
Good Backbone / Feature Extractor
이미지 분류, 객체 탐지 등 컴퓨터 비전에 사용되는 딥러닝 모델은 대부분 backbone, 혹은 feature extractor라고 불리는 네트워크를 가지고 있습니다. 이 네트워크는 아래의 이미지와 같이 VGG16, ResNet 등 CNN 기반의 네트워크입니다.
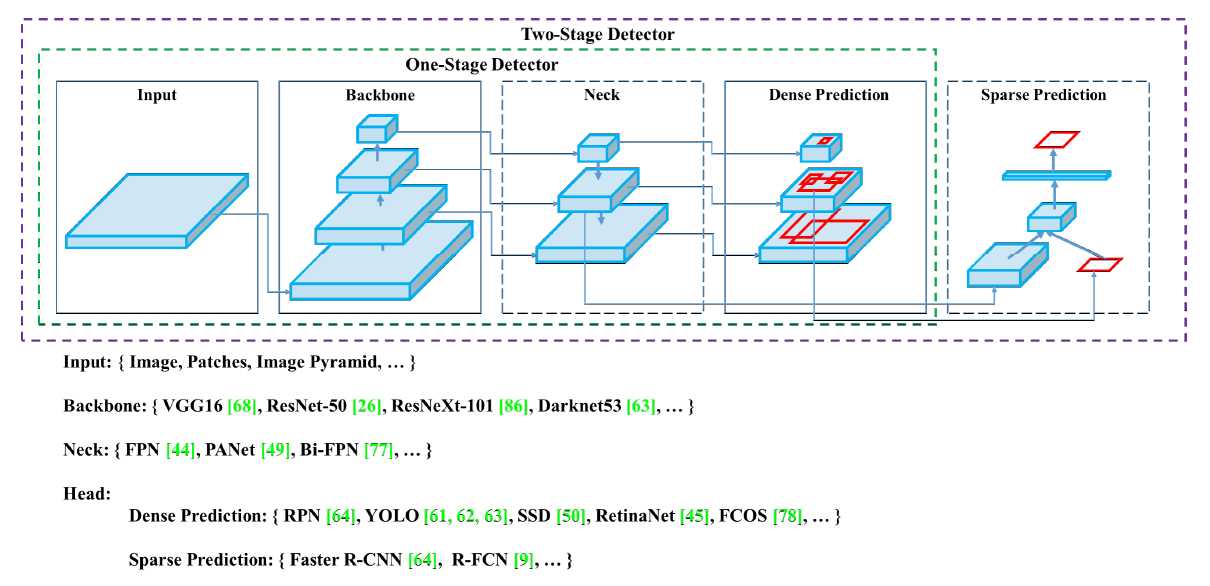
[이미지 출처]
이러한 backbone 네트워크의 목적은 입력 이미지에서 중요한 feature(representation)를 추출하는 것입니다. 그렇기에 feature extractor라고 불리기도 하는 것입니다.
이미지 속의 edge, texture와 같은 low-level feature는 그것이 강아지 이미지든, 자동차 이미지든, 혹은 다른 이미지든 간에 모두 동일하게 존재합니다. 따라서 일반적으로는 ImageNet 등 대규모의 이미지 데이터셋에서 사전 훈련된 모델(pre-trained model)을 backbone으로 사용합니다.
비록 분류하고자 하는 클래스 종류, 혹은 해결하고자 하는 task 종류가 달라도, 사전 훈련된 모델을 사용함으로써 충분히 좋은 feature를 얻어낼 수 있습니다. 사전 훈련된 backbone과 새로운 네트워크(classifier 등)를 연결하여 해결하고자 하는 문제(downstream task)에 훈련시키는 과정을 fine-tuning이라고 합니다.
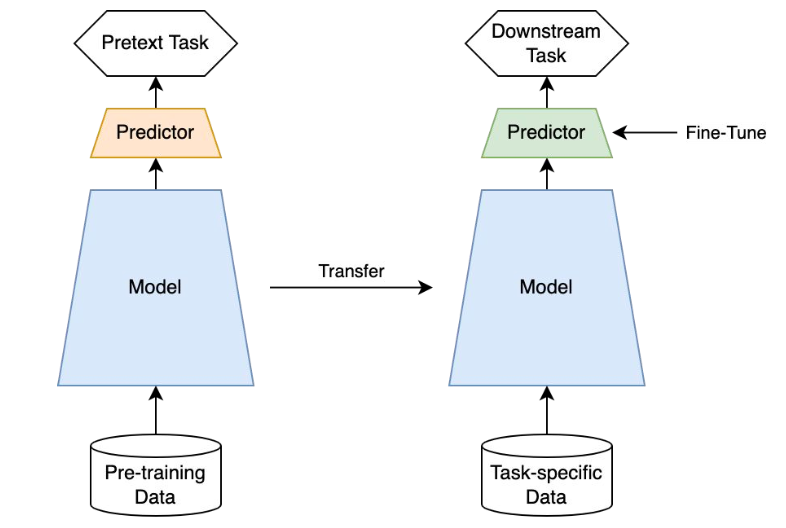
[이미지 출처]
혹은, 이러한 과정을 ImageNet 등 사전에 배웠던 지식을 전이(transfer)한다는 측면에서 전이 학습(transfer learning)이라고도 합니다. 전이 학습을 사용하면 상황에 따라 더 빠르고 고성능의 좋은 모델을 얻을 수 있습니다.
