
Localization / Detection / Segmentation

단순히 딥러닝에서 쓰이는 CNN모델로는 우리가 이때까지 Classification만을 했다면, 더 나아가 컴퓨터비전 알고리즘을 통해 이미지의 객체 탐지/검출하는 작업을 할 수 있게 되었다.
위의 그림을 보게되면, Localization / Detection / Segmentation이라고 나와 있는데 먼저 정의부터 알아보자
Localization은 이미지에서 단 하나의 객체의 위치를 Bounding Box로 지정하여 찾게 된다.
다시말해서, 이미지내에 여러 개의 객체가 있어도 1개의 객체에 초점을 맞추어 해당 객체를 찾게 된다.
Object Detection(Detection)이란, Localization에서 더 나아간 기법으로 하나의 객체에 국한되는 것이 아닌, 여러 개의 객체들에 대한 위치를 Bounding Box로 지정하여 찾는 기법이다. 당연히 localization보다는 어렵다.
Bounding Box란, 객체의 정확한 위치를 알려주는 box라고 생각하면 되는데 이는 localization과 detection 모두 box를 찾아야한다.
이는 모델이 Bbox(Bounding Box)의 좌표값을 회귀를 통해 알아내야하며, Bbox내의 있는 객체를 추출하여 데이터로 예측하게 되는데 이 과정은 딥러닝 모델에서와 같다. 이러한 과정이 한번에 이루어져야한다.(2-Stage Detector를 기반으로 설명)
Segmentation이란, Pixel레벨 detection을 수행하는 기법이다.
1-Stage / 2-Stage Detector
2-Stage Detector
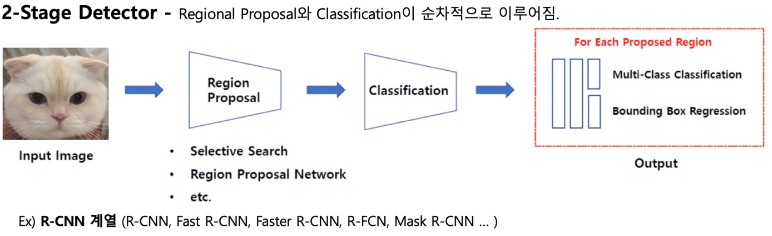
2-Stage Detector는 Regional Proposal과 Classification이 순차적으로 이루어지는 모델 종류이다.
Regional Proposal이란, 이미지내에서 객체가 있을만한 후보 Bbox를 추정하는 것으로 대표적인 알고리즘으로 Selectivesearch 알고리즘이 있다.(자세한 설명은 다음에 있다.)
즉, Bbox의 후보군을 뽑아 다시 network에 돌려서 확실하게 Bbox의 좌표와 class값까지 알아내면서 정확도가 높지만 느리다는 단점이 존재한다.
1-Stage Detector
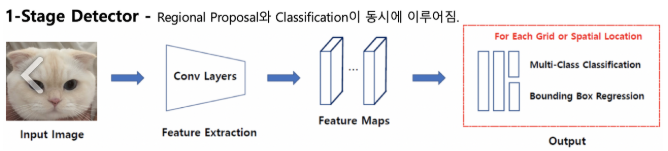
1-Stage Detector는 2-Stage와는 달리, regional proposal과 classification이 동시에 이루어지므로 한번에 Bbox 객체 좌표와 class까지 출력하게 된다.
당연히 2-Stage보다는 빠르지만 정확도 측면에서 1-Stage보다는 낮다.
대표적으로 RetinaNet, Yolo등이 있다.
Object Detection의 난제
Classification과 Bbox좌표
이미지에서 여러 개의 물체를 classification함과 동시에 1-stage같은 경우 동시에 위치까지 찾아내야하기 때문에, Loss function이 더 복잡해질 수 밖에 없다.
다양한 object
이미지내에서 다양한 객체들을 feature map에서 detect를 수행해야하는데 객체가 서로 섞여 있으면 제대로 수행하기 어렵다.
Detect time
실시간 영상 기반에서 detect해야 하는 요구사항이 증대하고 있다.
Background
실제로 이미지를 보게되면 객체보다는 background가 차지하는 경우가 대부분이므로 명확하지 않은 이미지가 있을 수 있다.
