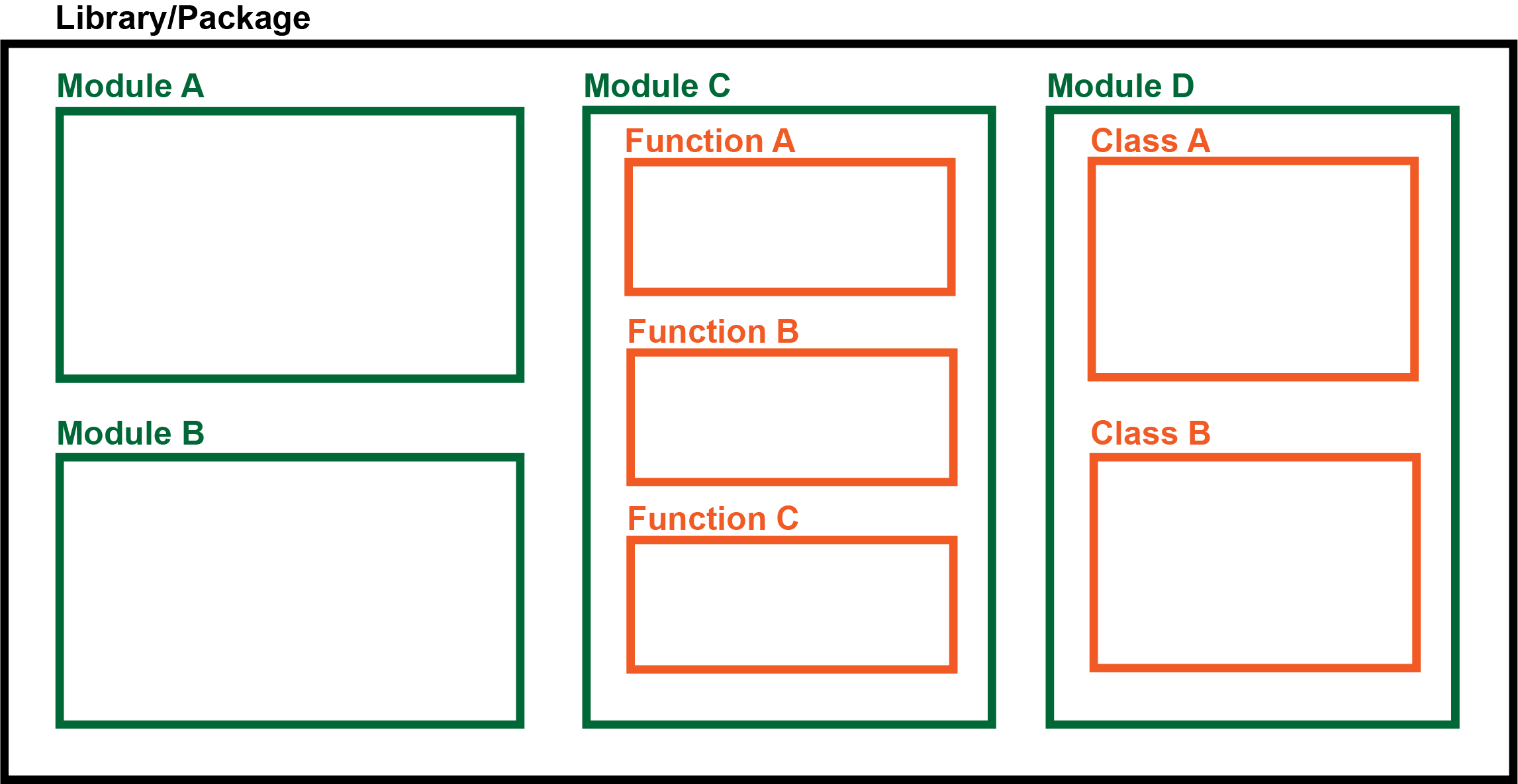
단어 정리
코드
import 패키지이름
from 패키지이름.모듈이름 import 클래스이름, 함수이름
import 패키지이름 as 이름변경
패키지이름.모듈이름.클래스이름()
클래스이름()
이름변경.모듈이름.함수이름()
함수이름()라이브러리
표준 라이브러리(standard)

- 수학, 랜, 시간, 경로, 정규표현식, 운영체제 등 존재함
math
import math
math.log2(10)외부 라이브러리(third party)
https://pbs.twimg.com/media/FOZBQVrVkAIrSNv?format=png&name=small
- 데이터 수집
- requests, selenium, beautifulsoup, scrapy
- 데이터 분석
- pandas, numpy
- 이미지 처리
- Pillow, OpenCV
- 자연어 처리
- NLTK, Gensim, HF Transformers, spaCy, konlpy
- 통계, 머신러닝, 딥러닝
- scipy, scikit-learn, tensorflow, keras, pytorch
- 시각화
- matplotlib, seaborn, plotly
pandas

