Abstract

image denoising을 CNN을 활용하는데, 이때 Batch Normalization과 Residual Learning을 이용하여서 train의 속도 향상과 denoising의 performance의 향상에 도움이 되었다고 한다.
또한, 특정한 noise level에 한정적이였던 이전 Model과는 달리, DnCNN은 unknown noise level로 범위를 넓혀 denoising을 수행하였다고 한다. 이때의 noise는 AWGN(Additive White Gaussian Noise)를 말한다.
Residual Learning을 통해 Gaussian-Denoising, Single Image Super-Resolution, JPEG Image Deblocking과 같은 several task에도 사용된다고 한다.
Introduction
Paragraph 1

Image Denoising은 모든 practical한 application에서는 무조건 필수적으로 쓰이는 기술로써 현재까지도 중심 topic중의 1개입니다.
denoising을 어떻게 하느냐를 일단 알아볼텐데, 먼저 y = x + v로 정의하고 있습니다.
이때 y는 noisy observation이라고 말하는데, y는 x라는 clean image, v는 gaussian noise라고 합니다. 그렇다면 y는 x가 되기 위한 알고리즘을 고심해봐야한다고 합니다.
Gaussian Noise는 우리가 가장 흔히 볼 수 있는 noise입니다.

최신에 나온 NSS, BM3D 등과 같은 method들을 보게 되면 prior information을 받게 됩니다. (아직 나오지는 않았지만 이때의 information은 noise의 level을 의미합니다.)
하지만 이러한 prior information을 받는 method는 2가지의 문제점이 있다고 합니다.
-
test단계에서 복잡한 최적화 과정으로 인해 denoising처리 시간이 오래걸린다고 합니다. 왜냐하면 베이지안 관점으로 최적화가 이루어져야하니까요.
-
non-convex하며, parameter가 정해져있기 때문에 성능이 좋지 않을 수도 있습니다. non-convex란, 무한히 넓은 공간에서의 함수에서 여러 곳의 local minimum 중의 얻가 global minimum인지 찾기 굉장히 어려운 것을 의미합니다. 그렇기 때문에 시간도 굉장히 오래걸리게 되는 원인 중 1개입니다.
Paragraph 2

DnCNN은 feed-forward CNN을 통해서 noisy image에서 noise를 분리시킨다고 합니다.
feed-forward CNN이란, input data가 한 방향으로만 처리되는 구조로 VGG를 예시로 들 수 있겠네요. 다른 신경망 구조로는 RNN, Transformer 등이 있겠네요.
CNN을 사용하는 이유는 3가지가 있다고 합니다.
-
capacity와 flexibilty의 증가로, image의 feature를 추출하는데 효과적이라고 합니다.
-
많은 Regularization과 Learning method의 발전으로 denoising performance를 향상 시켜준다고 합니다. 이 DnCNN은 Batch Normalization과 Residual Learning을 특히 강조합니다.
-
CNN은 병렬 프로그래밍이 매우 적합하다고 합니다. 이로 인해 run time이 매우 빠르게 진행된다고 합니다.
Paragraph 3

DnCNN은 denoised image를 추출하는 것이 아니라 residual image v를 predict하는 것으로 설계 되었다고 합니다.
즉, noisy image가 clean image로 되도록 하는 것이 아니라, noise를 알도록 noisy image - clear image를 통하여 noise를 알도록 하는 것 입니다.
이것은 residual learning을 이용하는 것으로, 이후 자세히 설명합니다.
Batch Normalization과 Residual Learning을 같이 사용함으로써 run time speed와 performance가 좋아졌다고 합니다. 이는 2가지를 같이 사용해야 앞서 말한 것들이 좋아짐을 말합니다.
또한, DnCNN과 TNRD의 connection으로 gaussian denosing에 국한되는 것이 아닌, SISR, JPEG image deblocking의 task까지 다룰 수 있다고 합니다.
(이 부분은 다루지 않습니다.)
Paragraph 4

single DnNN으로도 위의 3가지의 task들을 수행할 수 있다고 하며, 3가지들을 수행할 수 있는 이유는 end-to-end mapping 학습이 가능, batch norm, residual, specific noise method들과 달리 좋은 performance를 보여주기 때문이다.(end-to-end 말고 같은 말 반복,,)
Related Work
Residual Learning and Batch Normalization