그렇다면, 좋은 backbone을 얻기 위해서는 전이 학습만이 유일한 해답일까요?
지난 포스팅에서는 Self-supervised learning의 일종인 SimCLR 논문에 대하여 간단하게 알아보았습니다. SimCLR은 간단히 말해서 두 이미지 사이의 유사도를 계산합니다. 이때, 서로 비슷한 두 이미지는 유사도가 크게, 서로 다른 두 이미지는 유사도가 작게 계산되도록 모델의 파라미터를 업데이트 합니다.
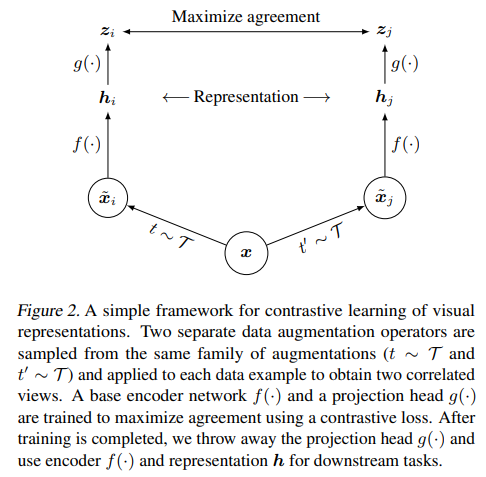
위 이미지에서, 하나의 이미지 가 rotation, flip 등 서로 다른 data augmentation을 통과하여 가 됩니다.
는 encoder 를 통과하여 representation 가 되고, 이들은 추가적인 네트워크 을 통과하여 가 됩니다. 모델의 파라미터는 사이의 유사도를 기반으로 업데이트 됩니다.
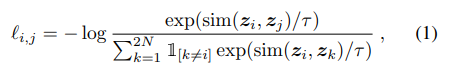
여기서, encoder 이 우리가 말하는 backbone, feature extractor입니다.
SimCLR의 학습 과정을 통해 backbone은 주어진 데이터셋에서 어떤 이미지가 서로 비슷하고 서로 차이 나는지 학습합니다. 이러한 학습을 통해 얻은 backbone은 전이 학습 때에서와 같이 downstream task를 위한 좋은 feature를 생성할 수 있습니다. 오히려, 지금 해결하고자 하는 데이터에서 backbone이 학습되므로 사전 학습된 모델보다 조금 더 나은 feature를 얻을 수도 있습니다.
저는 SimCLR 논문을 읽어보면서, 해당 학습 방법이 전이 학습과 어느 정도로 차이가 날 지 궁금했습니다. 이번 포스팅에서는 간단한 실험을 통해 SimCLR의 성능을 확인해 보겠습니다.
PCam Dataset
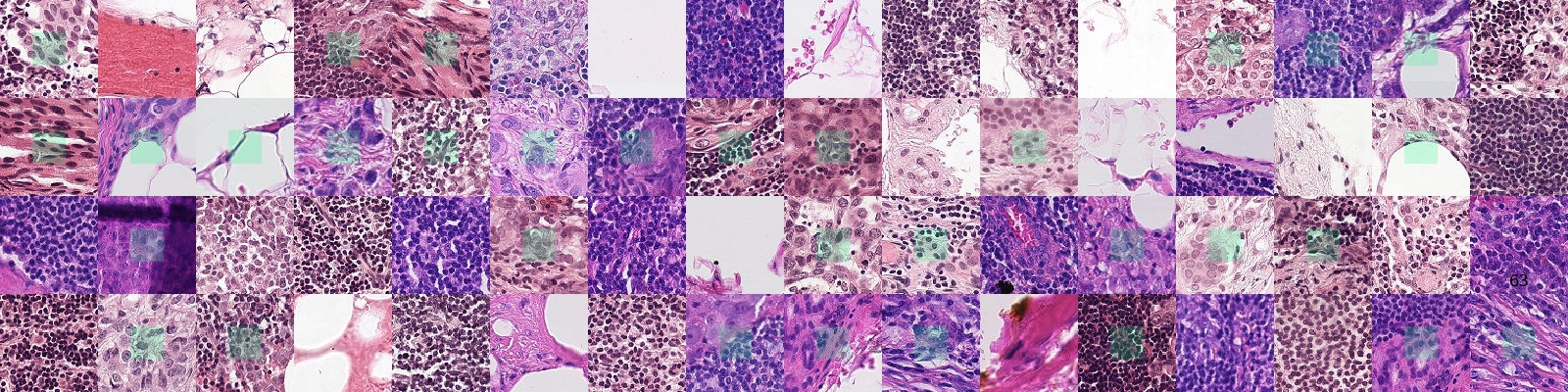
실험에서 사용한 데이터셋은 PCam(PatchCamelyon) 데이터셋입니다. 위의 이미지와 같이 조직병리학의 조직 이미지를 포함합니다. 96x96 크기의 이미지가 327,680장 존재하며, 이는 CIFAR10 데이터셋보다 크고 ImageNet 데이터셋보다는 작습니다.
