1. Abstract & Introduction
What is Constrative Learning?
- Constrative learning은 라벨링이 되지 않은 데이서셋에서 스스로 input과 label을 만들어 pretext task를 수행하는 self supervised learning 중 하나이다.
- Constrative learning은 같은 이미지에서 나온 이미지 조각의 represenation은 서로 가까워지도록, 다른 이미지에서 나온 이미지 조각의 representation은 서로 멀어지도록 학습을 진행한다. 그림을 보면 같은 이미지에서 나온 이미지 조각은 positive pairs로, 다른 이미지에서 나온 이미지 조각은 negative pairs로 분류하여 학습하는 것을 관찰할 수 있다.
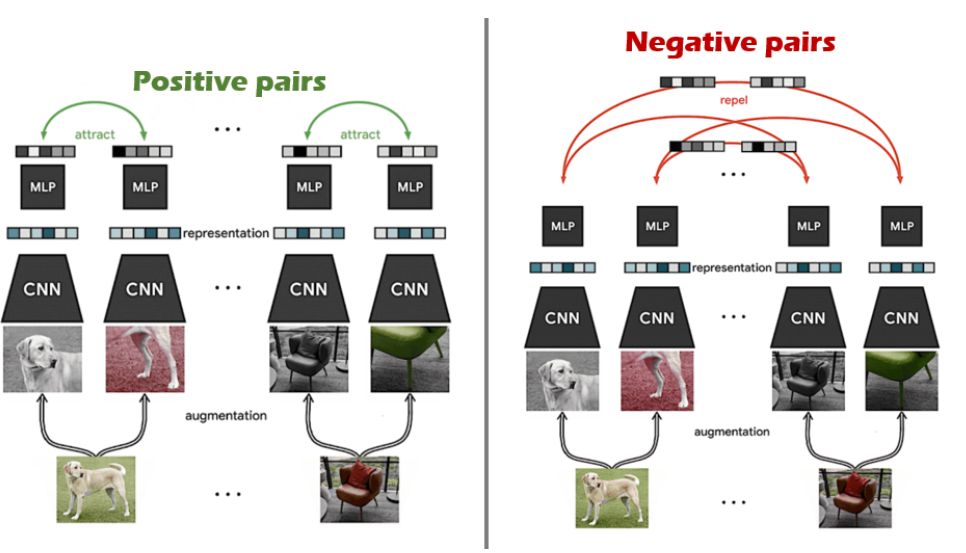
-
이 논문에서는 이런 contrastive learning의 성능을 높이기 위한 4가지 부분을 설명한다.
- 여러 개의 data augmentation
- learnable nonlinear transformation
- contrastive cross entropy loss
- larger batch size & longer training
-
이렇게 하여 다음과 같이 좋은 성능을 내었다고 한다.
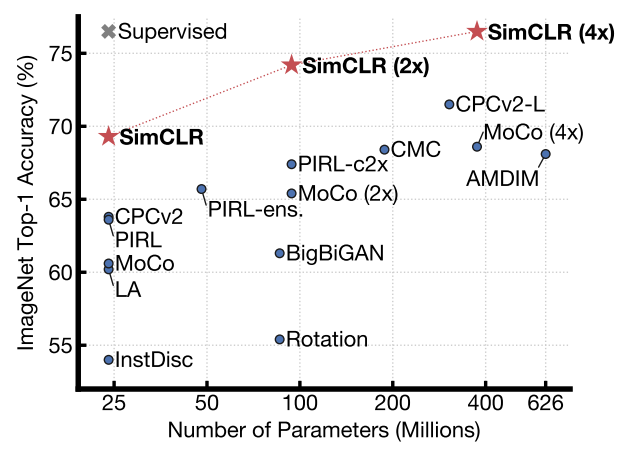
2. Method
2.1) The Contrastive Learning Framework
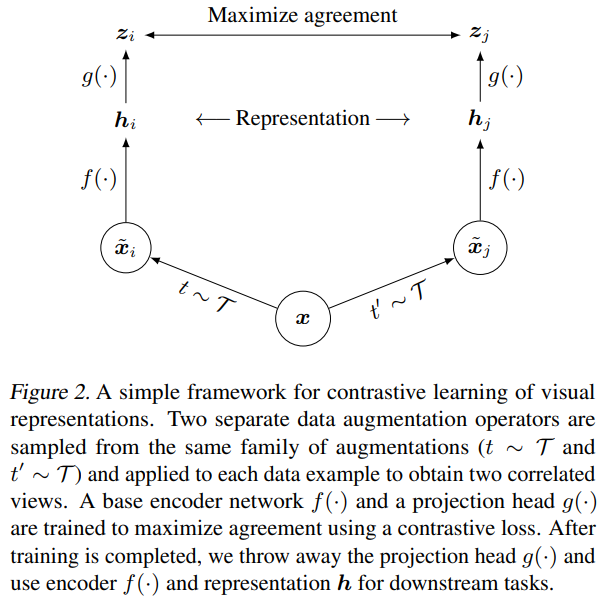
-
첫째로, stochastic data augmentation module은 input 를 2개의 이미지(, )로 augmentation한다. 물론 이 두 이미지 조각은 둘다 에서 나왔으므로 positive pair이다. 논문에서는 random cropping, random color distortion, random Gaussian blur이 3가지 augmentation을 실험했다.
