
본 포스팅은 제가 읽었던 논문을 간단하게 정리하는 글입니다. 논문의 모든 내용을 작성하는 것이 아닌, 일부분만 담겨 있으므로 자세한 내용은 원본 논문을 확인해 주시기를 바랍니다. 또한, 논문을 잘못 이해한 부분이 있을 수 있으므로, 양해 바랍니다.
Overview
실제 사진 같은 가짜 이미지를 찾아내거나, 이미지 속 편집된 부분(manipulated regions)을 찾아내는 등의 문제에서, low-level structure는 크게 도움이 되는 것으로 알려져 있음. Manipulated regions 외에도 그림자 영역, 가려진 객체 등을 찾을 때에도 low-level clues는 중요한 역할을 함.
본 논문에서는 manipulated parts, identifying out-of-focus pixels, separating shadow regions, and detecting concealed objects 등 다양한 segmentation task에서 활용할 수 있는 unfied approach를 제안함.
최근 NLP에서의 prompting은 frozen(가중치가 동결된) large foundation 모델을 다양한 downstream task에 적용할 수 있도록 minimum extra trainable parameter(adapter 등)를 추가하도록 함. 이러한 prompting을 통해 downstream task에서 보다 나은 일반화 성능을 얻을 수 있음.
NLP에서의 prompt tuning에서 영감을 받아, 새로운 visual prompting model인 Explicit Visual Prompting (EVP)을 제안함. 이전의 다른 visual prompting과 달리, EVP는 각 individual image의 explicit visual content에 집중함.
아래의 Figure 1.은 본 논문에서 제안하는 EVP를 간단하게 소개함.
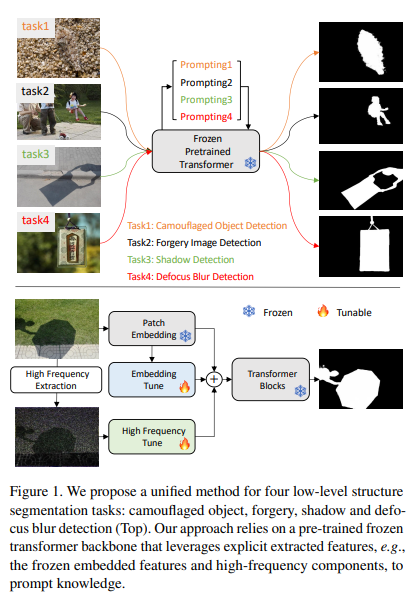
위의 Figure 1.에서와 같이, EVP는 두 가지의 feature를 추가적으로 사용함. Frozen patch embedding과 입력 이미지의 high-frequency component를 사용하며, patch embedding은 large-scale 데이터셋에서 사전 훈련되고 가중치가 동결된 pre-trained model로 얻을 수 있음.
제안한 방법을 4가지 task: forgery detection, shadow detection, defocus blur detection, camouflaged object detection에 적용하여 실험을 수행하였음.
Method
본 논문에서는 제안하는 EVP를 ImageNet에서 사전 훈련된 SegFormer에 적용(추가, adapting)하였음. EVP는 다른 prompting 방법과 유사하게 backbone을 frozen하고, tunable parameter를 조금 더 추가하여 task-specific 정보를 학습하도록 함.
Preliminaries
SegFormer
SegFormer는 semantic segmentation을 위한 hierarchical transformer based structure임. 자세한 것은 논문을 참고. EVP는 SegFormer에만 적용할 수 있는 것이 아니라, ViT, Swin 등 다양한 network structure에도 쉽게 적용될 수 있음.
High-frequency Components(HFC)
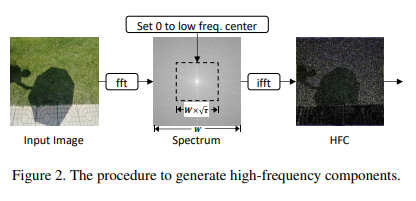
이미지의 high-frequency 및 low-frequency component는 푸리에 변환과 푸리에 역변환 과정을 통해 얻을 수 있음.