사전 학습 모델로는 ImageNet에서 훈련된 모델을 사용할 것이므로, ImageNet의 이미지와 최대한 다른 데이터셋을 사용합니다. 이를 통해 downstream task data에서 직접 훈련되는 SimCLR의 성능을 더욱 확실히 알 수 있을 것입니다.
Experiment
Models
실험 구현을 위해 PyTorch를 사용하였습니다. 전체 실험 코드는 제 깃허브에서 확인하실 수 있습니다.
실험에서 사용하는 backbone은 두 종류로, VGG16과 ResNet34입니다. 아래와 같이 파이토치의 기본 구현을 사용하였습니다. 아래 예시는 VGG16입니다.
import torch
import torch.nn as nn
import torchvision.models as models
class VGG16_Backbone(nn.Module):
def __init__(self, pretrain=True):
"""
Backbone : VGG16
returns feature map, size ([batch_size, channels, width, height])
e.g. tensor size ([1, 3, 224, 224]) -> ([1, 512, 7, 7])
Args:
pretrain (bool, optional): if True, use ImageNet weights. if False, use kaiming_normal initialize in Conv layer. Defaults to True.
"""
super(VGG16_Backbone, self).__init__()
if pretrain:
self.backbone = models.vgg16(weights='IMAGENET1K_V1')
else:
self.backbone = models.vgg16(weights=None)
self._initialize_weights()
self.backbone_features = nn.Sequential(*list(self.backbone.features.children()))
def forward(self, x):
x = self.backbone_features(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0) Backbone 다음에 classifier를 붙일 수 있는 BasicClassifier 클래스를 정의하여 backbone을 바꿔 설정할 수 있도록 구현합니다.
class BasicClassifier(nn.Module):
def __init__(self, backbone, freezing=False, num_classes=1):
"""
Basic Classifier with Global Average Pooling
Args:
backbone (torch backbone)
freezing (bool, optional): if True, freeze weight of backbone. Defaults to False.
num_classes (int, optional): number of classes. Defaults to 1(binary classification).
"""
super(BasicClassifier, self).__init__()
self.backbone = backbone.backbone_features
if freezing:
for param in self.backbone.parameters():
param.requires_grad = False
self.avg = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(nn.Flatten(),
nn.Linear(512, 64),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(64, num_classes))
def forward(self, x):
x = self.backbone(x)
x = self.avg(x)
output = self.fc(x)
return output모델 정의 예시는 다음과 같습니다.
backbone = VGG16.VGG16_Backbone(pretrain=True).to(device=device)
model = basic_classifier.BasicClassifier(backbone=backbone,
freezing=True,
num_classes=1).to(device=device)이번 실험에서는 총 4가지 조건을 고려합니다.
- 전이 학습 / backbone 가중치 동결 후 classifier 학습
- 전이 학습 / backbone과 classifier 동시 학습
- SimCLR / backbone 가중치 동결 후 classifier 학습
- SimCLR / backbone과 classifier 동시 학습
네 조건 모두 총 50 에포크 동안 학습합니다.
Case 2, 4의 경우 warm-up을 위해 10 에포크 동안은 classifier만, 나머지 40 에포크에서 backbone과 classifier를 동시에 학습합니다. 사전에 학습된 backbone의 가중치를 고려하여 나머지 40 에포크에서는 학습률(learning rate)을 줄입니다.
Backbone의 종류가 2개이므로, 총 8번의 모델 학습이 있습니다.
Transfer Learning
Freezing backbone
VGG16
Backbone의 가중치를 동결한 후, 50 에포크 동안 classifier만 학습합니다. 아래는 VGG16의 실험 코드 일부입니다.
EPOCHS = 50
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-3)
es = train.EarlyStopping(patience=EPOCHS//2, delta=0, mode='min', verbose=True)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=EPOCHS//5, gamma=0.9)
history = {'train_loss' : [],
'val_loss': [],
'train_accuracy': [],
'val_accuracy': []}
max_loss = np.inf
for epoch in range(EPOCHS):
train_loss, train_acc = train.model_train(model=model,
data_loader=train_loader,
criterion=criterion,
optimizer=optimizer,
device=device,
scheduler=scheduler,
tqdm_disable=False)
val_loss, val_acc = train.model_evaluate(model=model,
data_loader=val_loader,
criterion=criterion,
device=device)
history['train_loss'].append(train_loss)
history['train_accuracy'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_accuracy'].append(val_acc)
es(val_loss)
# Early Stop Check
if es.early_stop:
break
if val_loss < max_loss:
print(f'[INFO] val_loss has been improved from {max_loss:.5f} to {val_loss:.5f}. Save model.')
max_loss = val_loss
torch.save(model.state_dict(), 'Best_Model_VGG_1.pth')
print(f'epoch {epoch+1:02d}, loss: {train_loss:.5f}, accuracy: {train_acc:.5f}, val_loss: {val_loss:.5f}, val_accuracy: {val_acc:.5f} \n')검증 손실이 최소가 될 때마다 모델을 저장하여, 이후 검증 손실이 가장 낮았던 모델을 확인할 수 있습니다.