A. Deep Neural Networks for Image Denoising 부분은 앞서 말한 것과 별반 다르지 않기 때문에 제외했습니다.
먼저 Residual Learning에 대한 부분입니다. ResNet 리뷰/ 코드 구현 참고
Residual Learning은 원래 degradation의 문제를 해결하기 위해서 나온 method로 원래 참조하지 않았던 mapping과는 달리 학습하기가 더욱 쉬워졌으며, 이로 인해 매우 deep한 network도 학습이 가능해졌다고 합니다.
residual mapping, ResNet에서는 identity shortcut이겠네요. 이것을 building block마다 사용하지만, DnCNN은 residual image를 predict하기 위해서 1개의 residual unit을 이용한다고 합니다.
다음, Batch Normalization 입니다. Batch Normalization 참고
mini-batch gradient descent를 사용하여도, internal covariance shift 문제를 해결하지 못했다고 합니다.
internal covariance shift란, 각 layer의 input distribution이 학습중에 변하는 현상을 말합니다. 왜냐하면 input값이 다를 수 있는 경우가 훨씬 더 많기 때문입니다.
Batch Normalization은 위의 문제를 해결합니다.
말 보다는 식으로 보여드리는게 나을거 같아서, 필기한 것을 첨부하겠습니다.

위의 residual learning과 batch normalization의 합작품으로 훈련이 stable하며 denoising의 performance가 더 좋아졌다고 다시 한번 강조합니다.
The Proposed Denoising CNN Model

CNN model을 어떤 특정한 task를 수행하기 위한 2가지의 step이 있다고 합니다.
첫번째는 network 구조를 설계하는 것인데, DnCNN은 image denoising에 suitable하기 위해서 VGG를 개편하였고VGG 논문 리뷰/ 코드 구현 SOTA method들을 사용하여서 effective한 patch size에 기반한 layer의 최적화된 depth를 찾았다고 합니다.
두번째는 training data로 하여금 모델 훈련인데, 이 역시 Batch Normalization과 Residual Learning을 말하고 있습니다.
Network Depth

network를 설계에 대해서 말해주고 있는데, pooling layer는 모두 삭제했다고 한다.
filter size는 3x3으로 고정시켜주었다고 했으니 receptive field는 (2d + 1)(2d + 1)의 값을 가지고 있는다고 했는데, 이해가 잘 안될거 같으니 예시를 들어보겠다.
첫번째 layer 5x5, 두번째 layer 3x3, 세번째 1x1이라고 하자
그렇다면 세번째 layer에서 가지는 receptive field는 depth가 2이니 5x5 = 25가 된다.
즉 세번째 1x1의 pixel은 첫번째 layer 5x5의 context information을 다 참조하고 있다고 보면 된다.
context information이란, model이 input data의 주변 정보를 이해하고 활용하는 것을 말한다.
그렇기 때문에 receptive field의 증가는 큰 image region에서 context information을 아는 것이 매우 중요하다고 한다.
앞에서 여러가지의 SOTA method들을 통해서 최적화된 depth를 추출한 값이 17이라고 한다.
depth가 17이니 receptive field는 35x35가 된다고 언급하고 있다.
Network Architecture

