NeRF:Representing Scences as Neural Radiance Fields for View Synthesis Review
cv_paper_reviews
0. Abstract
- 이 논문의 알고리즘은 5차원의 입력(x, y, z + 2차원의 카메라 각도 정보)와 2차원의 출력(색, 밀도)로 이루어진 fully-connected deep-network이다.
- 복잡한 형태의 사진을 렌더링하기 위해 neural radiance field를 최적화 시켰는지 소개
view synthesis란?
- 찍은 시점이 다른 여러가지 이미지를 학습하여 여러 시점에서도 연속적으로 이미지를 볼 수 있도록 이미지의 모양을 합성하는 분야
- depth에 따라 물체가 움직이는 정도가 다르기 때문에 난이도가 높은 분야이다.
1. Introduction
-
정적인 사진을 연속적인 5차원 함수로 표현
-
그 함수의 출력은 물체의 각 포인트와 카메라 시점에 의해 반사된 빛들이다.
-
함수의 output중 density는 빛이 그 point에서 얼마나 축적이 되었는지를 표현한다.(얼마나 투명하지 않은지를 나타내는 것 같다.)
-
Neural radiance field를 만들기 위해
1) 3차원의 샘플을 얻어내기 위해 여러 시점에서 카메라로 물체를 찍는다.
2) 사진의 찍은 지점과 각도를 input으로 하고 색과 밀도를 output으로 하는 모델을 학습한다.
3) 기존의 volume rendering기술을 이용해 이 색과 밀도를 2차원의 이미지에 축적한다. -
모델의 충분한 성능을 내기 위해서 (1)positional encoding과 (2)hierarchical sampling procedure 사용
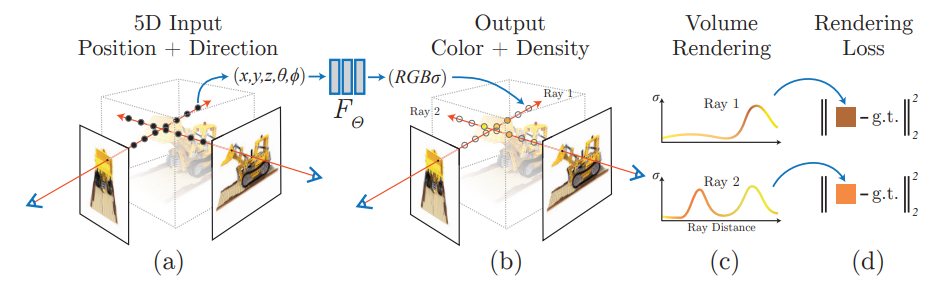
3. Neural Radiance Field Scene Representation
- 보는 시각에 따라 색과 밀도를 잘 나타내기 위하여 256개의 채널을 가지는 8개의 fully connected layer를 활용하였고 output으로 밀도와 256차원의 feature vector를 가진다.
- (c)에서 보이는 것과 같이 물체에서 반사되는 색은 연속적으로 변하고 이 논문은 이 것을 예측하는 것을 목표로 한다.

4. Volume Rendering with Radiance Fields
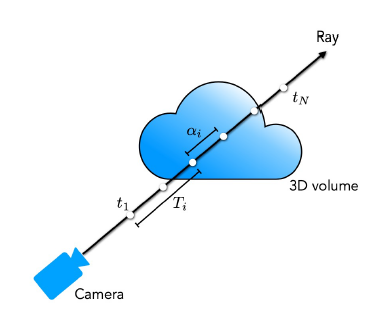
- equation(1)은 ray r(t) = o + td이고 범위가 t_n, t_f인 ray에 대한 point의 예상되는 색을 말한다. 여기서 T(t)는 t_n부터 t까지의 투과도를 나타낸다.(t까지 벽이 있다면 물체가 보이지 않으므로)

- [t_n, t_f]의 공간을 N개로 나누어 색과 밀도를 계산 -> 자세한 내용은 참조 논문을 읽어보아야 한다.
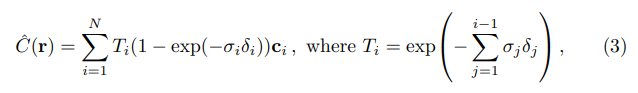
5. Optimizing a Neural Radiance Field
-
모델의 성능을 끌어 올리기 위해 두가지 방법을 사용
5.1) Positional encoding
-
deep network는 진동수가 낮은 함수로 학습이 되려는 경향을 가짐-> 이로인해 NeRF가 급격한 변화나 복잡한 이미지에 대해서 학습을 잘 하지 못함
-
이를 해결하기 위하여 모델을 학습하기 전에 높은 진동수를 가지는 함수를 input에 mapping하는 작업을 거친다.
-
equation(4)와 같은 함수를 위치 벡터와 카메라 방향벡터에 각각 적용한다.
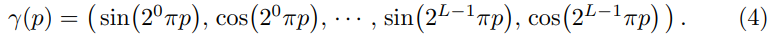
-
transformer의 경우 sequential한 토큰을 서로 잘 구별해주기 위하여 positional encoding을 사용하였지만, 이 논문의 경우 높은 진동수의 정보를 담고 있는 이미지를 잘 해석하기 위하여 postional encoding을 사용했다는 차이점이 있다.
5.2) Hierarchical volume sampling
-
지금까지 진행했던 렌더링의 문제는 물체가 없는 빈 공간과 물체가 존재하는 공간이 같이 렌더링 된다는 문제가 있었다. 이를 해결하기 위해 hierarchical volume의 방법을 사용
-
이를 위해서 하나의 네트워크를 2개의 네트워크로 분리(coarse&fine)
(1) coarse: coarse네트워크를 구하기 위해 ray에서 개의 샘플을 뽑는다. 그리고 coarse network를 equation(2),(3)을 사용해 계산한 후 실제 물체와 관련이 있는 부분을 뽑는다.
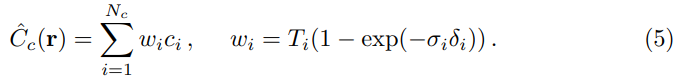
이때 를 다음과 같이 정규화화면, piecewise-constatnt PDF를 구할 수 있다. (나중에 더 알아봐야겠다!)
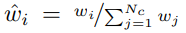
(2) fine: inverse transform sampling을 이용하여 를 샘플링하고 두 샘플을 이용해 네트워크를 평가한다. -
이런 방식을 통해 물체가 실존하는 공간이 렌더링 되는 횟수가 더 많아진고 모델의 성능을 올릴 수 있다.
5.3) Implementation details
- 학습을 최적화 하기 위해, 데이터 셋에서 ray배치를 렌덤으로 샘플하였다.
- Loss function:

R은 각 배치안에 있는 ray들을 나타내고 C^는 ground truth를 나타낸다. - 최적화 적용 결과 -> 복잡한 부분에서 좋은 성능을 내는 것을 관찰할 수 있다.

6. Results

NeRF가 다른 모델에 비해 성능이 좋은 것을 확인할 수 있다.
참조