아래는 학습 동안의 정확도와 손실, 테스트 데이터에서의 성능입니다.
| Accuracy | Loss |
|---|---|
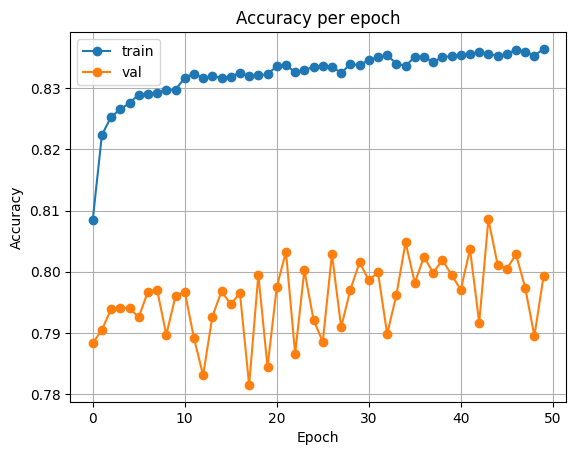 | 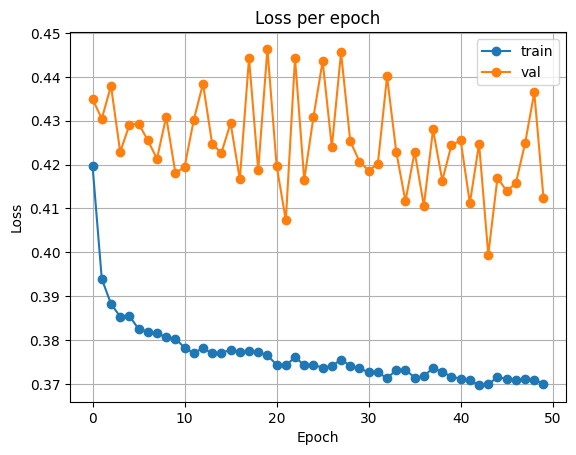 |
backbone = VGG16.VGG16_Backbone(pretrain=False).to(device=device)
model = basic_classifier.BasicClassifier(backbone=backbone,
freezing=True,
num_classes=1).to(device=device)
model.load_state_dict(torch.load('Best_Model_VGG_1.pth', map_location=device))
model.eval()
test_loss, test_acc = train.model_evaluate(model=model,
data_loader=test_loader,
criterion=criterion,
device=device)
print('Test Loss: %s'%test_loss)
print('Test Accuracy: %s'%test_acc)출력
Test Loss: 0.46649042423814535
Test Accuracy: 0.777862548828125
ResNet34
다음은 ResNet에서의 결과입니다.
| Accuracy | Loss |
|---|---|
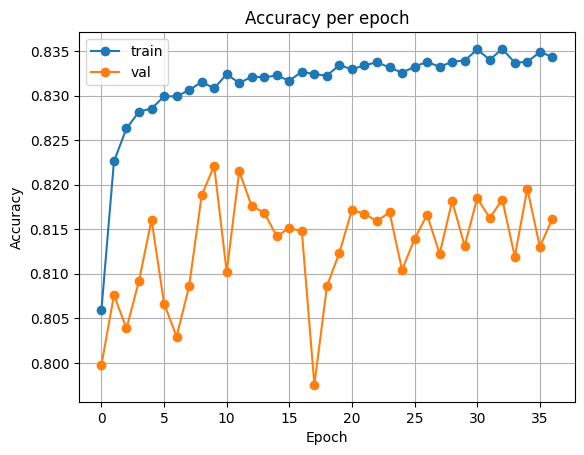 | 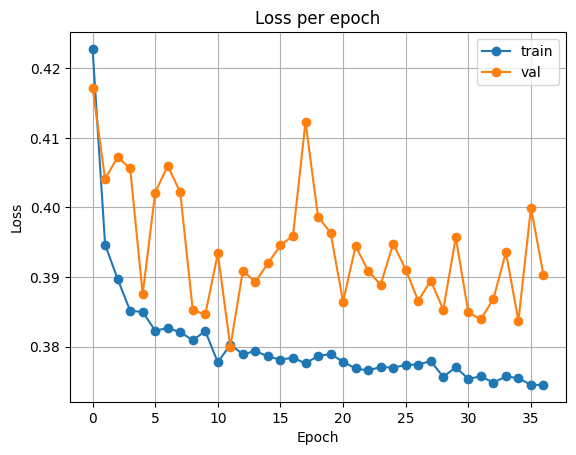 |
Test Loss: 0.4385412798728794
Test Accuracy: 0.789031982421875
VGG16 보다 조금 더 높은 정확도를 보여줍니다.
