Pyspark란?
: Pyspark는 Python 환경에서 Apache Spark를 사용할 수 있는 인터페이스
-> 즉, Pyspark는 Spark용 API
1.Pyspark 환경 셋팅하기
!apt-get install openjdk-8-jdk-headless #jdk install
!wget -q http://archive.apache.org/dist/spark/spark-3.0.0/spark-3.0.0-bin-hadoop3.2.tgz #spark file
!tar -xf spark-3.0.0-bin-hadoop3.2.tgz
!pip install findspark
!pip install kaggle --upgrade사용된 명령어 알아보기
- apt-get : 시스템에서 사용 가능한 패키지에 대한 설치, 패키지 검색, 업데이트 및 기타 여러 작업을 수행
- wget : 웹 상의 파일을 다운로드 받을 때 사용하는 명령어
- tar : 여러 개의 파일을 하나의 파일로 묶거나 풀 때 사용하는 명령어
- pip : 파이썬에서 외부 라이브러리(패키지)를 설치, 업그레이드, 제거, 검색 등의 작업을 수행
환경변수 설정
import os #운영체제와의 상호작용을 돕는 다양한 기능을 제공하는 모듈
import findspark
#환경변수에 path 지정
os.environ['JAVA_HOME'] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ['SPARK_HOME'] = '/content/spark-3.0.0-bin-hadoop3.2'
findspark.init() #spark의 경우 잘 찾지 못하는 경우가 있어 findspark를 이용2.Pyspark 시작하기
from pyspark.sql import SparkSession
spark = (
SparkSession
.builder
.appName('pyspark_test')