여기서부터 이해하는데 시간이 조금 걸렸고 이해하는데 어려움이 있을테니 잘 읽기를 바랍니다.
앞에서 언급했지만, DnCNN은 y(y = x + v)를 넣어서 x가 되게끔 학습하는 것이 아니라, y가 noise로 되게끔 학습하는 것이 목표였다. 즉, noise를 분리하는 것이 목적이 되는 모델이 되는 것이다.
위에서 DnCNN은 y(y = x + v)를 input data로 넣게 된다고 하였고, MLP나 CSF는 F(y) = x로 되게끔 학습한다고 하였다.
F(y) = x로 되는 것은 그냥 noisy image를 clean image로 output image로 결과를 내겠다는 뜻이다.
하지만 여기서는 residual learning을 이용하여 image의 noise를 output의 값으로 도출한다.
R(y) ≈ v 라는 것을 잘봐야한다. 이것은 ResNet에서 H(x)라는 값이라고 생각하고, R(y)가 우리가 원하는 output값이다. 왜냐하면? v가 noise를 의미하니까.
DnCNN은 ResNet과는 달리 1개의 identity mapping을 이용해준다고 하였는데, 이 identity mapping의 값은 y로 output값에 더해주는 역할을 하게 된다.
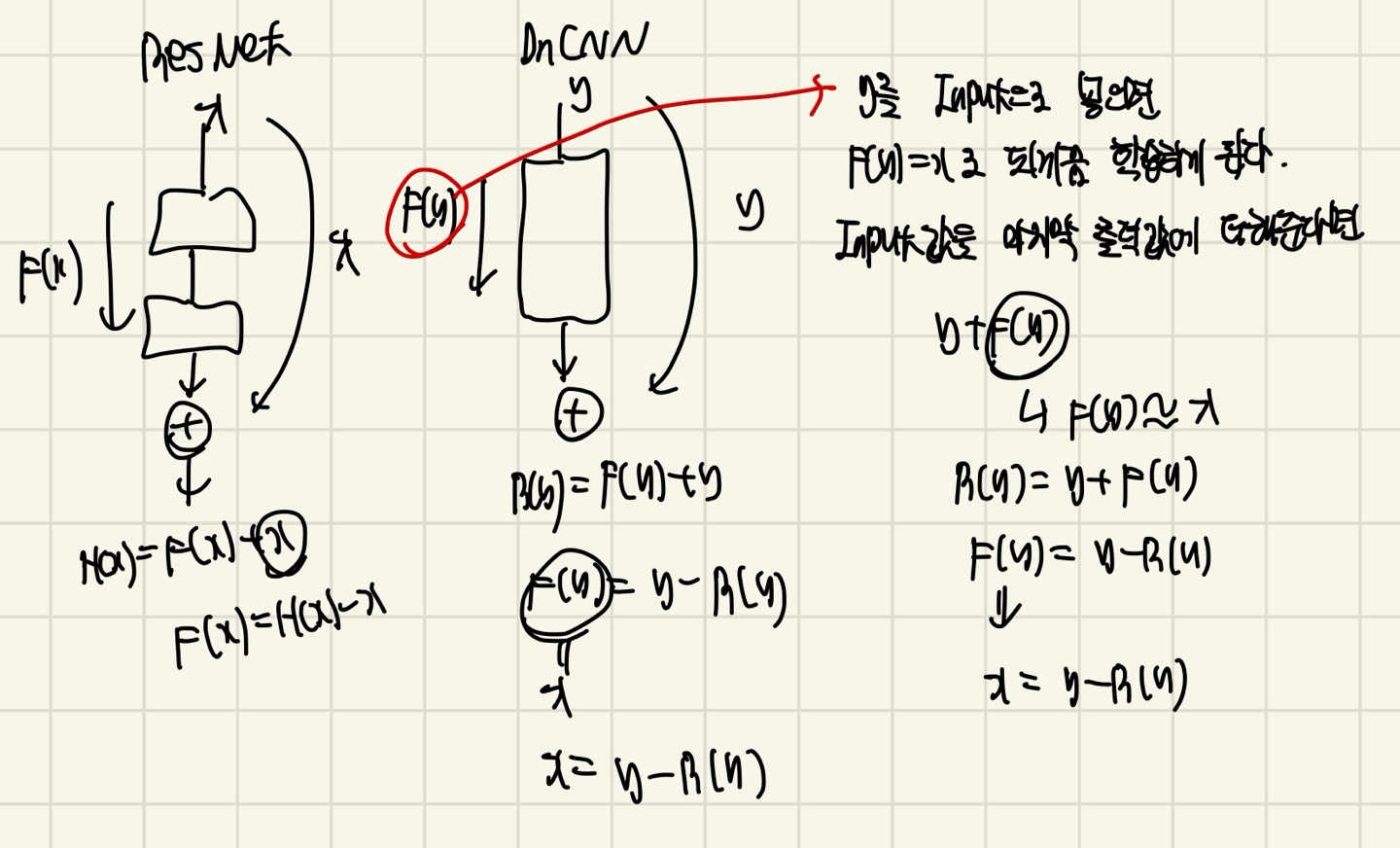
글 만으로 이해하는데 어려움이 있을까봐, 그림으로 나타냈다. 이해하는데 큰 어려움은 없을거다!!
그래서 논문에서 말하는 Loss function은 Averaged MSE를 이용하는데 R은 predict한 noise가 되고, 는 실제 noise가 되는 것으로 볼 수 있다.
이 부분은 어느 블로그에도 쓰여있지 않아 이해하는데 어려움이 있었다.
또한 boundary artifacts의 문제를 해결하였다는데, boundary artifacts란 convolution operation을 할때, image의 edge부분은 주변 pixel값이 부족하여서 이웃한 pixel을 이용하여 filtering 할 수 없다는 문제가 발생하게 되는데 이로 인해 output이 noise가 끼거나 이상한 모양이 발생할 수 있게 된다.(우리가 알고 있는 padding으로 해결 가능 !)
Deep Architecture

드디어 모델의 architecture에 대해서 설명한다.
3가지의 category로 layer를 설명하였다.
첫번째 Conv + ReLU는 첫번째 layer에만 적용되며, 3x3xC의 filter size를 가지고 있고 C는 당연히 input data channel에 dependent하다. filter의 개수는 64개라고 한다.
먼저 convolution연산을 하고 ReLU에 넣는다는 언급까지 있다.
두번째 Conv + Batch Normalization + ReLU는 2 ~ (D - 1)의 layer에만 적용된다고 하는데 만약 앞에서 말한 depth가 17이라면 2 ~ 16까지의 layer에만 적용되겠다.
3x3x64의 filter size를 가지고 있고, 64개의 filter개수를 가지고 있다고 한다.
convolution연산을 한 다음 Batch Normalization 적용 후 ReLU에 넣는다고 한다.
세번째 Conv는 마지막 output을 도출하는 layer로 3x3x64의 filter size를 가지고 있고 C개의 filter를 가진다고 한다. 이때 C는 input의 channel과 같다.
Reducing Boundary Artifacts