Object detection 예시
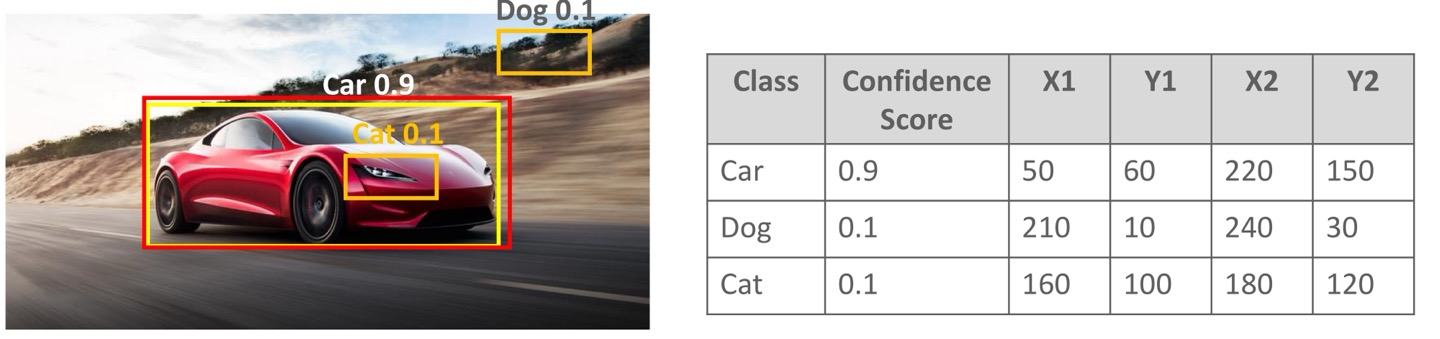
표에서 Confidence score는 Bbox의 객체를 predict한 값이 label과 비교했을때의 확률이고 x1,y1은 Bbox의 왼쪽 상단의 꼭지점이고 x2,y2는 오른쪽 하단의 꼭지점이다.
영상에서의 원점은 이미지의 왼쪽 상단의 꼭지점부터 시작한다는 것을 알고 있다면 쉽게 이해할 수 있다.
표에서는 (x1,y1),(x2,y2) = (50,60),(220,150)일때 Confidence score값이 가장 높고, 실제로 이미지를 보았을때도 정확하게 탐지한 것을 볼 수 있다.
그렇기 때문에 Bbox는 (50,60),(220,150)이 가장 적합하다고 볼 수 있다.
Region Proposal
Sliding Window
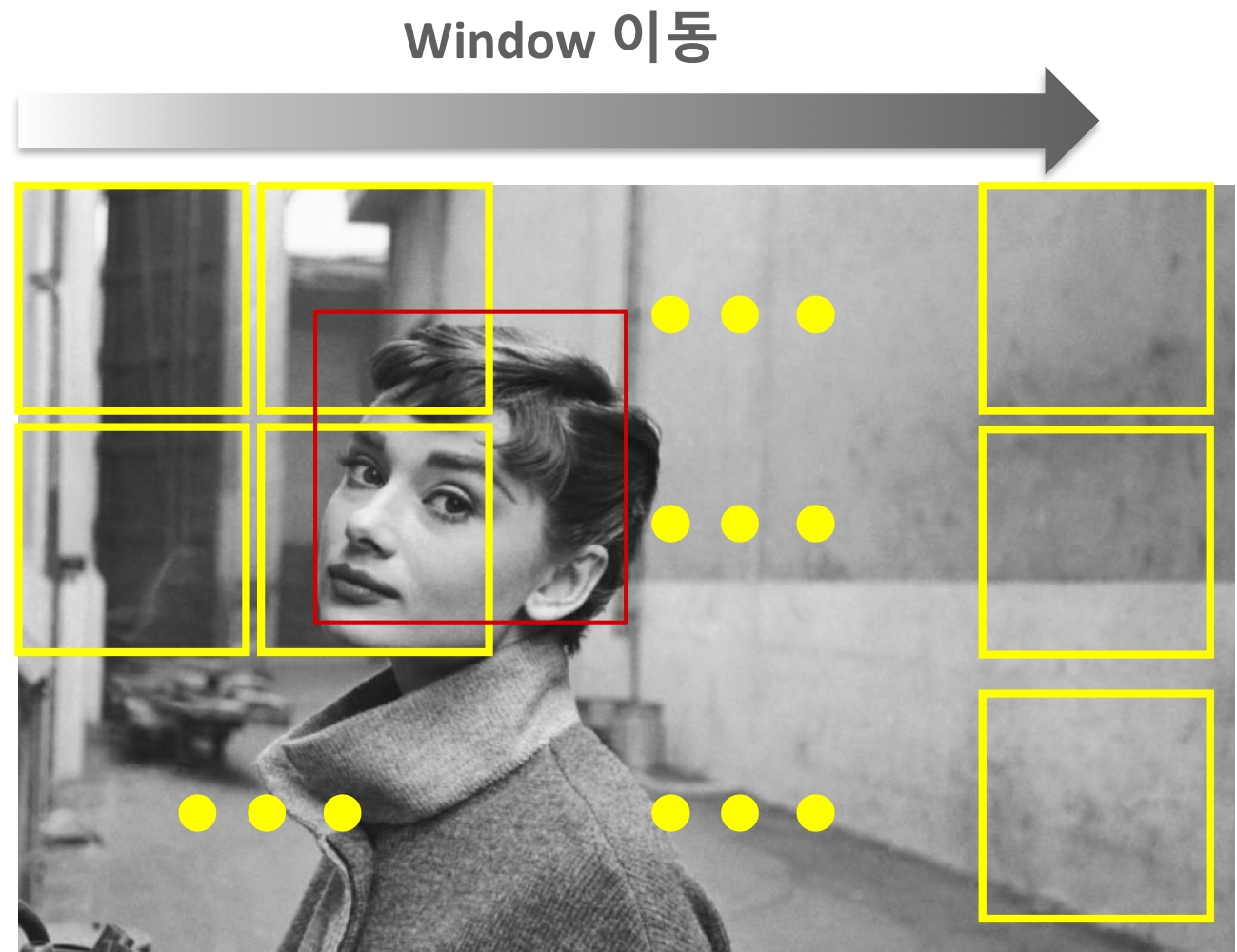
Sliding Window는 Bbox를 알기 위한 알고리즘으로 실제로 코테에서도 많이 출제되는데, Bbox를 왼쪽 상단에서부터 오른쪽 하단으로 이동시키면서 객체를 detection하는 방식이다.