.master('local[*]')
.getOrCreate()
)지금 만들어진 spark 객체의 설정을 알아볼까요?
spark.sparkContext.getConf().getAll()
[('spark.app.name', 'pyspark_test'),
('spark.rdd.compress', 'True'),
('spark.serializer.objectStreamReset', '100'),
('spark.master', 'local[*]'),
('spark.submit.pyFiles', ''),
('spark.executor.id', 'driver'),
('spark.submit.deployMode', 'client'),
('spark.driver.host', '61cf6b137952'),
('spark.app.id', 'local-1706412609656'),
('spark.driver.port', '40211'),
('spark.ui.showConsoleProgress', 'true')]
3.Kaggle api 연결 + 데이터 다운로드
- kaggle에 접속한 다음, Account 항목을 클릭합니다.
- 화면을 내려 API탭으로 들어갑니다
- Creat New API Token을 누르고 다운 Kaggle.json파일을 다운로드
- 주의
- 이전의 것은 알려주지 않기 때문에, 이미 발급받고 잊어버렸다면, Expire API TOKEN 후 새로운 TOKEN 발급받기
# 받아온 file을 colab에 올려줍니다
from google.colab import files
files.upload()
!mkdir -p ~/.kaggle/ # kaggle폴더 생성
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download -d wethanielaw/iowa-liquor-sales-20230401
!unzip iowa-liquor-sales-20230401.zip사용된 명령어 알아보기
