Review: Two-Stream Convolutional Networks for Action Recognition in Videos
cv_paper_reviews
목록 보기
10/22
1. Introduction
- In this paper, it tried to use CNN for recognizing human action which containing sptial and temporal information
- Architecture is based on two streams(spatial info -> video frames/ temporal info -> optical flow)
2. Two-stream architecture for video recognition

- As shown in Fig1, there are two stream( spatial stream and temporal stream )
- Each stream is implemented using CNN and the softmax scored of last fusion( averaging and SVM )
Spatial stream CNN : there are useful clues in static frames
3. Optical Flow CNN
- Optical CNN is CNN model about temporal recognition
3.1: CNN input configurations
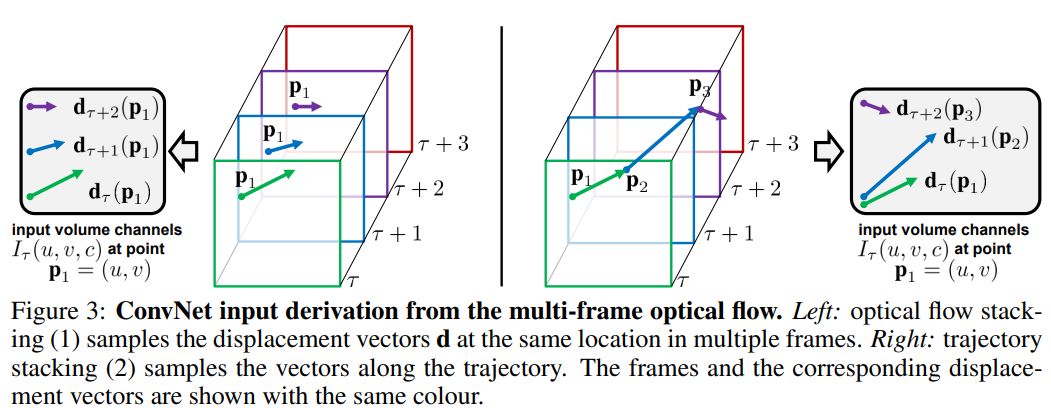
Optical flow stacking
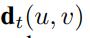 -> displace vector at point (u,v) in frame t.
-> displace vector at point (u,v) in frame t.
-
representing motion by stacking the flow channels of L consecutive frames
=> 2L input channel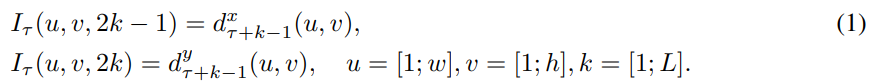
Trajectory stacking
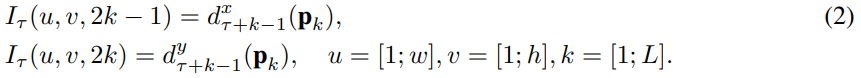
- (1) : stores displacement
- (2) : stores vector samples along the trajactory
Bi-directional optical flow
- computting additional set of displacement fields in the opposite direction
- construct input by stacking forward L/2 frames and -L/2 frames
Mean flow subtraction
- There can be case like camera movement which can cause dominant displacement
- for simplify, just substracting mean vector
4. Multi-task learning
- it is hard to concatnate two different dataset for video learning
- there are two softmax layer ( one for HMDB-51 and one for UCF-101 )

호수공원
2개의 댓글

2024년 6월 23일
Choosing a niche is crucial because it helps you focus your content, attract a specific audience, and establish yourself as an authority in that area. trusted plinko casino
답글 달기
What's with the recognition in videos? What does it even mean? Does it have something to do with Streamer Technik Tipps? Or am I wrong to suggest this?