0. Abstract
- Recurrence나 convolution을 사용하지 않고, attention만을 이용하여 모델 구축 -> attention만을 이용하여 좋은 성능을 내었다.
1. Introduction
- 기존의 자연어 처리는 대부분 RNN과 encoder&decoder 구조를 가지고 있다.
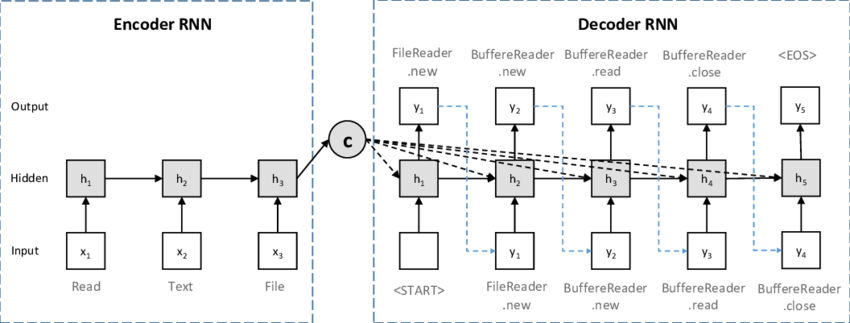
- 이런 구조는 길이가 긴 문장에서나 메모리의 한계점에서 단점이 존재 한다.
- 따라서 이 논문은 이러한 구조를 쓰지 않고 attention을 이용하여 모델 구현
2. Background
- (다른 논문에 대한 보충 공부 필요)
3. Model Architecture
- Transformer model은 self-attention과 FCL을 이용하여 기존의 encoder&decoder 구조를 사용했다.
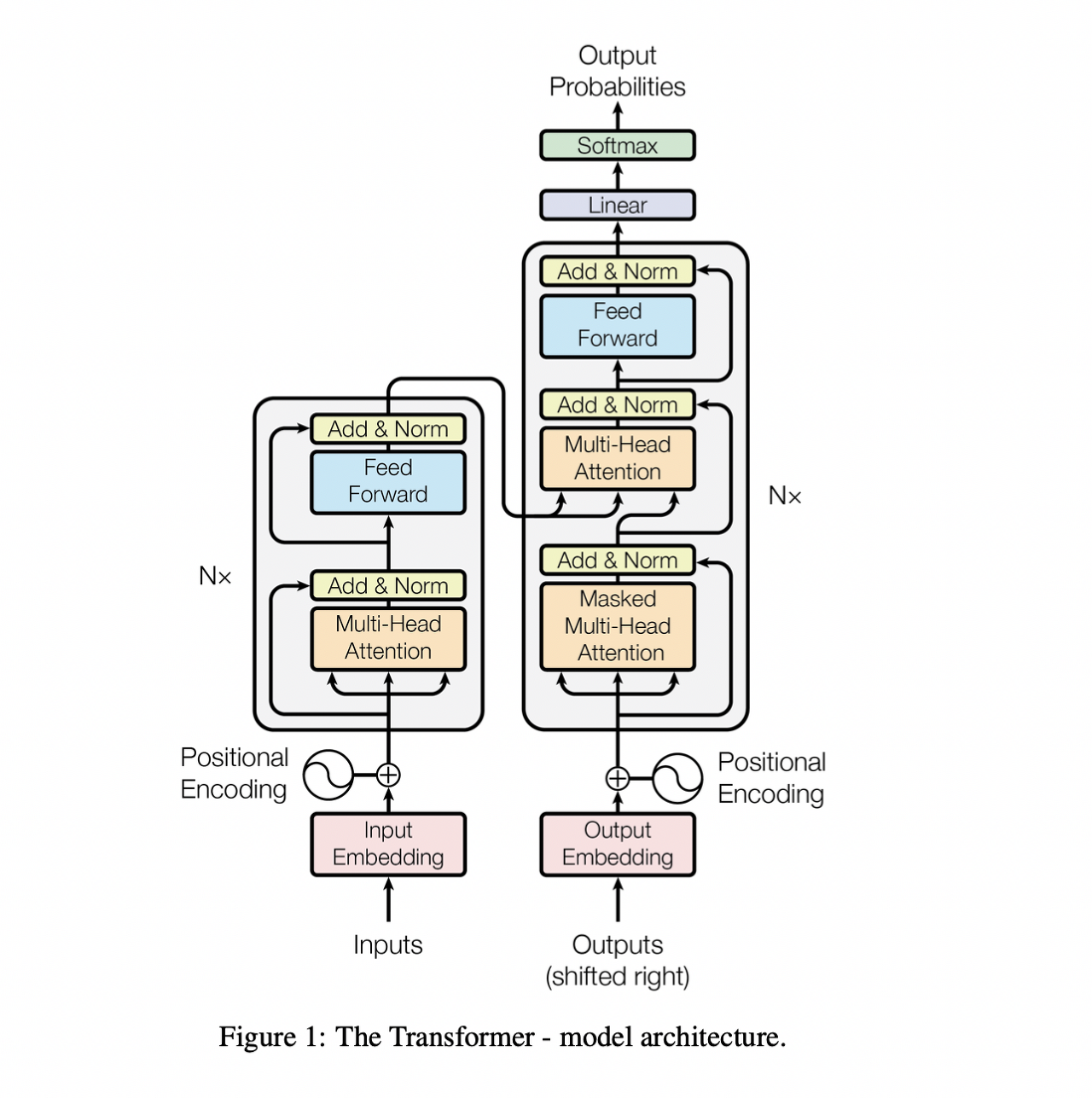
3.1] Encoder and Decoder Stacks
>Encoder
- 인코더는 6개의 동일한 layer로 구성
- 각각의 층은 2개의 sub-layer를 가진다(multi-head self-attention, position-size fully connected feed-forward network)
- 각각의 sub-layer의 output은 LayerNorm(x + Sublayer(x))이다. (Sublayer(x)는 sub-layer에서 실행된다)