-
와 위에 있는 은 input의 representation을 뽑아내는 base encoder이고 논문에서는 이 인코더로 resnet을 사용했고, averaget pooling까지 진행해주었다고 한다.
-
은 constrative loss가 적용되는 단계인데, 이 단계에서는 1개의 hidden layer가 있는 MLP와 relu함수를 사용했다고 한다.
-
Loss Function
- 이 논문에서는 따로 negative pair를 정해주지 않았다. 대신, N개의 데이터에서 2개의 이미지 조각으로 transformation을 하고, 2N개의 데이터 중에서 2(N-1)개의 조각을 negative pair처럼 사용하였다.
- 결과적으로 positive pair (i, j)에 대한 loss function은 다음과 같다.
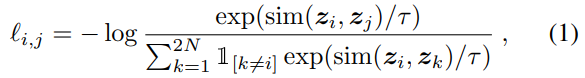
sim 함수는 cosing similarity로 두 이미지가 얼마나 유사한지 계산한다. (필자는 이런 loss function을 사용해서 같은 이미지에서 나온 이미지 조각은 가깝게, 아닌 조각은 멀게 학습하는 것으로 이해했다)
2.2) Training with Large Batch Size
- 이 논문에서는 representation을 memory bank에 저장하는 것이 아닌, 배치 크기를 256애서 8192까지 다양하게 하여 학습을 진행하였다고 한다. 이 학습을 안정화 시키기 위하여, LARS optimizer를 사용했다.
3. Data Augmentation for Contrastive Representation Learning
3.1) Composition of data augmentation operation is crucial for learning good representations
-
이 논문에서는 data augmentation의 성능을 비교하기 위해서 다음의 방법들을 사용하여 비교를 했다.

-
(이 부분은 제대로 이해해 했는지는 모르지만) 논문에서는 ImageNet의 데이터를 사용하였고, 문제는 이 데이터셋의 이미지크기가 일정하지 않은 것이었다 이를 해결하기 위해, 일단 이미지를 crop & reseizing을 해주고 난 후, 이를 모델에 넣어주었다. 이때 모델에서는 augmentation을 실행하게 되는데 branch의 한 쪽 부분만 추가적인 augmentation을 해주는 것이다. 이는 모델의 성능을 떨어뜨리지만 목표는 augmention의 종류별 성능을 비교하는 것이니 그럼에도 불구하고 이렇게 실험을 진행하였다고 한다.
-
2가지의 방법을 결합하여 augmentation을 진행하였고, 그 결과를 비교하여 표로 나타낸 것이 다음 그림이다. 그림에서 볼 수 있듯이 color와 crop의 방법을 적용한 것이 가장 성능이 좋았다.
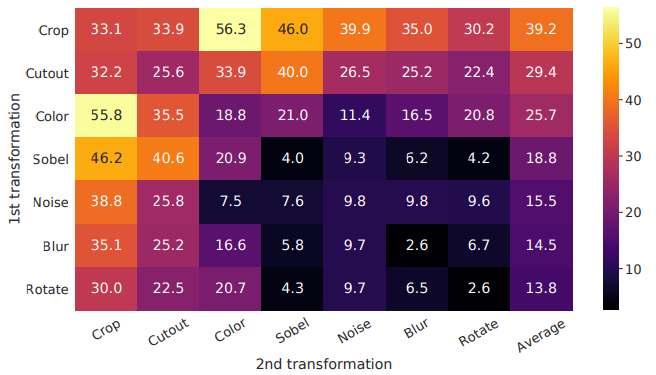
-
저 위의 두 방법이 성능이 좋은 이유는 이미지를 crop만 하게 되면 Figure 6.(a)처럼 crop된 사진들의 색 분포가 비슷할 수 있다. 논문에서는 이를 color distortion을 적용해서 이미지 색의 다양성을 늘리고 학습 성능을 올리는 것으로 해석하고 있다. 실제로 Figure 6.(b)를 보면 색의 분포가 다양해진 것을 관찰할 수 있다.
