 있었다.
결론: models struggle to appropriately use epistemic markers
모델은 uncertainties 를 표현하기 꺼려하고, 오히려 certaintiy 에 대한 overuse 가 있다. 이런 문제는 existing problems of human overeliance on AI prediction 문제를 가중시킬 수 있음.
Where Does LM overconfidence Begin? (Origin of Model Overconfidence)
이를 알아보기 위해 base model, supervised fine-tune (SFT) 모델, RLHF 모델을 비교.
같음 모델 아키텍쳐에 대해 davinci (base), text-davinci-002 (SFT), text-davinci-003 (RLHF) 모델을 비교. LLaMa-2 (base) vs. LLaMA-2 Chat (SFT+RLHF)
결과는 아래와 같다.
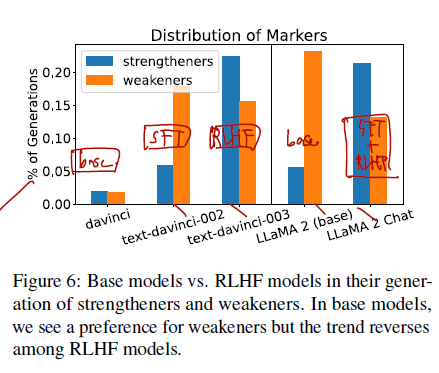
- Overconficne in RLHF Models
- preference for strengtheners is introduced during RLHF process
- Reward Modeling is Biased towards certainty
다른 실험도 하나 더 했다. reward model 을 훈련하기 위한 데이터셋을 가져다놓고, (OpenAI’s “WebGPT comparison” and “Summarize with Feedback”, Dahoa’s “Synthetic Instruct GPT Pairwise” dataset, and Anthropic’s “Helpful and Harmless” dataset) human annotators 들에게 이 데이터셋에 담긴 문장 중 어떤 것이 더 선호되는지 테스트. (문장들은 strengtheners and weakners 포함.)
결론은 Human Raters are biased against uncertainty. 였음.
- plain test slightly preferred over strengthened texts (chosen 9% more)
- Weakeners are preferred 8% less than strengtheners and 9% less than plain texts.
- 따라서 weakeners 들이 가장 덜 선호됨. 이 human annotators 들의 biasedness 가 reward model 에 영향을 미친 것으로 분석..