>Decoder
- 인코더와 동일하게 디코더도 6개의 동일한 layer로 구성& 각각의 sub-layer의 output은 LayerNorm(x + Sublayer(x))
- 인코더에서의 출력을 입력으로 받는 3번째 sub-layer 포함
- self-attention sub-layer는 mask 추가 -> i번째 항목에 대해서 i-1번째 항목까지만 학습에 고려하도록 하는 역할(이후의 다음 요소는 고려하지 않도록 함)
3.2] Attention
- Attention function은 query, key, value로 표현
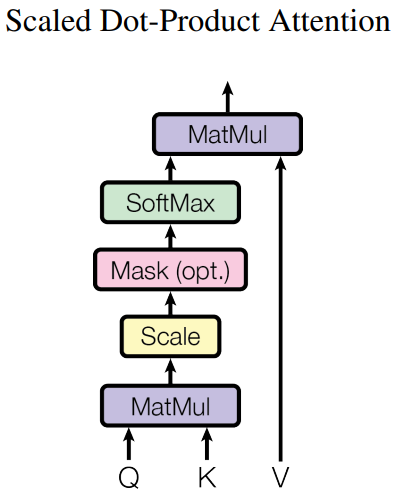
3.2.1> Scaled Dot-Product Attention
- Q, K를 내적하고 이를 sqrt(d_k)로 나눈 값을 softmax함수를 통과시킨다. 이후 이를 V와 곱하여 attention 계산
- sqrt(d_k)로 나누는 이유는 softmax의 인자 값이 너무 커지면 기울기가 소실되어 업데이트가 제대로 되지 않기때문
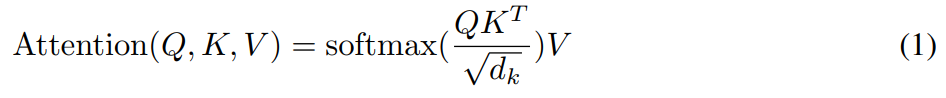
3.2.2> Multi-Head Attention
- 이 논문에서는 하나의 attention function을 계산하는 것이 아닌, h개로 Q,K, v를 나누어 h개수 만큼의 attention function을 구하고 합쳐주는 과정을 거쳤다.