또한, 원본 이미지의 resolution은 고정하고 scale을 변경한 여러 이미지를 사용하는 방식도 존재한다.
하지만 이는 객체가 없는 영역까지 계산을 해야한다는 단점이 존재하며 수행시간이 오래걸리고 객체의 검출 성능이 상대적으로 낮고 한번의 sliding을 하기 위해서 고정된 Bbox를 사용해야한다는 단점이 있다.
Slding Window는 Region Proposal기법의 등장의 시발점으로 활용도는 떨어졌지만, 객체 탐지를 위한 기술적인 토대를 제공해주었다.
Selective Search

Region Proposal방식으로 이미지에서 객체가 있을만한 후보영역을 찾게 되는데 segmentation을 이용한다.
Process

-
초기에는 수많은 이미지에서 객체들이 1개의 개별 영역에 담길 수 있도록 over segmentation을 해준다.
over segmentation이란, 객체로 분리하는 영역을 지나치게 세분화하여 객체나 영역을 식별하는 것을 말한다. -
Hierarchial Grouping Algorithm을 통해 유사도가 높은것끼리 하나의 segmentation으로 합쳐준다.

-
R은 ~ 최초 segmentation을 통해서 나온 초기 n개의 후보 영역들이다.
-
S는 영역들 사이의 유사도 집합이다.
알고리즘 순서는 다음과 같다.
-
색상, 무늬, 크기, 형태 등을 계산하여 각 neighboring region의 와 의 similarity를 계산한다 -->
-
각 neighboring 영역들 사이에서 가장 similarity가 높은 값을 얻는다. -->
-
해당하는 와 를 합쳐 새로운 영역 를 만든다. -->
-
S에서 와 와 관계가 있는 값들은 모두 삭제한다.
-
새로운 영역 를 neighboring 영역들과의 similarity를 구하고 새로운 를 생성한다.
-
새로운 영역의 유사도 집합 와 영역 를 기존의 S, R 집합에 추가한다.
-
이 과정을 여러번 반복한다.
- Segmented region proposal을 사용하여 candidate object Bbox를 생성한다.
