0. Abstract
- 기존의 CNN모델보다 이미지를 패치 단위로 나누어 학습한 transformer모델이 이미지 분류에서 좋은 성능을 낼 수 있다는 것을 보여주는 논문이다.
1. Introduction
- Transformer는 자연어 처리에서 좋은 성능을 보여준 구조이고 이 논문에서는 이를 computer vision에 적용하였다. viT에서는 이미지를 패치 단위로 잘라 이를 sequence로 해석하고 이 sequence of linear embeding을 transformer의 input으로 적용했다.
- Transformer에서는 CNN이 가지고 있는 translation equivarance & locality와 같은 inductive bias가 낮다. 따라서 이 모델이 충분한 성능을 내기 위해서는 그만큼 많은 데이터를 소비해야한다. 이 논문에서는 ImageNet-21k 혹은 JFT-300M 데이터 셋에서 좋은 성능을 보여 주었다고 한다.
What is inductive bias?
inductive bias란 training 과정에서 보지 못한 데이터에서도 좋은 성능을 낼 수 있도록 모델에 주어지는 가정이다. 예를 들면 CNN에서는 인접한 픽셀끼리 정보를 담기 위해(locality) 3차원의 filter를 사용하였다.
3. Method
3.1 Vision Transformer
-
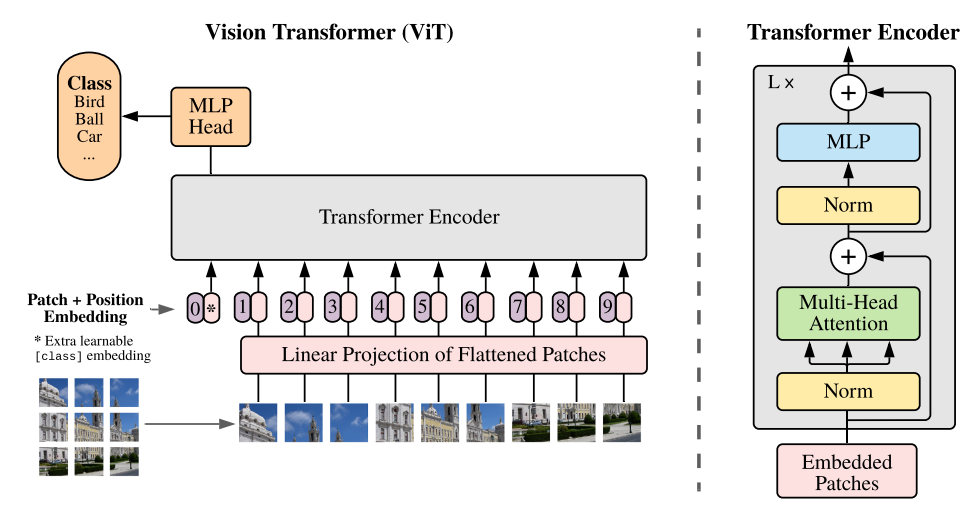
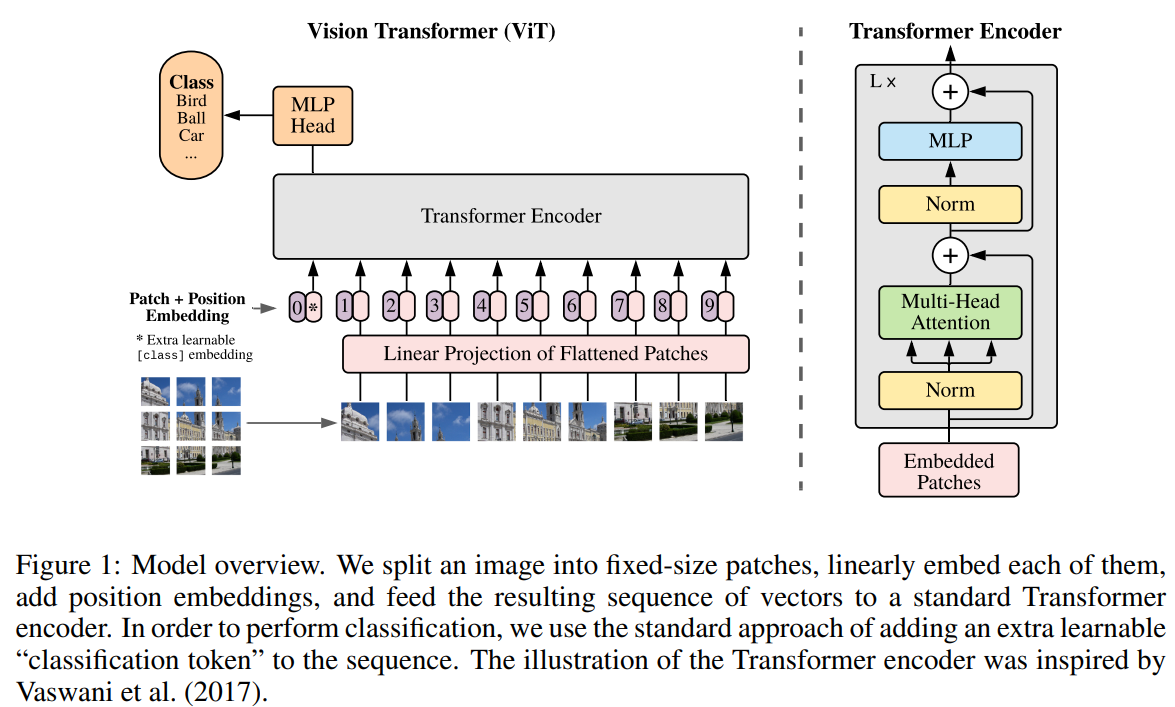
모델의 기본 구조
-
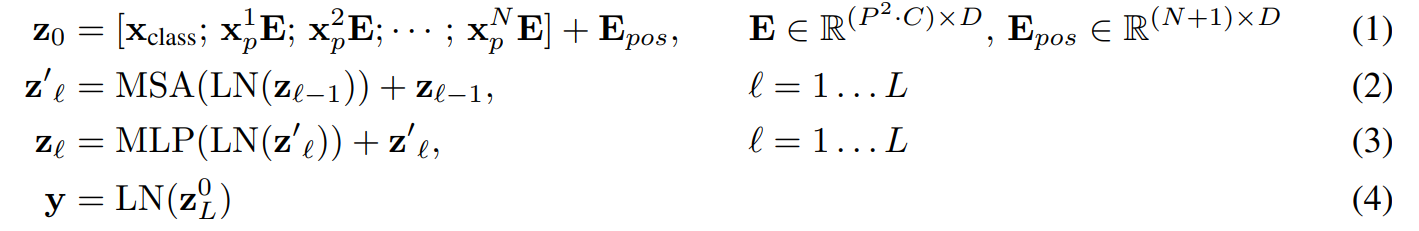
-
만약 input으로 H, W, C차원의 가 들어갔다면(H, W, C는 각각 이미지의 높이, 너비, 채널) transformer는 이 이미지를 pxp단위의 patch로 나누어 각각을 sequence로 간주한다. 즉 N = HW/개수의 를 가지고 각각 p, p, C 차원이다.