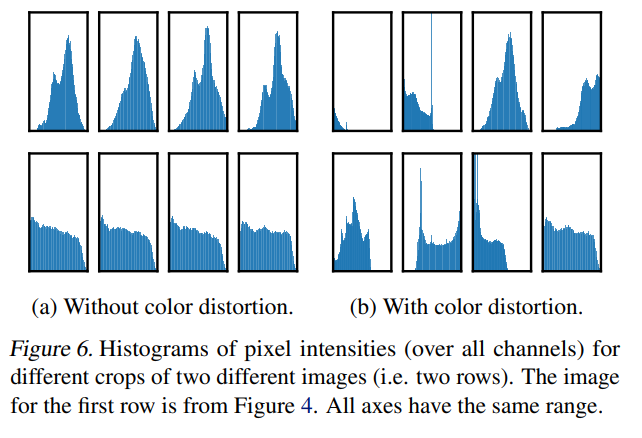
3.2) Contrastive learning needs stronger data augmentation than superivsed learning
-
color distortion의 강도에 따른 모델의 성능을 조사해 보았다. 놀랍게도, distortion의 강도가 높아질수록 SimCLR의 성능은 높아졌다. 반면에 supervised learing의 성능은 오히려 떨어지는 것을 확인할 수 있다. 이를 통해 supervised learning에 도움이 되지 않는 augmentation도 self-supervised learning에는 좋은 영향을 끼칠 수 있다는 것을 알 수 있다.
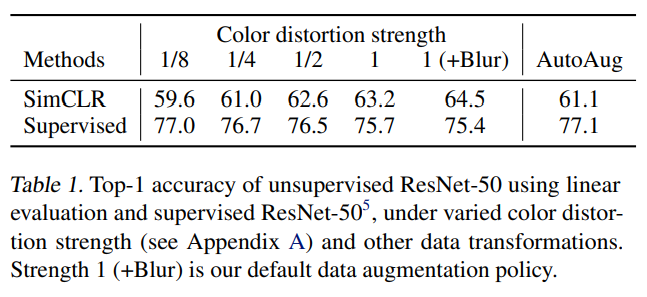
4. Architecture for Encoder and Head
4.1) Unsupervised contrastive learning benefits from bigger models
-
모델의 용량, 파라미터가 많을 수록 성능이 높아진다.
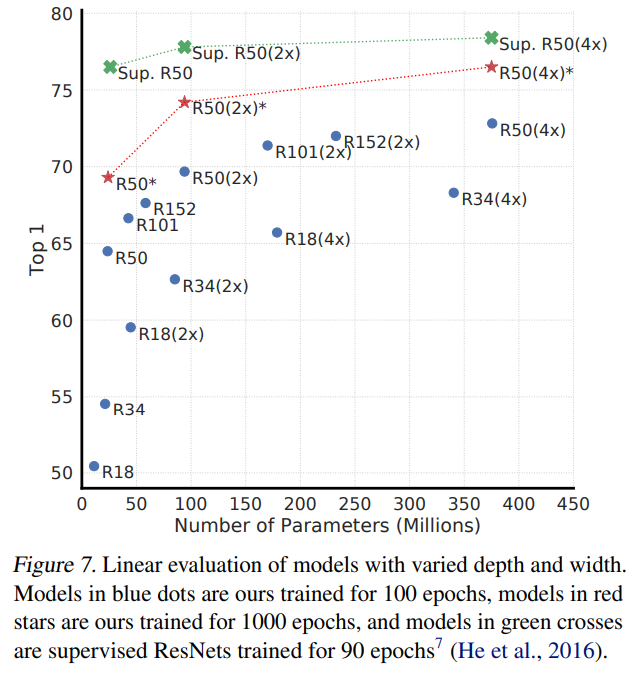
4.2) A nonlinear projection head improves the representation quality of the layer before it
-
이 부분은 Figure 2에서 projection에 해당하는 g(h)에 대해서 설명하였다. g함수는 projection함수인데 이 projection이 linear할 때와 non-linear할때, 없을 때를 비교하여 Figure 8에 정리하였다. Figure 8에서 보면 알 수 있듯이 non-linear projection을 적용했을 때 가장 성능이 좋은 것을 볼 수 있다.