Fine-tuning
VGG16
이번에는 classifier를 10 에포크 동안 학습한 후, 나머지 40 에포크 동안에는 backbone과 classifier를 모두 학습합니다.
# Warm-up stage
# 0 ~ 10 epochs
EPOCHS = 10
criterion = nn.BCELoss()
# higher lr for warm-up
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-3)
max_loss = np.inf
for epoch in range(EPOCHS):
train_loss, train_acc = train.model_train(model=model,
data_loader=train_loader,
criterion=criterion,
optimizer=optimizer,
device=device,
scheduler=None,
tqdm_disable=False)
val_loss, val_acc = train.model_evaluate(model=model,
data_loader=val_loader,
criterion=criterion,
device=device)
print(f'epoch {epoch+1:02d}, loss: {train_loss:.5f}, accuracy: {train_acc:.5f}, val_loss: {val_loss:.5f}, val_accuracy: {val_acc:.5f} \n')warm-up이 종료되면, 다음과 같이 수행합니다.
# freezing True -> False
for param in model.backbone.parameters():
param.requires_grad = True
# Fine-tuning stage
# 10 ~ 50 epochs
EPOCHS = 40
criterion = nn.BCELoss()
# lower lr for fine-tuning
optimizer = optim.Adam(model.parameters(), lr=5e-4, weight_decay=1e-3)
es = train.EarlyStopping(patience=EPOCHS//2, delta=0, mode='min', verbose=True)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=EPOCHS//5, gamma=0.9)
history = {'train_loss' : [],
'val_loss': [],
'train_accuracy': [],
'val_accuracy': []}
max_loss = np.inf
for epoch in range(EPOCHS):
train_loss, train_acc = train.model_train(model=model,
data_loader=train_loader,
criterion=criterion,
optimizer=optimizer,
device=device,
scheduler=scheduler,
tqdm_disable=False)
val_loss, val_acc = train.model_evaluate(model=model,
data_loader=val_loader,
criterion=criterion,
device=device)
history['train_loss'].append(train_loss)
history['train_accuracy'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_accuracy'].append(val_acc)
es(val_loss)
# Early Stop Check
if es.early_stop:
break
if val_loss < max_loss:
print(f'[INFO] val_loss has been improved from {max_loss:.5f} to {val_loss:.5f}. Save model.')
max_loss = val_loss
torch.save(model.state_dict(), 'Best_Model_VGG_2.pth')
print(f'epoch {epoch+1:02d}, loss: {train_loss:.5f}, accuracy: {train_acc:.5f}, val_loss: {val_loss:.5f}, val_accuracy: {val_acc:.5f} \n')학습 결과를 확인해 보면 다음과 같습니다.
| Accuracy | Loss |
|---|---|
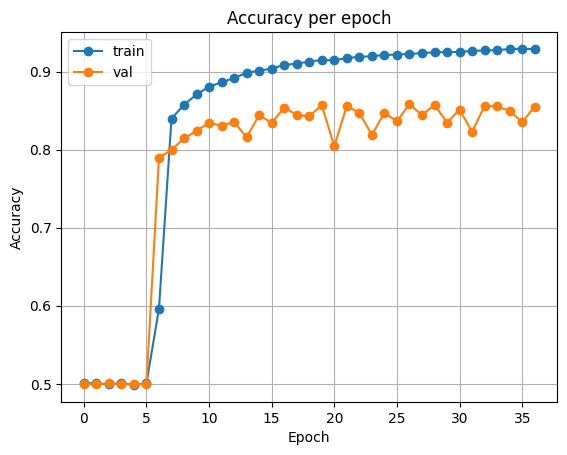 |  |
Test Loss: 0.42586067761294544
Test Accuracy: 0.833648681640625
ResNet34
| Accuracy | Loss |
|---|---|
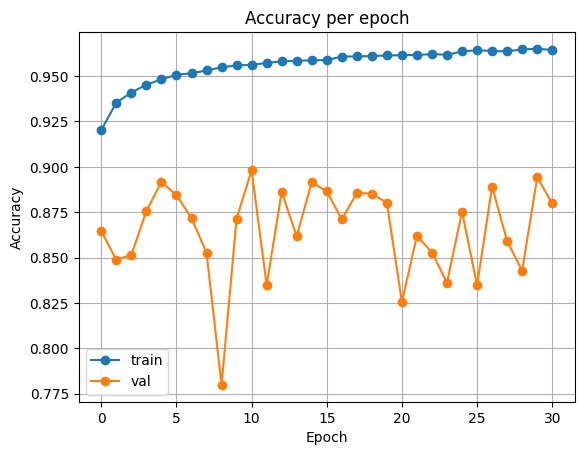 | 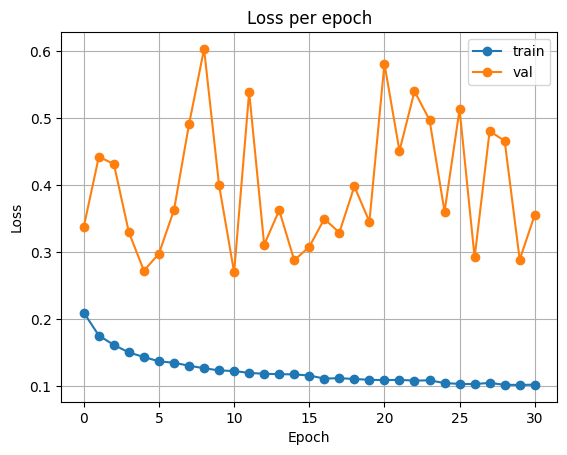 |
Test Loss: 0.4631400341168046
Test Accuracy: 0.8436279296875
두 모델 모두 단순 classfier 학습에 비해 정확도가 상승하였습니다.