-
equation(1)을 보면 알 수 있듯이, embedded patch를 만들기 위해서 들에 class token과 position embedding을 추가해주고 D차원으로 매핑해준 것을 알 수 있다. 추가적으로 position embedding의 차원이 N, D가 아닌 N+1, D인 것은 class token때문에 차원이 늘어났기 때문이다.
-
-
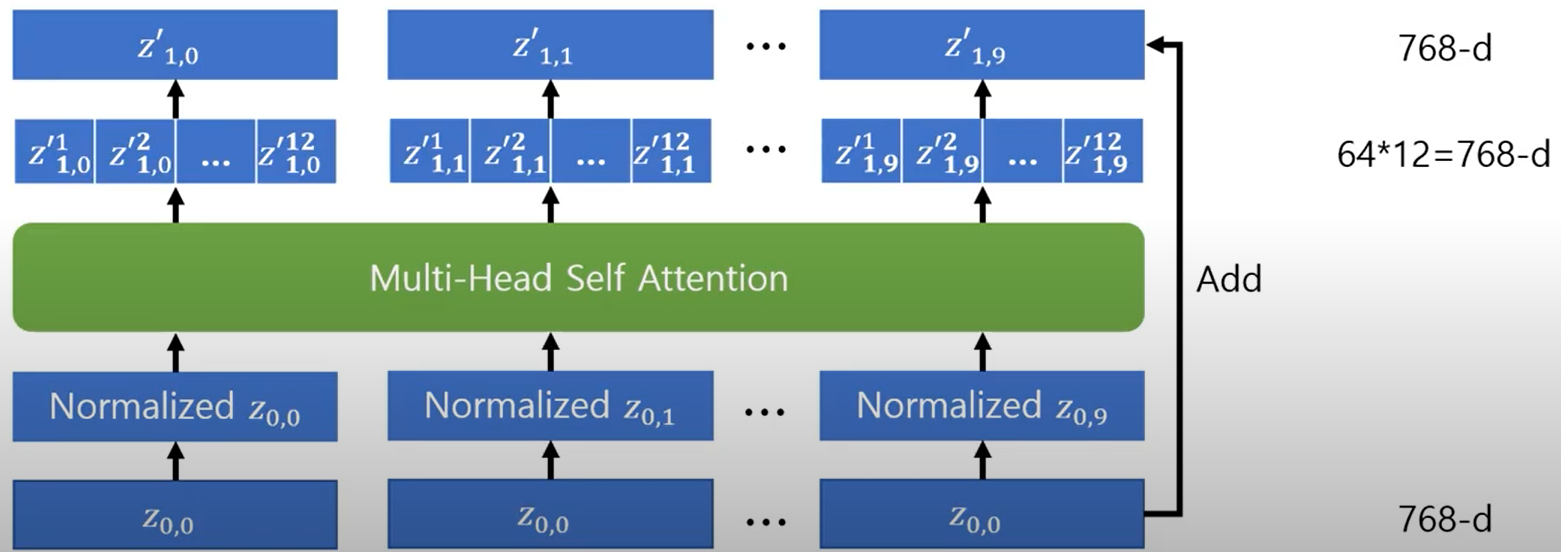
자연어 처리에서 쓰였단 normalization의 경우 attention block다음에 적용이 되었지만 viT의 경우 normalization이 attention block 전에 적용이 된다는 차이점이 있다.
3.2 Fine-Tunning and Higher Resolution
- 논문에서는 모델을 우선 엄청 큰 데이터 셋으로 학습시킨후 더 작은 데이터 셋을 잘 분류하기 위해 fine-tuning을 진행하였다고 한다. 이를 위해 pretrained된 head를 제거하고 0으로 초기화된 D x K layer를 대신 넣어주었다고 한다.
- 높은 해상도의 이미지를 학습할 때는 패치의 크기가 정해져 있으므로, sequence가 길어질 수 밖에 없다. 이런 경우, pretrained된 position embedding이 의미를 잃을 수 있다. 따라서 원래 이미지의 크기와 위치에 따라 pre-trained postion embedding에 interpolating을 적용한다.
참고

호수공원