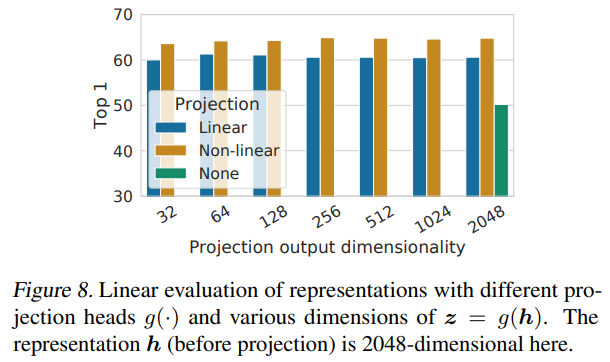
-
또한, projection전의 hidden layer에서의 성능이 그 이후 projection을 적용한 layer보다 성능이 좋았는데, 이는 hidden layer가 더 좋은 representation을 포함하는 것을 뜻한다. 논문에서는 g 함수는 transform에 대해서 변함이 없게 학습이 되어야하고, 이로 인해 downstream tas에 유용한 정보가 이 과정에서 삭제된 것으로 추측했다.
-
이 추측이 맞는지 확인해보기 위해 실험을 진행했고, Table 3에서 보면 이 추측이 맞다고 판단할 수 있다.

5. Loss Function and Batch Size
5.1) Normalized cross entropy loss with adjustable
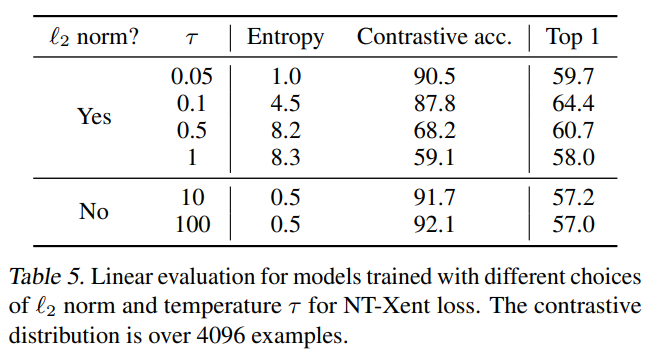
- 이 논문에서는 NT-Xent loss를 사용하였고, 왜 이 loss를 사용하였는지 설명하는 부분이다. NT-Logistic, MarginTriplet loss와 비교하였고, NT-Xent loss가 가장 성능이 좋은 것으로 나타났다. 이는 NT-Xent loss의 normalization과 temperature를 잘 조절했기 때문이다.(이 부분에 대해서 부연 설명이 있었지만 잘 이해하지 못했다...ㅠㅠ)
Table 4에서는 NT-Xent loss를 다른 loss function과 비교하였고,Table 5에서는 normalization과 temperature에 따른 모델의 성능을 정리하였다.

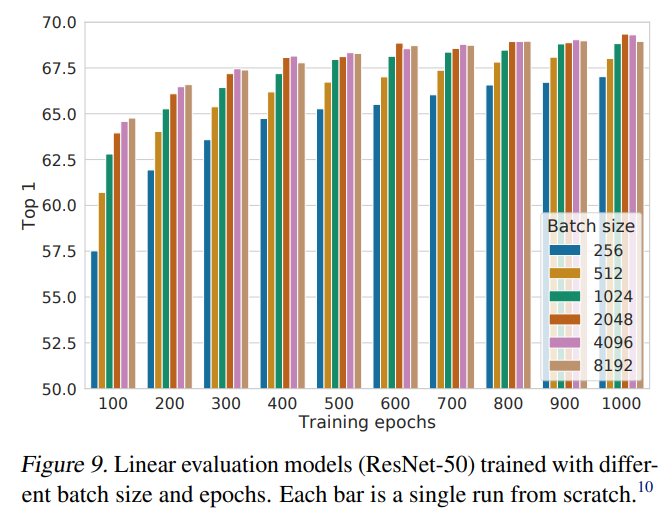
5.2) Contrastive learning benefits from larger batch sizes and longer training
- 이 부분은 배치의 크기에 따른 모델의 성능을 정리한 부분이다. 제목에서 유추할 수 있듯이 배치크기에 따라 모델의 성능이 향상되는 것을 관찰할 수 있었으며 이를
Figure 9에 정리하였다.
참조