쉽게 말하면, 객체의 위치를 표현하기 위해 bounding box(경계 상자)를 만들어 제안하는 것입니다.
GitHub_selectivesearch에 selectivesearch 라이브러리를 이용해서 사용해보았다.
IOU(Intersection Over Union)
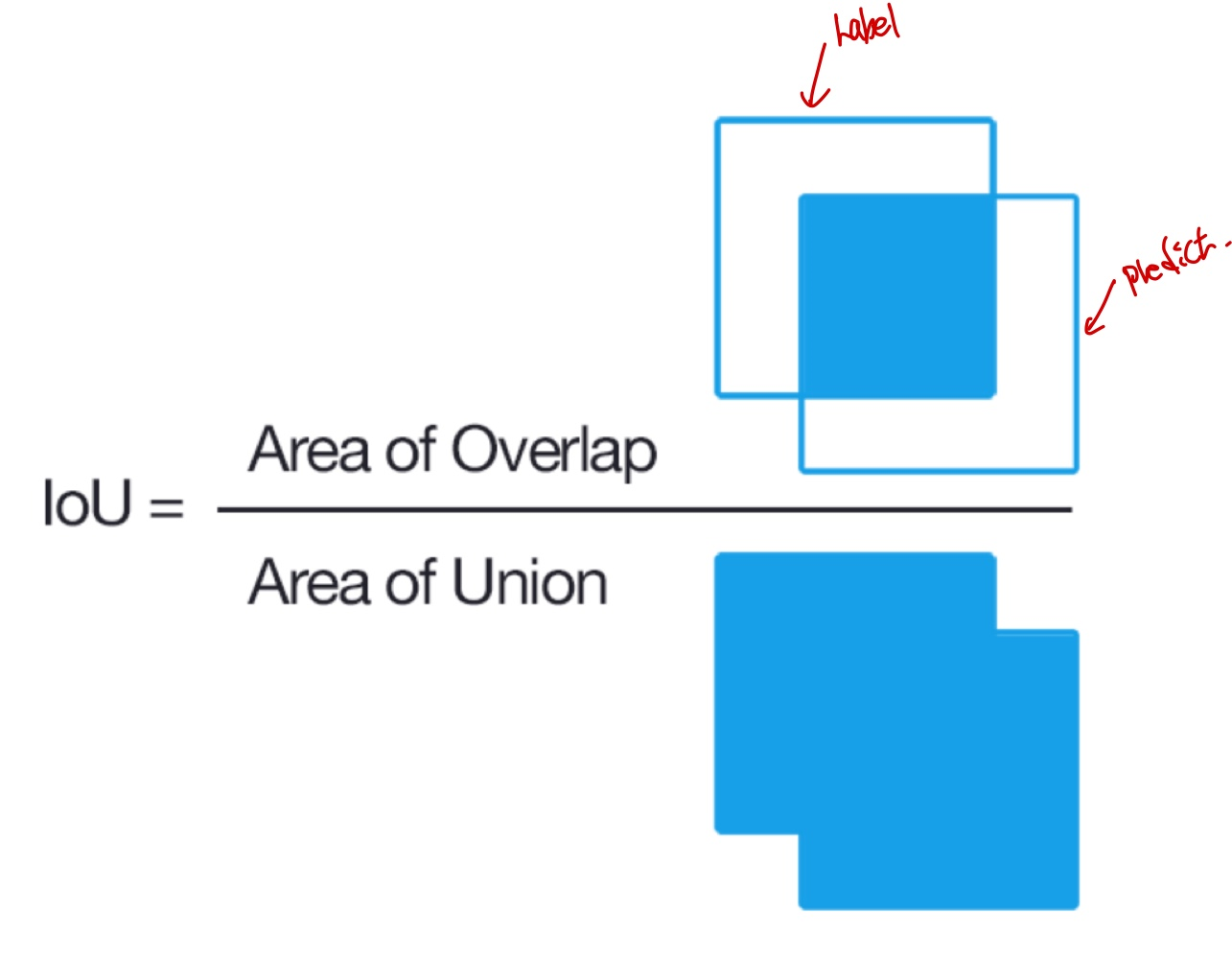
IOU는 모델이 predict한 Bbox와 label의 Bbox가 얼마나 겹치는가를 나타내는 비율이다.
분모는 predict와 label이 합집합 면적이고, 분자는 predict와 label이 겹치는 면적이다. 이 식의 output값은 그러면, 전체 면적 대비 Bbox가 겹치는 비율로 [0,1]값을 가지게 된다.
1에 가까울수록 predict한 Bbox의 성능이 좋다는 것을 알 수 있다.
GitHub_IOU에 IOU를 구현했다.
Object Detection에서는 개별 Object에 대한 detection 예측이 성공하였는지의 여부를 IOU로 결정한다.(IOU로 결정하니 Bbox로 예측 여부의 성공을 결정)
강의에서 말하길, PASCAL VOL Challenge에서 사용된 기준을 적용하여 IOU가 0.5이상이면 예측 성공으로 인정하고 COCO challenge에서는 여러 개의 IOC 기준을 변경해 가면서 예측 성공을 적용한다고 한다.
NMS(Non Max Suppression)
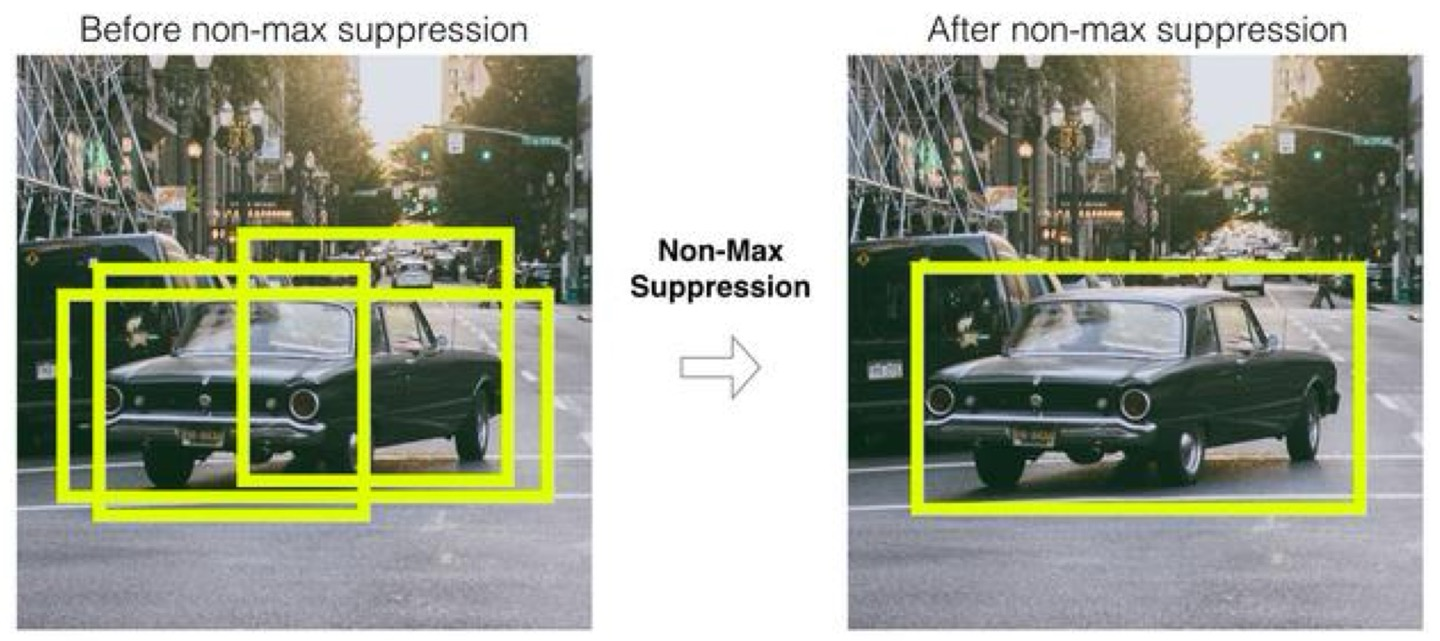
Object Detection의 알고리즘은 객체가 있을 만한 위치에 많은 Bbox를 수행하는 경향이 강하기 때문에 비슷한 위치에 있는 Bbox를 제거하고 가장 적합한 Bbox를 선택해야한다.
NMS 알고리즘은 이러한 과정을 수행할 수 있다.
NMS알고리즘은 2-stage에서 쓰는 알고리즘으로, process는 다음과 같다.
-
Bbox에서 Detect된 Bbox별로 특정 Confidence threshold이하 Bbox는 먼저 제거한다.
-
가장 높은 confidence score를 가진 Bbox순으로 내림차순 정렬하고 아래의 로직을 모든 Bbox에 순차적으로 적용한다.