- VGG16: 0.777 → 0.833
- ResNet34: 0.789 → 0.843
Backbone을 함께 훈련하면, 훈련하는 파라미터의 수가 증가하여 보다 많은 시간이 필요합니다. 시간이 충분하다면 backbone을 함께 훈련하는 것이 좋을 수 있겠습니다.
다음으로는 SimCLR 실험 결과를 확인해 보겠습니다.
SimCLR
SimCLR의 코드 구현은 PyTorch SimCLR 깃허브를 참고하였습니다. 기본적인 코드는 거의 동일하나, data_aug 등 PCAM 데이터셋에 적용할 수 있도록 약간의 수정을 하였습니다.
또한 위의 BasicClassifier와 같이, backbone을 원하는 대로 설정한 뒤 SimCLR 학습을 수행하도록 BasicSimCLR 클래스를 작성하였습니다.
class BasicSimCLR(nn.Module):
def __init__(self, backbone, num_classes=128):
"""
Basic SimCLR model
Args:
backbone (torch backbone): torch backbone
num_classes (int, optional): dimension of z. Defaults to 128.
"""
super(BasicSimCLR, self).__init__()
self.backbone = backbone.backbone_features
self.avg = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Sequential(nn.Flatten(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, num_classes))
def forward(self, x):
x = self.backbone(x)
x = self.avg(x)
output = self.fc(x)
return output이후 아래와 같이 정의된 모델은 SimCLR 클래스를 통해 학습합니다. BasicSimCLR의 fc layer는 이후 사용하지 않고 버립니다.
backbone = VGG16.VGG16_Backbone(pretrain=False).to(device=device)
model = basic_simclr.BasicSimCLR(backbone, num_classes=64).to(device=device)
simclr = simclr_train.SimCLR(model=model,
model_name='VGG16',
scheduler=scheduler,
optimizer=optimizer,
device=device,
epochs=100)
simclr.train(train_loader=train_loader) SimCLR 학습은 100 에포크 동안 진행하였으며, 이미지 간 유사도를 계산하는 의 차원 크기는 모두 64로 설정하였습니다.
해당 학습이 진행되면, SummaryWriter에 의해 run/ 디렉터리 아래에 로그 파일과 모델 체크포인트(학습된 모델 가중치)가 생성됩니다.
제 깃허브에는 .gitignore에 run/을 추가하여 해당 디렉터리가 존재하지 않습니다. SimCLR로 학습된 모델 체크포인트를 확인하시려면
checkpoints/디렉터리를 확인해 주세요. git lfs를 사용했습니다.
학습된 모델 가중치를 다음과 같이 불러온 후, backbone만 BasicClassifier에 추가합니다.
backbone = VGG16.VGG16_Backbone(pretrain=False).to(device=device)
model_temp = basic_simclr.BasicSimCLR(backbone, num_classes=64).to(device=device)
# path - VGG
log_dir = 'checkpoints/Mar30_11-40-32'
file_path = 'checkpoint_0100.pth.tar'
checkpoint_path = os.path.join(log_dir, file_path)
checkpoint = torch.load(checkpoint_path, map_location=device)
model_temp.load_state_dict(checkpoint['state_dict'])출력
<All keys matched successfully>
# backbone from SimCLR
model = basic_classifier.BasicClassifier(backbone=backbone,
freezing=True,
num_classes=1).to(device=device)이후 모델 학습 과정은 동일합니다.
Freezing backbone
VGG16
SimCLR에서 학습된 backbone을 사용하고, classifier만 학습한 결과입니다.