- mkdir : 디렉토리(폴더) 생성 명력어
- cp : 파일 복사/이동 명령어
- chmod : 기존 파일 또는 디렉토리에 대한 접근권한 변경
- 600 : 나에게만 읽기, 쓰기 권한
- unzip : zip으로 압축된 파일을 푸는 명령어
4.spark dataframe으로 읽어오기
df = spark.read.csv(
path = 'Iowa_Liquor_Sales.csv', header = True, inferSchema = True
)- csv포멧 말고도 json, parquet, avro,jdbc 등 다양한 파일 형식 읽기를 지원함
- header : 열 이름이 데이터 내에 포함되어있으면 True
- inferschema : 스키마 자동 생성 (= True)
df.show()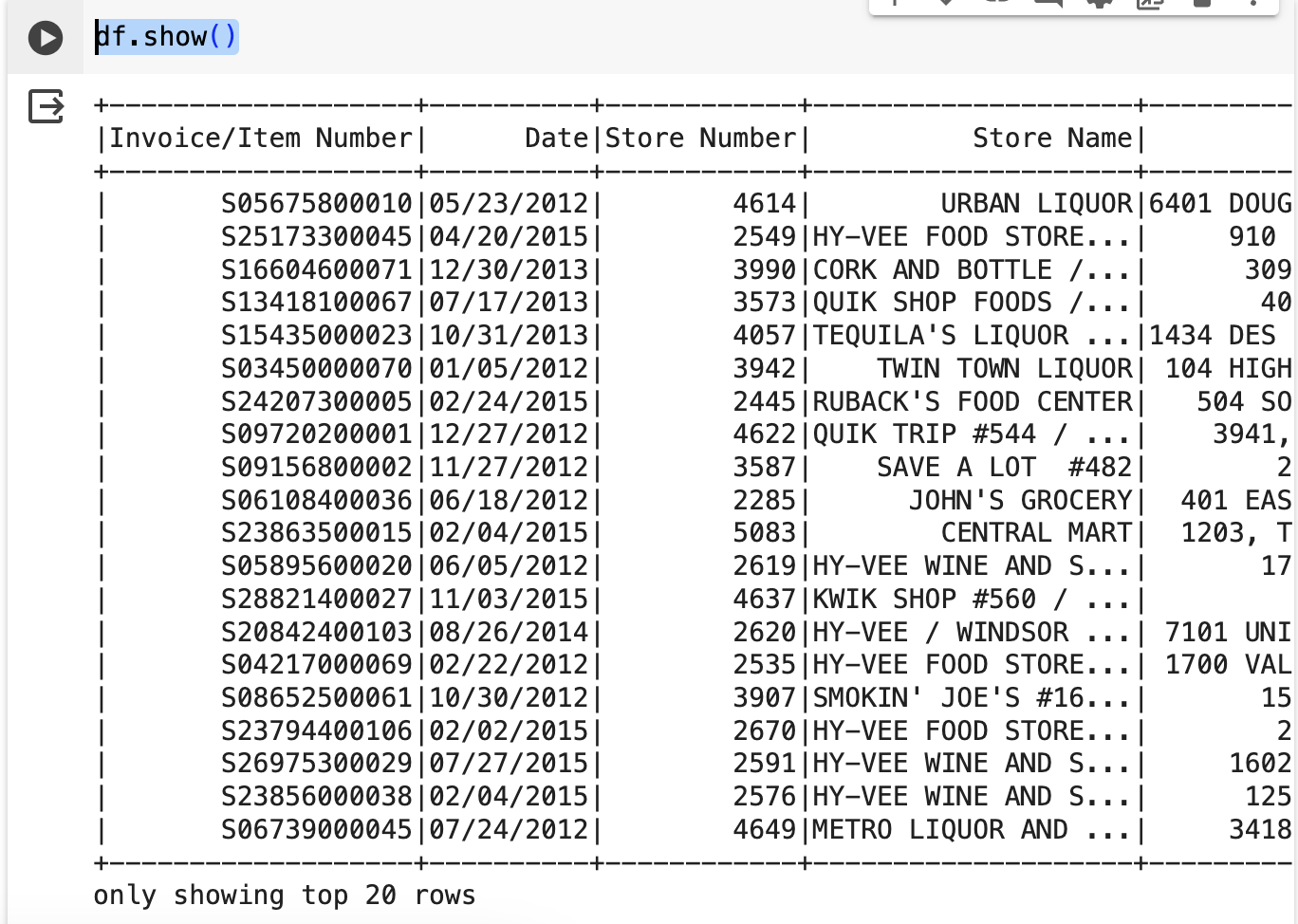
df.printSchema()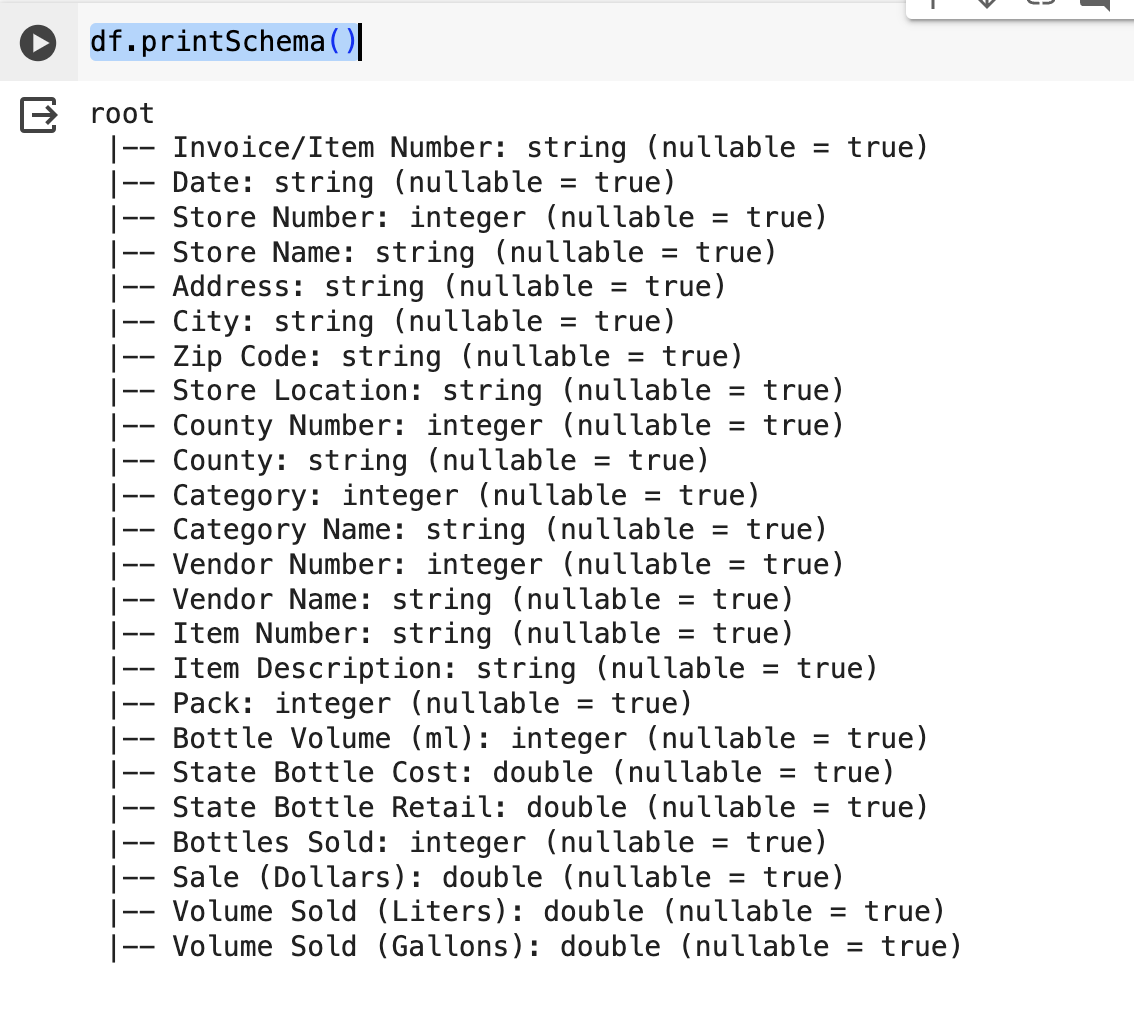
5. 파일 저장하기
- .csv가 아닌 .parquet로 저장하는 이유
: spark에 최적화 되어있는 파일 포멧이 .parquet이기 때문이지~
df.write.format("parquet").save(
path = "data_parquet",
header = True
)# 파일 다운로드 받아주기 : 저장한 데이터는 앞으로 계속 쓸 수 있도록 zip 파일로 변환해 구글 드라이브에 업로드 해 주세요!
# 폴더명은 data_parquet
from google.colab import files
download_list = os.listdir('./data_parquet')
for file_name in download_list:
if file_name[-3:] != 'crc':
files.download('./data_parquet/' + file_name)

뭐가 됐든 데이터분석가