높은 confidence score를 가진 Bbox와 겹치는 다른 box를 모두 조사하여 IOU가 특정 threshold 이상인 Bbox를 모두 제거한다.
이 로직은 중복된 Bbox를 제거하는 것이며 IOU의 threshold값을 너무 낮게 설정하면 다른 객체를 탐지한 Bbox를 제거할 수 있기 때문에 threshold값을 최적화시켜야한다. -
남아있는 Bbox만 선택한다.
mAP(mean Average Precision)
mAP는 실제 객체가 detected된 recall의 변화에 따른 precision의 값을 평균한 성능 수치로 Object Detection의 성능을 평가하는 지표이다.
mAP를 알기 위해서 Precision과 Recall을 먼저 알아보자
Precision(정밀도)
정밀도의 정의는 predict를 Positive로 한 대상 중에 predict와 label값이 Positive로 일치한 데이터의 비율을 뜻한다.(predict가 Positive인 것이 전제조건)
Object Detection에서는 객체에 Bbox로 detect한 상태에서 실제로 그 객체가 bird라면 predict한 값이 bird인 비율을 나타낸다.
즉, 검출 알고리즘이 검출 예측한 결과가 실제 객체들과 얼마나 일치하는지를 나타내는 지표이다.
Precision의 수식은 ** precision = 이다.**
Recall(재현율)
재현율의 정의는 label값이 Positive인 대상 중에 predict와 label값이 Positive로 일치한 데이터의 비율을 뜻한다.(label값이 Positive인 것이 전제조건)
Object Detection에서는 객체들을 빠뜨리지 않고 얼마나 정확히 검출 예측하는지를 나타내는 지표이다.
Precision의 수식은 ** precision = 이다.**
수식을 보고 좀 더 정확히 말하자면 TP는 Bbox로 검출한 것이 전제조건이고, predict한 값과 label값이 맞으면 값이 +1되는것이다.
만약 predict한 값과 label값이 맞지 않으면 FP가 +1이 되는 것이다.(필자는 이것이 헷갈렸다.)