| Accuracy | Loss |
|---|---|
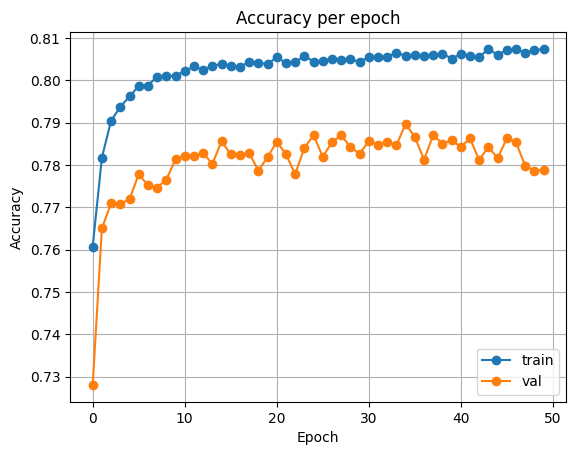 | 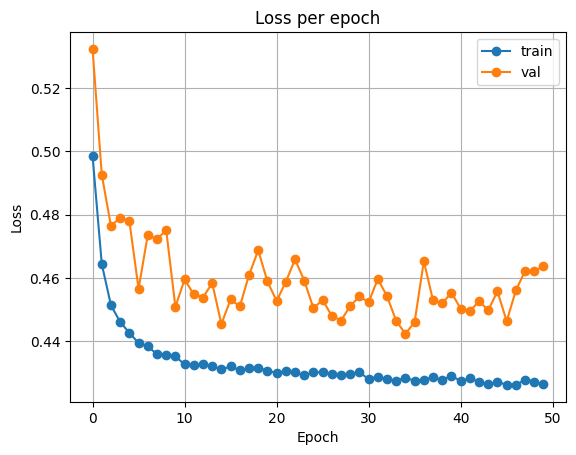 |
Test Loss: 0.4493719134479761
Test Accuracy: 0.797760009765625
ResNet34
| Accuracy | Loss |
|---|---|
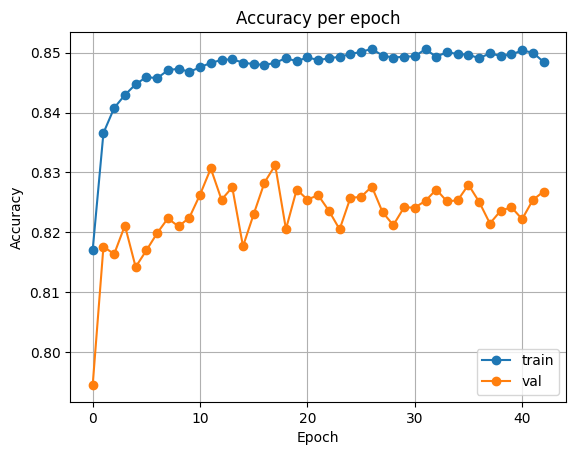 | 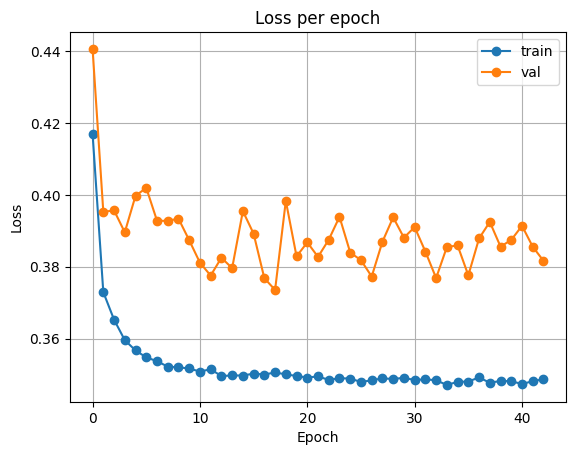 |
Test Loss: 0.40419348631985486
Test Accuracy: 0.815521240234375
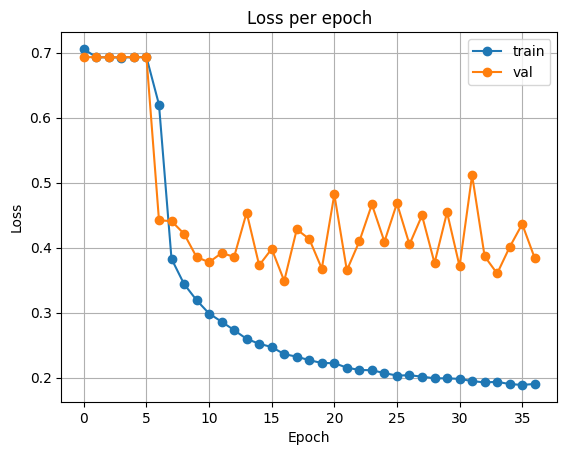
Fine-tuning
VGG16
전이 학습때와 마찬가지로 10 에포크 동안 classifier를 학습한 후, 나머지 40 에포크 동안 backbone과 classifier를 모두 학습합니다.
