
1. Abstract & Introduction
- 기존의 GAN은 3D이미지를 구축하는데 한계가 있었다. 이 논문은 그 한계를 radiance field를 활용해 해결했다고 한다.
- 3D image synthesis는 사진의 pose를 통해 다른 위치에서도 물체를 보는 것과 같이 view를 생성한다. 하지만 현실에서는 물체의 위치와 각도 정보를 구하는 것이 어렵고 다른 논문들은 이를 2D supervision으로만 해결하려고 했다.
- 따라서 이 논문은 3가지의 목적이 있는데,
- radiance field를 생성하는 모델을 통해 pose 정보가 없는 이미지에 대해서도 3D aware한 정보를 만들 수 있다.
- patch-based discriminator.
- 체계적으로 현실의 데이터에서 실험을 진행한다.
3. Method
3.1 Neural Radiance Fields
- radiance field는 3차원의 이미지를 2차원에서 보는 각도에 따라 RGB의 값을 연속적으로 이어주는 mapping이다. NeRF에서는 3차원의 카메라 위치 정보와, 2차원의 카메라 방향 정보를 feature representation에 사용하였다. 이때 복잡한 현상의 데이터에서도 학습이 잘 이루어지도록 하기 위해 positional encoding을 사용하였는데, 즉 카메라의 위치&방향 정보를 사용하여 이미지의 색과 밀도(투명도)를 MLP로 학습하였다. 이 논문에서는 이 positional encoding이 효과가 있었다는 것을 입증하였고, 각도에 따른 색의 변화는 카메라의 위치 변화에 따른 색의 변화보다 훨씬 매끄럽기 때문에 방향에 따른 정보를 인코딩할때 더 적은 component가 쓰였다고 한다.
- euqation (1),(2)는 대략적인 NeRF의 구조를 나타내는데, equation (2)에서 볼 수 있듯이 카메라의 위치와 방향정보를 encoding하고 이를 출력 이미지의 색과 밀도를 학습하는데 쓰이는 것을 볼 수 있다.
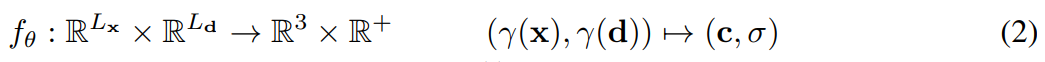
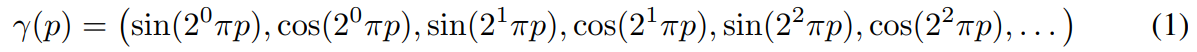
3.2 Generative Radiance Fields
-
앞의 NeRF의 경우에는 학습을 하려면 이미지의 position과 direction이 필요하다는 단점이 있다. 따라서 이 논문에서는 위치와 방향 정보 없이 image synthesis를 하려고 시도하였다. 이를 위해 GAN의 nenerative&adversarial 구조를 사용하였다.
-
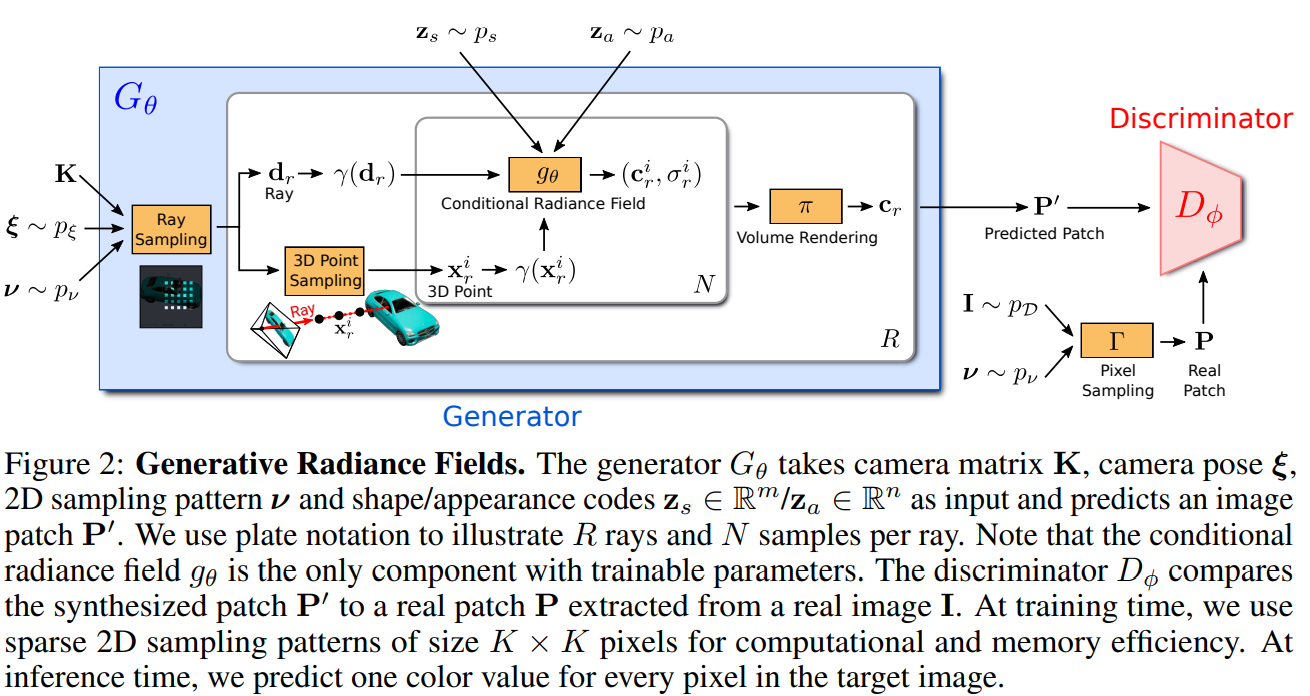
Figure 2는 GRAF의 대략적인 구조를 설명하는 그림이다. generator인 는 camera matrix , camera pose ξ, 2D sample pattern 와 shape/apperance code 을 입력으로 받아 이미지 패치 를 출력으로 한다. 그후 discriminator는 진짜 이미지 패치 를 이 출력과 비교한다. 여기서 이미지가 아닌 이미지의 패치로 학습하는 이유는 학습량이 너무 많아지기 때문이라고 한다.
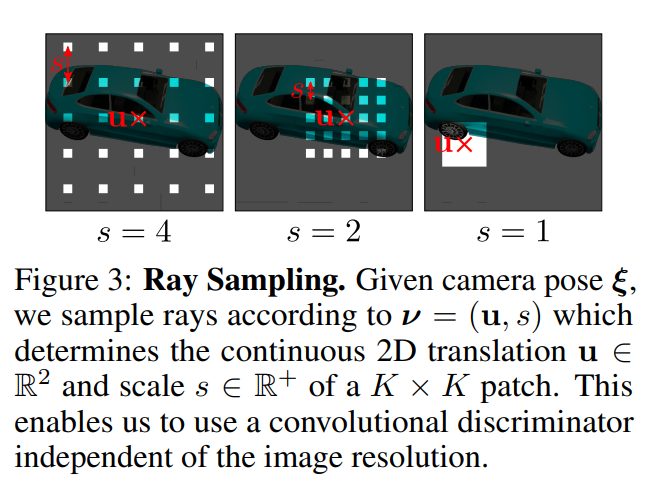
3.2.1 Ray Sampling:

호수공원