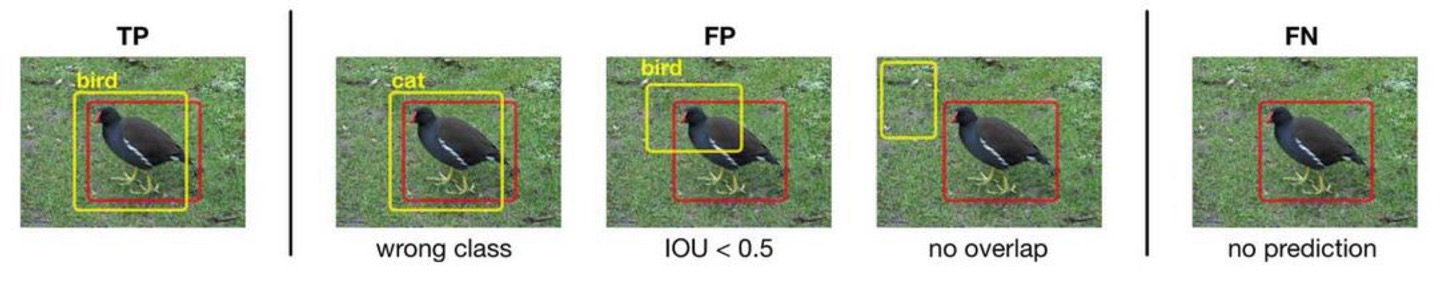
정리하자면, 우리가 알고 있는 Confusion Matrix(오차행렬)에서 TN은 쓰이지 않고, TP는 Bbox로 detect한 상태에서 객체가 predict한 값과 label값이 맞는 것이고 FP는 Bbox로 detect한 상태에서 객체가 predict한 값과 label값이 맞지 않은 상태, FN은 Bbox를 치지 않은 상태를 말한다.
Confidence threshold값에 따른 Precision-Recall 변화
소제목에서 그대로 말한것과 같이, Confidence의 threshold값에 따라서 precision과 recall값은 변화한다.
만약, threshold가 낮다고 한다면 Bbox의 개수가 threshold값이 높은 값보다 더 많을 것이다. 그러면 FP의 값은 커지고, FN의 값은 작아질 것이다.(앞에서 설명했으니 이해했다고 가정한다.) FP의 값이 커지게 되면 precision의 값은 작아지고, FN의 값이 작아지면 recall의 값은 커지게 될 것이다.
threshold가 크다고 한다면, FN의 값은 커지고 FP의 값은 작아진다.
그러면 precision의 값은 커지고, recall의 값은 작아지게 된다.
Precision/Recall Trade-Off
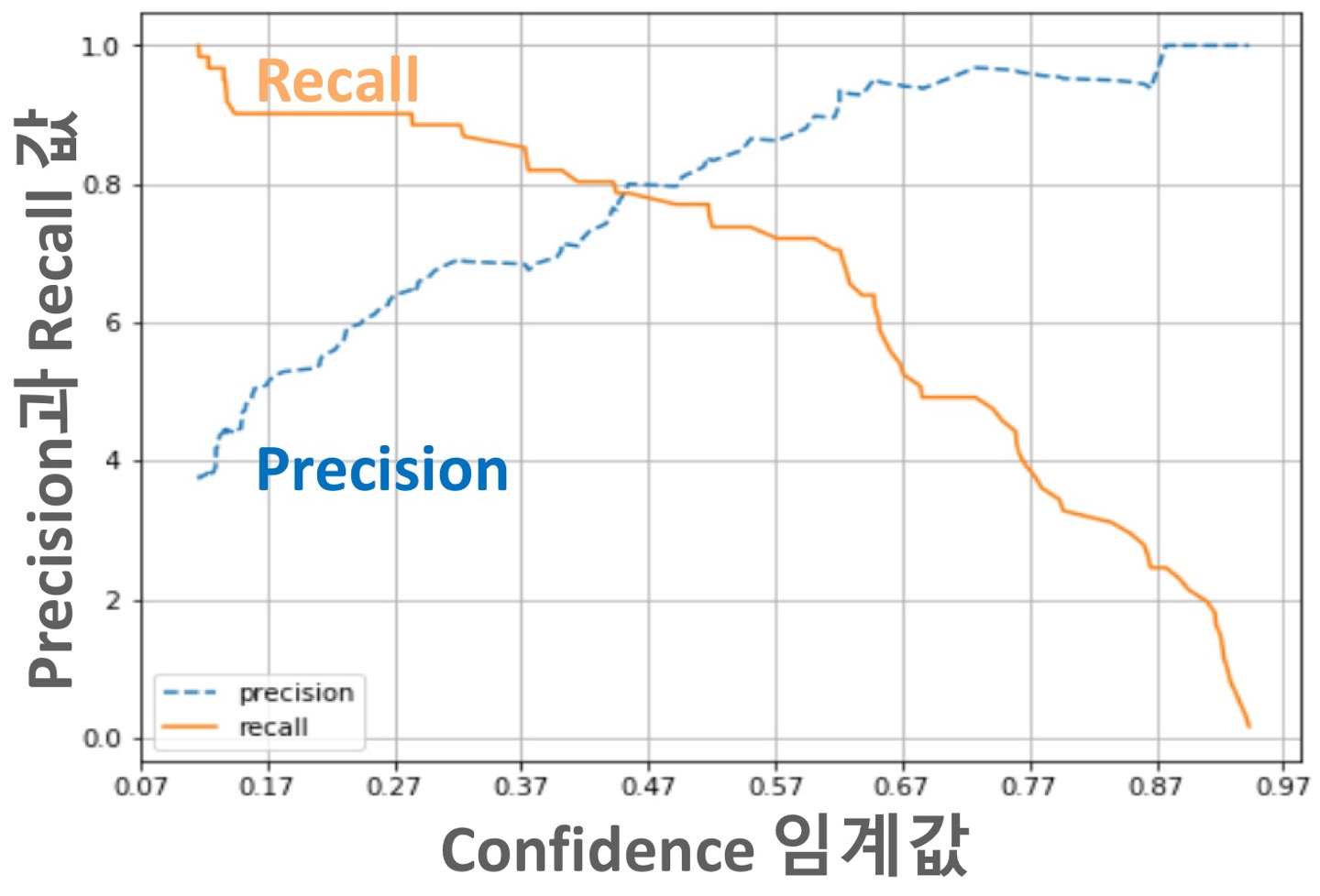
앞선 threshold값에 따른 Precision과 recall의 변화에 따른 지표를 예시로 나타냈다.