| Accuracy | Loss |
|---|---|
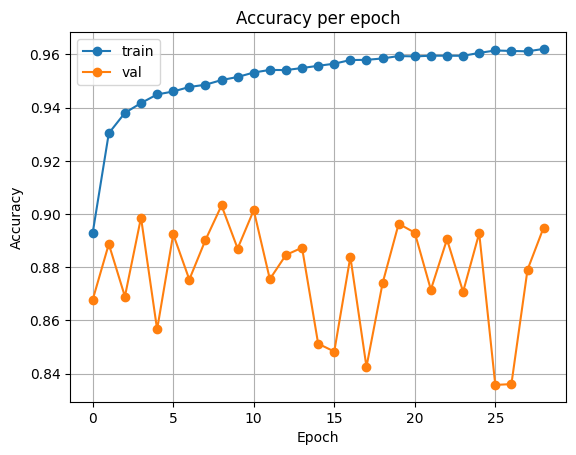 | 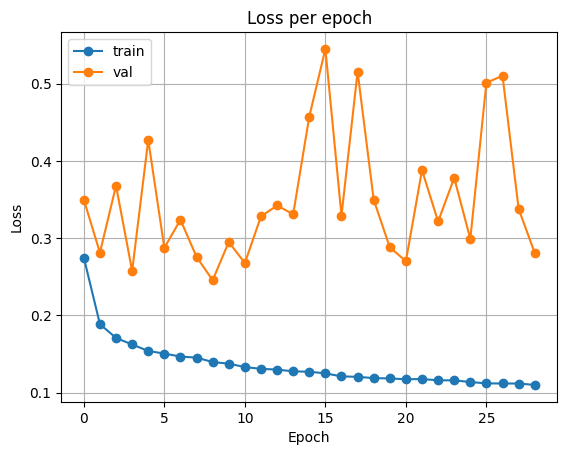 |
Test Loss: 0.3218463254161179
Test Accuracy: 0.877227783203125
ResNet34
| Accuracy | Loss |
|---|---|
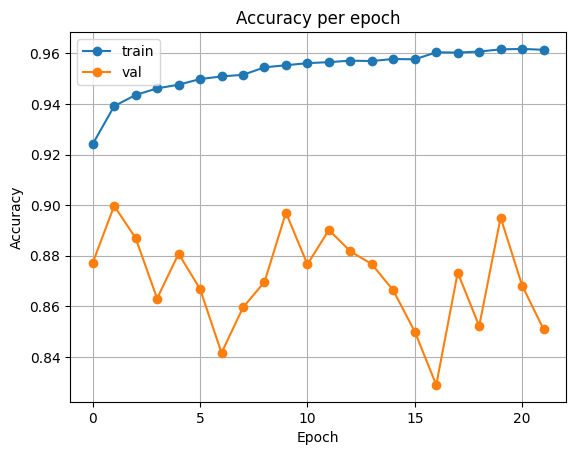 | 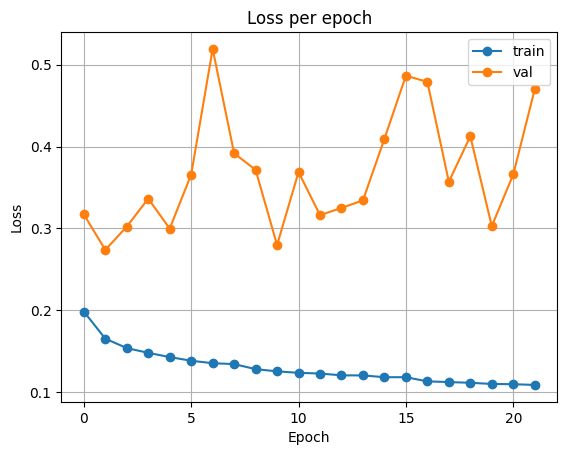 |
Test Loss: 0.40836958959698677
Test Accuracy: 0.84320068359375
Result
다음은 전체적인 실험 결과입니다. 표 안에 적인 지표는 모델의 정확도(accuracy) 입니다.
| Model | case 1 | case 2 | case 3 | case 4 |
|---|---|---|---|---|
| VGG16 | 0.777 | 0.833 | 0.797 | 0.877 |
| ResNet34 | 0.789 | 0.843 | 0.815 | 0.843 |
결과적으로, SimCLR을 통해 학습된 VGG16에서 fine-tuning을 적용했을 때 가장 좋은 성능을 얻을 수 있었습니다.
Conclusion
이번 포스팅의 간단한 실험을 통해 SimCLR의 성능을 확인할 수 있었습니다. 주어진 실험 결과를 보았을 때, 시간이 충분하다면 SimCLR을 통해 backbone을 학습시킨 다음 downstream task에 fine-tuning 한다면 좋은 결과를 얻을 수 있을 것 같습니다.
하지만 No Free Lunch theorem에서 말하듯, 모든 상황에 무조건 SimCLR이 좋다는 것은 아닙니다. 우선 실험에서 진행했던 task는 가장 간단한 이진 분류 문제이기도 하고, 다양한 하이퍼파라미터 값 등을 조절해 보면 다른 결과가 나타날 수 있습니다.
개인적인 아쉬움이 있다면 시간이 충분하지 않아 SimCLR의 학습 에포크를 100으로 설정한 것입니다. 200 혹은 300 등 더 크게 설정하였다면 결과가 어떻게 달라질지 궁금하네요.
이상으로 파이토치를 활용한 전이 학습 및 SimCLR 실험 포스팅을 마치겠습니다.
보다 자세한 코드 및 모델 체크포인트는 제 깃허브에서 확인하실 수 있습니다.
감사합니다.