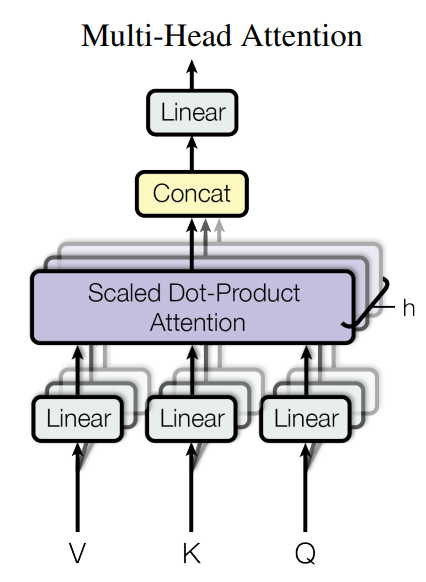
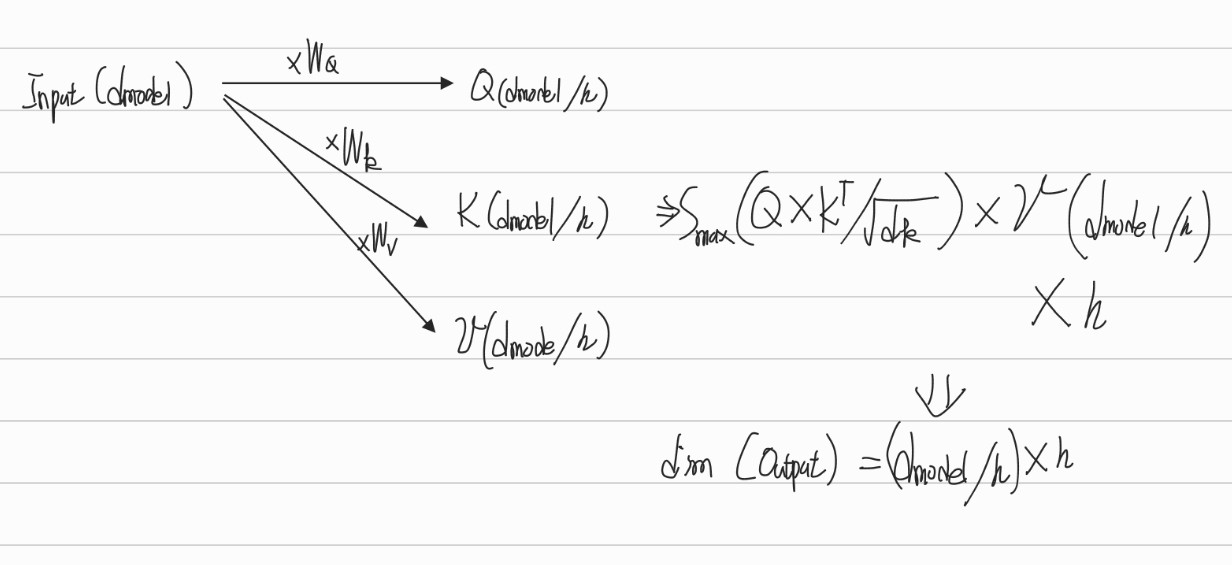
3.2.3> Applications of Attention in our Model
- multi-head attention을 3개의 방법으로 적용
- Q는 디코더에서 K,v는 인코더에서 온 encoder-decoder attention layer
- 인코더에서 self-attnetion layer
- 비슷하게 디코더에서 self-attention layer
3.3] Position-wise Feed-Forward Networks
- Relu 함수를 각각의 attention sub-layer 이후에 사용
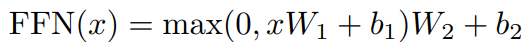
3.5] Positional Encoding
- 토큰의 상대적/절대적 위치에 따라 학습하기 위하여 encoder와 decoder의 맨 아래층에 positional encodings를 넣었다.
- sin/cos함수 이용(pos: position, i: dimension)
- i차원의 positional encoding이 삼각함수에 대응된다
- 삼각함수를 사용한 이유: PE_pos+k를 PE_pos를 이용해서 나타낼 수 있기 때문에 상대적인 위치를 잘 학습할 수 있을 것이다.
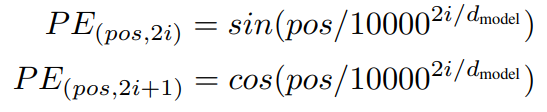
4. Why Self-Attention
- Self-attention 기법을 사용한 이유
1) The total computational complexity per layer
- 보통 n이 d보다 작기 때문에 attention을 사용하여 계산량이 줄어든다.
2) The amount of computation that can be parallelized
- 병렬적인 계산에 attention이 유리하다.
3) The path length between long-range dependencies in the network
- 멀리 떨어진 sequence도 잘 학습할 수 있다.