그래프를 통해 우리는 recall의 값이 크면, precision 값이 작아지고 반대로 recall의 값이 작으면 precision의 값이 커지는 것을 볼 수 있다.
이를 precision/recall trade-off라고 부릅니다.
Precision-Recall Curve
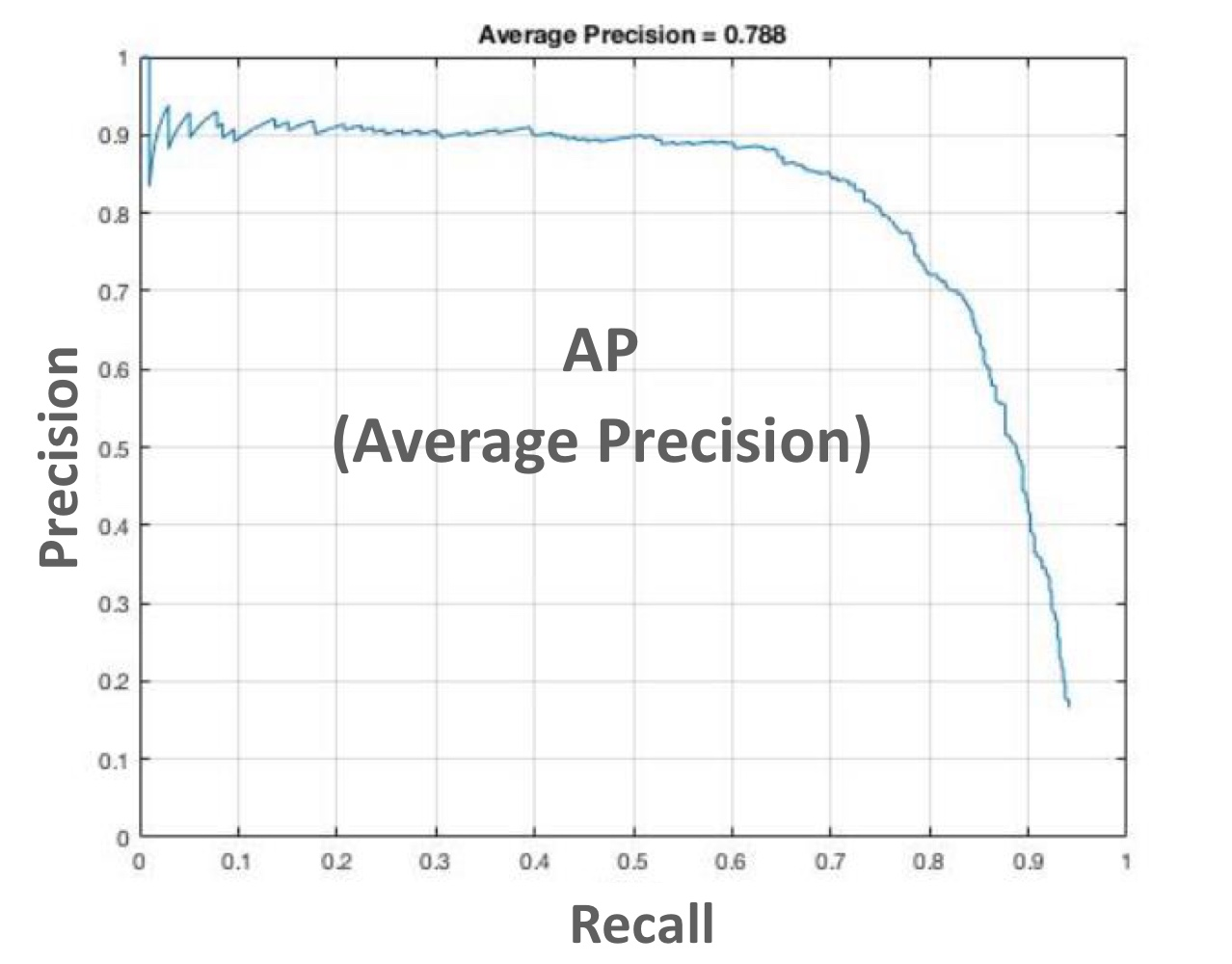
recall값에 따른 precision의 변화량을 나타낸 곡선을 precision-recall curve라고 불리우고 이 넓이 값을 우리는 AP(Average Precision)라고 불리웁니다.