입력 이미지의 high-frequency component를 , low-frequency component를 이라고 한다면, 다음의 과정을 통해 각 component를 얻을 수 있음.
와 를 각각 Fast Fourier 변환과 역변환이라 하면, 푸리에 변환을 통해 이미지의 frequency component 를 얻을 수 있음.
Low-frequency 영역은 에서 중앙에 위치한 영역이므로, 중앙에 가까운 영역을 0으로 처리하는 binary mak 를 생성함.
는 마스크 영역의 surface ratio를 의미하며, 값이 커질수록 더 많은 영역을 0으로 처리함.
High-frequency component HFC는 다음과 같이 계산할 수 있음.
Binary mask를 조금 바꾸어 LFC 또한 계산할 수 있음.
RGB 이미지는 3개의 채널을 가지므로, 위의 process를 각 채널에 독립적으로 수행함.
Explicit Visual Prompting
EVP의 목표는 image embedding과 HFC에서 explict prompt(→ task specific knowledge)를 학습하는 것임.
아래의 Figure 3.은 EVC를 보다 자세히 설명함.
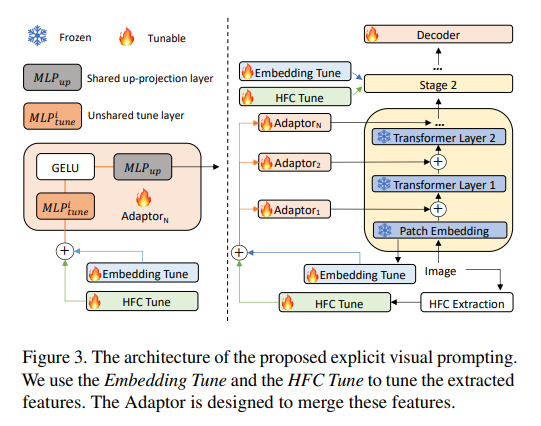
Patch embedding tune
입력 이미지의 patch를 SegFormer에 입력하면 해당 patch는 차원의 벡터 로 변환됨. 이 변환 과정의 가중치는 변경하지 않고, 추가적인 linear layer 를 추가하여 를 차원으로 투영함.
여기서 은 조절할 수 있는 scale factor임.
High-frequency components tune
는 SegFormer의 입력 patch size와 동일하게 분할된 다음, linear layer 에 통과되어 차원으로 투영됨.
Adaptor
Adaptor를 통해 patch embedding 정보와 high-frequency 정보를 network에 전달함.
번째 Adapter는 를 입력으로 받아 prompting 를 출력함.
은 모든 adaptor에서 공유되며, adaptor의 정보가 transformer layer에 더해질 수 있도록 up-projection을 수행함.
Experiment
앞서 소개한 4가지의 task: forgery detection, shadow detection, defocus blur detection, camouflaged object detection에서 실험을 수행하였음.

다양한 task에서 적은 수의 파라미터로 효과적인 성능 향상을 확인하였음. 자세한 실험 결과는 논문 참고.
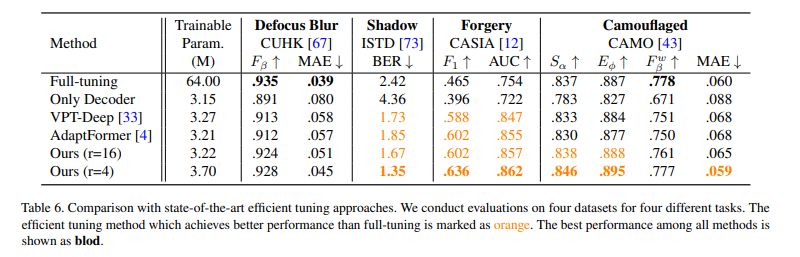
적은 수의 파라미터로 Full-tuning 보다 더 나은 성능을 얻을 수 있음을 확인하였음.