위에서 언급한 boundary artifacts의 문제점을 해결하기 위해서 zero-padding을 이용하였다고 합니다. 이는 convolution operation전에 적용함으로써 input과 output의 size가 같도록 padding size를 설정해주었다고 합니다.
(이때의 output은 output layer의 값을 의미합니다.)
Integration of Residual Learning and Batch Normalization for Image Denoising
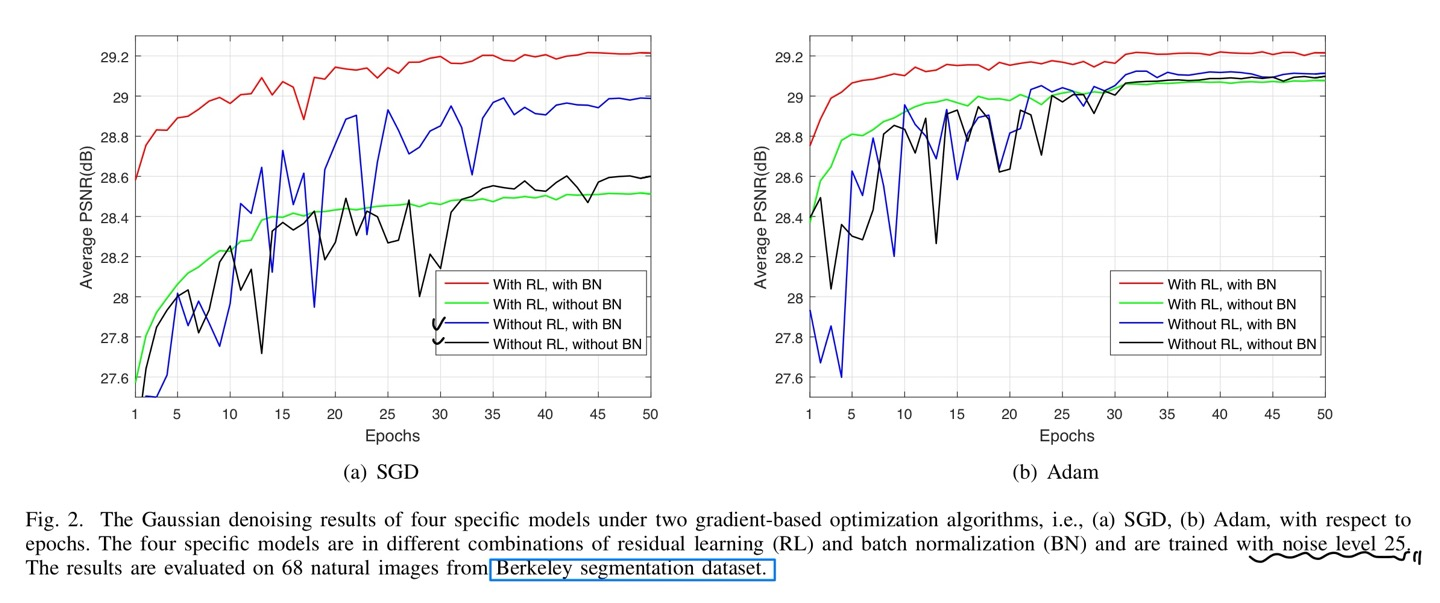
계속해서 강조하였던 residual learning과 batch normalization을 그래프로 또 설명하기 때문에 글은 첨무하지 않았습니다.
먼저 optimizer인, SGD(Momentum)와 Adam따라 그래프를 나눴고 batch norm과 residual이 있냐 없냐에 따라 또 4가지의 구성으로 나눴다.
결론은 residual과 batch norm은 서로 도와주는 관계가 되는 것이고 batch norm만 있을때는 수렴하는데 매우 변동이 심하다는 adverse effect가 있다고 한다.
Residual만 있을때는 변동폭이 심하지는 않으나 PSNR값이 낮다는 것이 문제라는 것이다.
PSNR 설명
즉, 2가지를 함께 사용하면 Red Line처럼 좋아진다고 언급하고 있다.
1가지 궁금한 점은 Residual learning과 batch normalization이 gaussian distribution과 관련이 있다고 언급하는데, 이 부분은 아직 해결하지 못하였다. 혹시라도 알고 있으신 분이 있다면 알려주세효..(이로 인해, Gaussian denoising하는데 유리하다고 언급도 한다.)
코드 구현
DnCNN
이번 코드는 model만 짰습니다.
읽어주셔서 감사합니다 :)