AP는 이미지내에서 한 개의 객체에 대한 성능 지표를 나타내는것이고 mAP는 이미지내에서 모든 객체에 대한 성능 지표를 나타냅니다.(객체마다의 AP값을 평균화해주면 됩니다.)
문제를 통해 알아보자
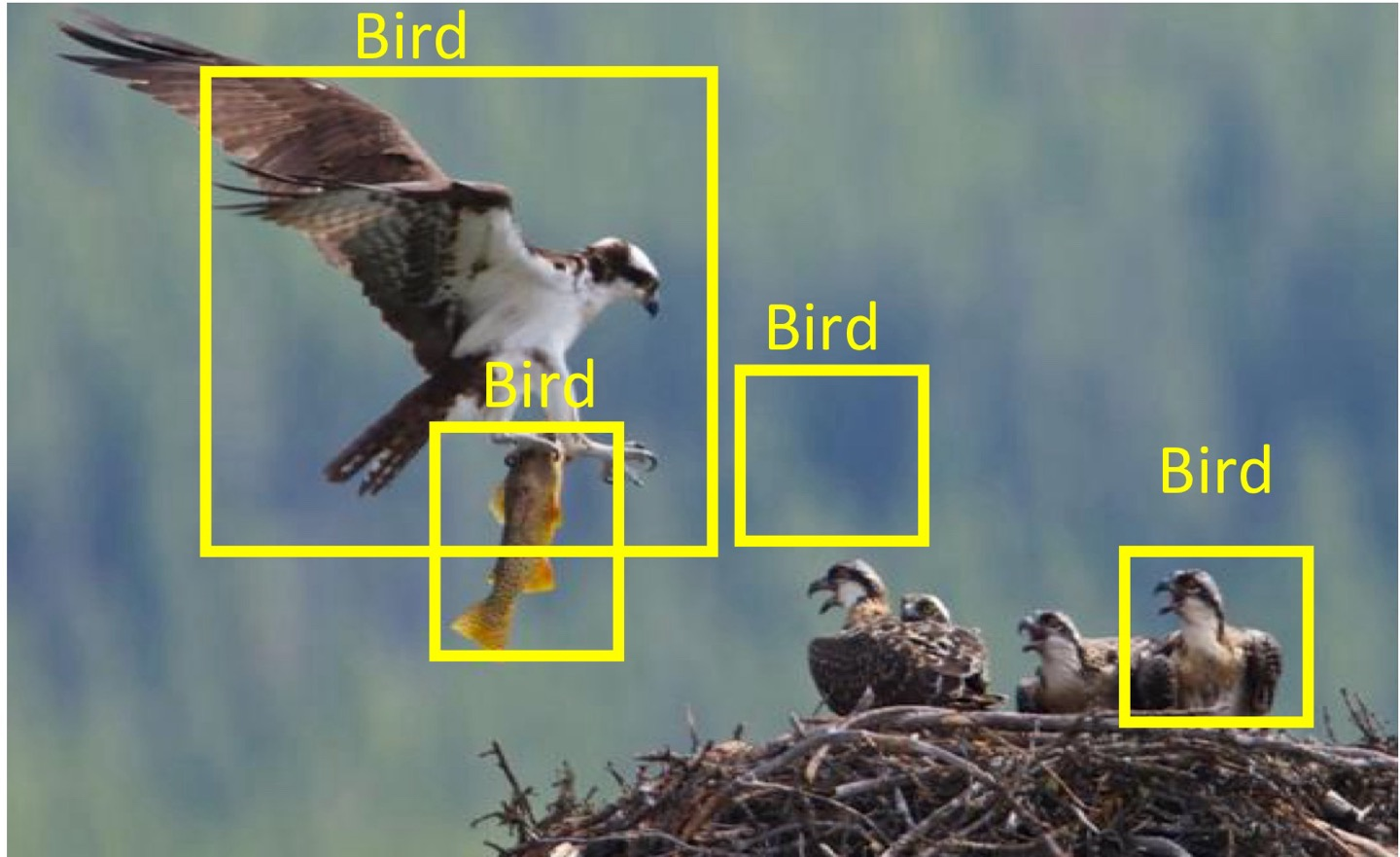
TP의 값은 일단 Bbox가 detect된 상태에서 predict와 label값이 일치한 것이니 값이 2이다.
FP의 값은 Bbox가 detect되었지만 predict와 label값이 일치하지 않은 것으로 물고기를 bird로 잘못 predict한 것으로 값과 background를 bird로 predict한 값 2이다.
FN의 값은 객체를 Bbox로 detect하지 못한 값으로 3이다.
그렇다면 precision의 값은 , recall의 값은 가 된다.