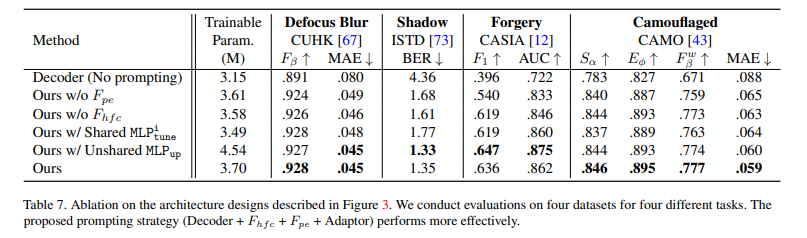
를 다른 adaptor와 공유할 경우 훈련해야 하는 파라미터는 줄지만, 성능이 감소함을 확인하였음.
을 공유하지 않고 adaptor마다 훈련할 경우 훈련 파라미터가 증가하고 일관적인 성능 향상을 보이지 않으므로 적절하지 않음.
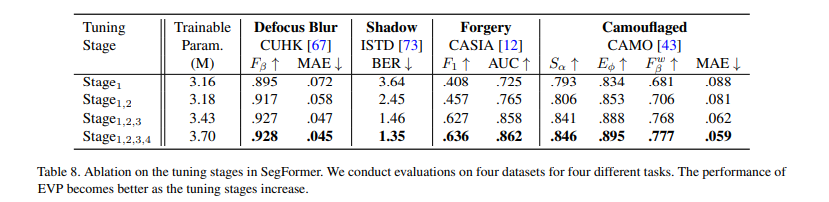
Tuning Stage를 추가할수록 성능이 향상됨을 확인하였음. 는 번째 transformer block에 adaptor를 추가한 것을 의미함.
아래 이미지는 SegFormer의 구조.
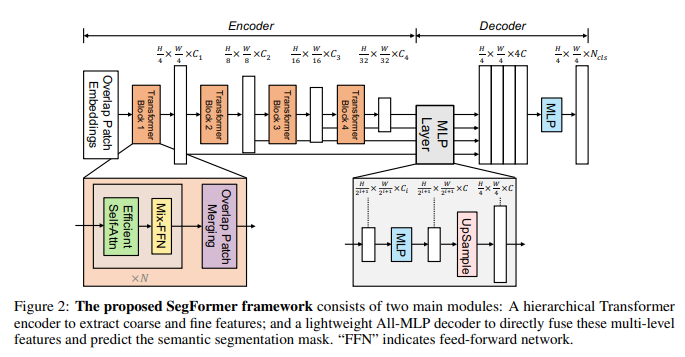
[Ref : Xie, Enze, et al. "SegFormer: Simple and efficient design for semantic segmentation with transformers." Advances in neural information processing systems 34 (2021): 12077-12090.]
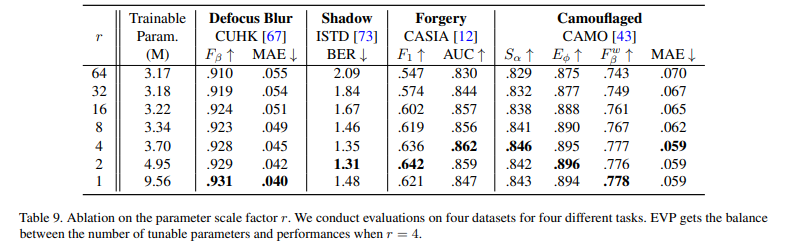
Scale factor 에 따른 실험 결과.
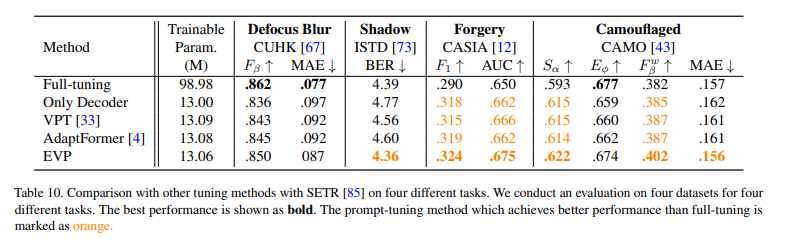
SegFormer가 아닌 plain ViT를 사용하는 SETR에 EVP를 적용한 후 성능 비교를 수행함. 다른 tuning method에 비해 보다 나은 성능을 보여줌을 확인하였음.