6. Results
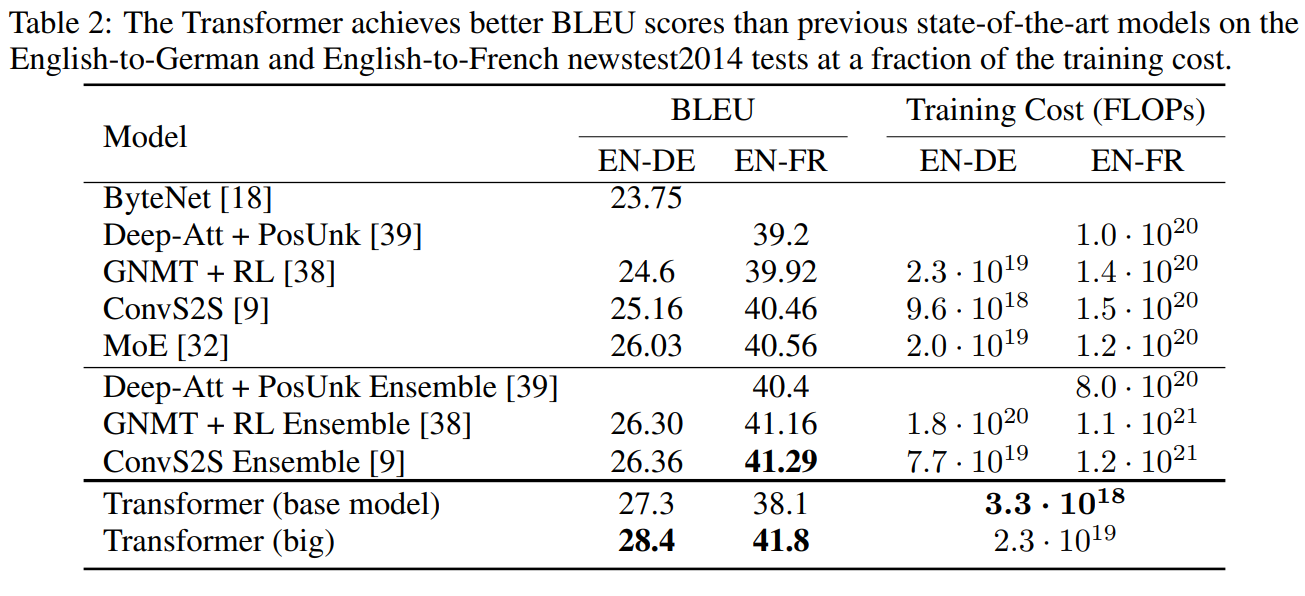
6.1] Machine Translation
- Transfomer의 BLEU점수가 좋은 것을 확인
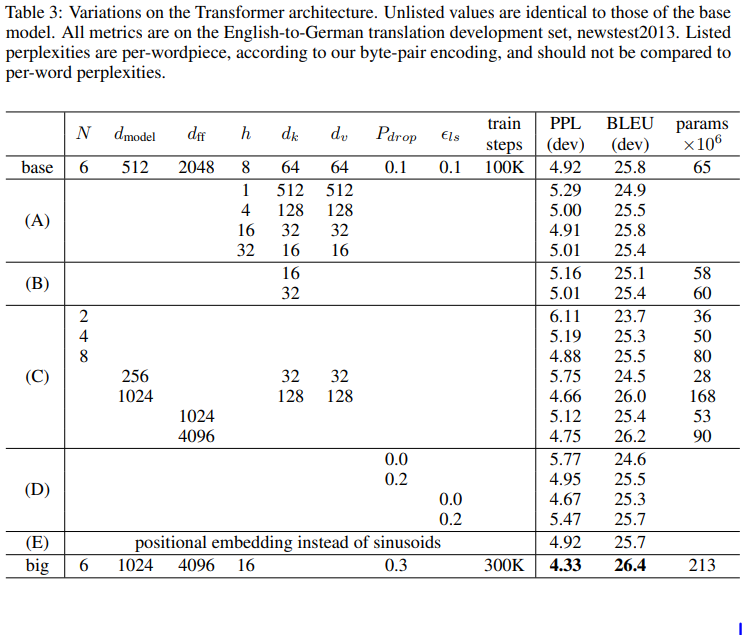
6.2] Model Variations
- Transformer base모델에서 여러 조건을 변형하여 실험
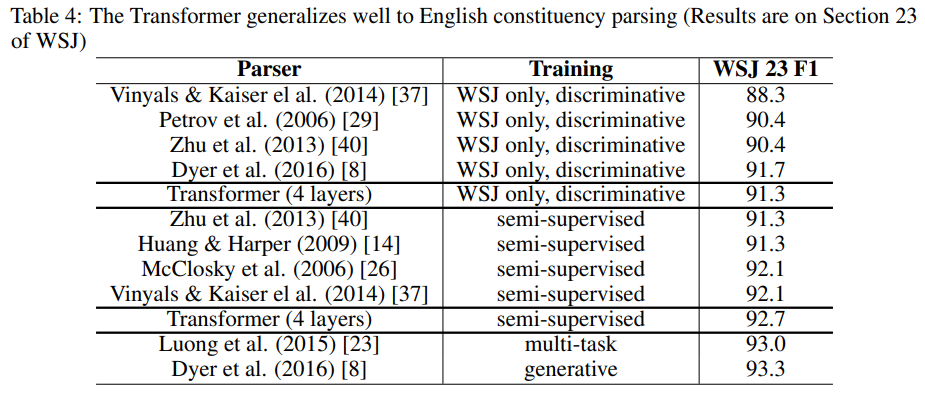
6.3] English Constituency Parsing
-다른 작업(English constituency parsing)도 잘 할 수 있는지 실험

호수공원