
본 포스팅은 제가 읽었던 논문을 간단하게 정리하는 글입니다. 논문의 모든 내용을 작성하는 것이 아닌, 일부분만 담겨 있으므로 자세한 내용은 원본 논문을 확인해 주시기를 바랍니다. 또한, 논문을 잘못 이해한 부분이 있을 수 있으므로, 양해 바랍니다.
Overview
최근, segmentation을 위한 foundation model SAM(Segment Anything) 모델이 많은 관심을 받고 있음. SAM은 다양한 task에서 뛰어난 성능을 보여주었으나, shadow detection 또는 camouflaged object detection(concealed object detection) 등 특정 task에서는 좋지 못한 성능을 보여줌.
이러한 문제를 해결하기 위해, fine-tuning 기반의 방법이 아닌 adapter를 추가하는 SAM-adapter를 제안함. 해당 방법은 domain-specific 정보 및 visual prompt를 segmentation network에 추가하여 성능 향상을 도모함.
전체 SAM을 튜닝하는 것이 아닌 lightweight model을 추가함으로 task-specific guidance information을 더하여 downstream task에서의 성능을 향상시킬 수 있음.
Related Work
Adapters
Adapter의 개념은 NLP에서 먼저 등장하였음. Large pre-trained model을 downstream task에 맞게 전부 튜닝하는 것이 아니라, 훈련 가능한 파라미터를 조금 더 추가하여 해당 파라미터만 훈련하는 방법을 통해 효과적이고 효율적인 downstream task 수행이 가능함.
EVP 등 adapter 관련 다양한 연구가 존재하지만, SAM에 adapter를 적용하는 연구는 본 논문이 최초인 것으로 알려짐.
Camouflaged Object Detection (COD)

COD는 위의 Figure 2.와 같이 위장하고 있는 객체를 찾는 task를 의미함. 초기의 연구들은 이러한 객체를 찾을 때 텍스쳐, 밝기, 색상 등 low-level feature를 주로 사용하였음.
과거의 연구를 참고하여, 본 논문에서는 이러한 low-level feature를 prior(task-specific) knowledge로 사용하여 neural network에 추가함.
Shadow Detection

초기의 그림자 영역 감지 연구 또한 hand-crafted heuristic cues like chromacity, intensity and texture 등의 low-level feature를 사용하였음.
이러한 low-level feature를 사용한다면 foundation model의 성능을 보다 향상시킬 수 있음.
Method
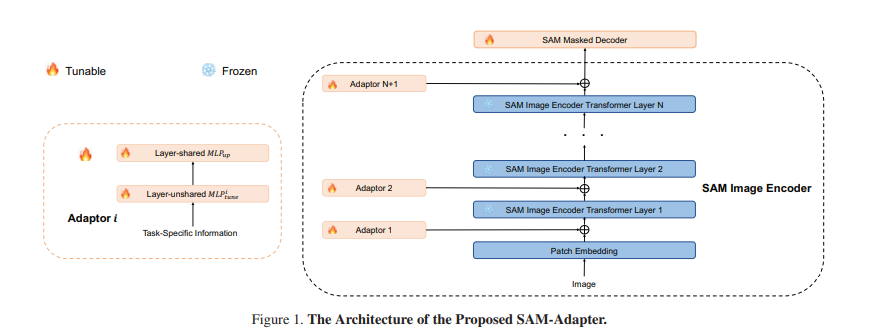
위의 Figure 1.을 통해 SAM-adapter의 전체적인 아키텍처를 확인할 수 있음. SAM을 segmentation을 위한 backbone으로 사용하며, 이미지 인코더의 가중치는 동결함. 이미지 인코더 사이사이에 각 Adaptor가 추가되는 것을 확인할 수 있음.
SAM의 mask decoder의 경우 pretrained SAM의 가중치로 초기화되며, Adaptor와 같이 훈련되었음.
Adapters
Task-specific knowledge 를 인코더에 추가하기 위하여 adapter를 사용함. 번째 adapter는 information 를 입력으로 받아 prompt 를 출력함.
은 각 adapter마다 task-specific prompt를 생성하게 하는 linear layer이고, 은 transformer layer와 차원을 맞게 하도록 up-projection을 수행하는 linear layer임. 은 모든 adapter에서 공유됨.
Input Task-Specific Information
Adapter에 입력되는 정보 는 모델을 적용하는 domain에 맞게 설계할 수 있음. 또한, 아래와 같이 여러 개의 guidance information을 더하여 를 생성할 수도 있음.
는 각 정보(텍스처, 색, 밝기 등)를 의미하며, 는 정보에 대한 가중치를 의미함.
Experiments
Implementation Details
본 실험에서는 두 가지의 visual knowledge를 기반으로 task-specific information을 생성하며, Patch embedding 와 high-frequency components 를 사용하여 를 계산함.
두 정보는 많은 vision task에 효과적인 것으로 알려져 있으며, 특히 high-frequency components는 shadow detection과 camouflage detection에서 효과적인 것으로 알려져 있음.
정보에 대한 가중치는 모두 1로 설정하여, 는 아래와 같이 계산됨.
는 32개의 유닛을 가진 linear layer이며, 를 통과한 정보는 GELU activation 함수를 지나 을 통과하여 transformer layer로 이어짐.
Experimental Results
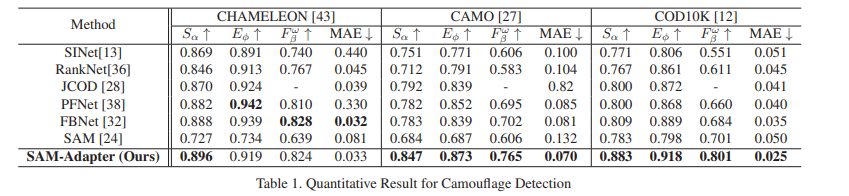
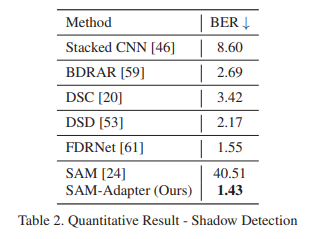
각 task에서의 SAM의 낮은 성능과 함께, SAM-Adapter의 높은 성능을 확인하였음.
Different Prompting Approaches of SAM
SAM은 box, point, mask 등 다양한 prompt를 지원함. Prompt에 따른 segmentation 결과는 아래의 Figure 4.에서 확인할 수 있음.

SAM Online은 SAM에서 지원하는 everything 모드를, SAM은 전체 이미지 크기와 동일한 box를 prompt로 주었을 때의 결과를 의미함.
두 방법 모두 위장된 객체와 그림자를 잘 찾지 못하는 것을 확인할 수 있음.
Ablation Study for SAM-Adapter

Adapter 없이 SAM decoder만 fine-tuning 했을 때와 성능을 비교하였음. 실험 결과를 통해 adapter의 중요성을 확인할 수 있음.