- 다양한 형식 간에 데이터를 읽고 쓸 수 있음(csv, json, xml, xlsx, sql, hdf5)
- 데이터 정렬, 누락 통합 처리
- 시계열 기능 존재
- DataFrame 객체
- cheat sheet 존재
데이터 프레임(DataFrame : df) 생성
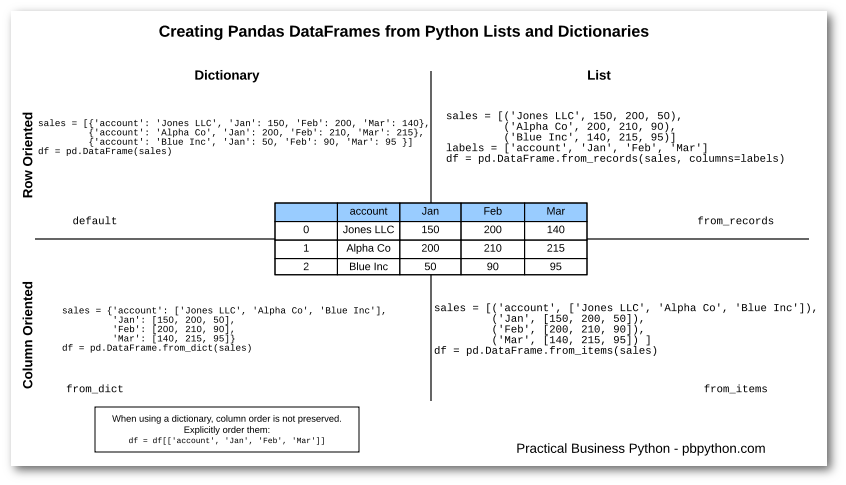
# 외부 lib 불러오기
import pandas as pd
# 배열 1개로 데이터 생성
df = pd.DataFrame(range(1, 7))
# 배열 2개로 데이터 생성
df = pd.DataFrame([range(1, 7), range(7, 1, -1)])df 요소 접근
# 이중 list 처럼 접근 가능
print(df[2][1])
# 슬라이싱은 index 기반으로 나누어 df로 만듬
print(df[:1])컬럼(columns : col), 인덱스(index : idx) 확인 및 변경
# col 이름 확인
print(df.columns)
# col 이름 변경
df.columns = list('abcdef')
# idx 이름 확인
print(df.index)
# idx 이름 변경
df.index = list('gh')df col과 idx를 통하 접근 & loc, iloc & 전치(Transformation : T)
# col 기반으로 series 접근
print(df['a'])
# col, idx 기반으로 요소 접근
print(df['b']['g'])
# subset 만들기
## col과 idx의 값을 토대로 접근함
print(df.loc['h', 'c':'f'])
## col과 idx의 위치를 토대로 접근함
print(df.iloc[1, 2:6])
# 전치(Transformation : T)
print(df.T)브로드캐스팅 Broadcasting
# 각각의 값에 5를 뺀다
print(df - 5)
print('*' * 20)
# 행 각각의 값에 5를 뺀다
print(df[1] - 5)
print('*' * 20)
# 열 각각의 값에 5를 뺀다
print(df.iloc[1, :] - 5)
print('*' * 20)
# 한 값에 5를 뺀다
print(df.iloc[1, 1] - 5)
print('*' * 20)
# idx에 맞춰서 값을 빼준다
print(df[1] - df.loc[1, :])값 변경
# 값 변경
df[2] = list('abc')
print(df)
# 값이 str이면 str 간 연산 가능
print(df[2] + 'a')파일 저장과 불러오기
# 엑셀 저장
df.to_excel('result.xlsx')
# 엑셀 불러오기
df_load = pd.read_excel('result.xlsx', index_col=0)- 파일 위치는 상대경로 또는 절대경로로 지정
간단한 수학 연산

df[3].max() # 최대값
df[3].mode() # 최빈값
df[3].median() # 중앙값
df[3].mean() # 평균값
df[3].min() # 최소값df 파일 합치기
# 위아래로 합치기
pd.concat([df, df])
# 좌우로 합치기
pd.concat([df, df], axis=1)
# 각각 0의 기준으로 두 df를 합치기
df.merge(df, left_on=0, right_on=0)numpy

- 수치 계산을 가능하게 하는 것을 목표로 함
- Numeric & Numarray 라이브러리의 초기 작업
numpy 객체 만들기
import numpy as np
arr = np.array([range(1, 7), range(7, 1, -1), [7, 4, 1, 8, 5, 2]])
lst =[range(1, 7), range(7, 1, -1), [7, 4, 1, 8, 5, 2]]
# 접근은 DataFrame, np.array, list 동일
print(df[1][1])
print(arr[1][1])
print(lst[1][1])브로드캐스팅 Broadcasting
# 각각의 값에 5를 뺀다
print(arr - 5)
print('*' * 20)
# 행 각각의 값에 5를 뺀다
print(arr[1] - 5)
print('*' * 20)
# 열 각각의 값에 5를 뺀다
print(arr[:, 1] - 5)
print('*' * 20)
# 한 값에 5를 뺀다
print(arr[1, 1] - 5)
print('*' * 20)
# 행을 복제하고 열을 복제하여 뺀
print(arr[1].reshape(-1,1) - arr[1, :])값 변경
# 오류 발생함
arr[1] = list('abcdef')
# arr의 내부 형식을 변경하면,
arr = arr.astype(object)
# 오류가 발생하지 않음
arr[1] = list('abcdef')얕은 복사, 깊은 복사
- 객체가 중복되면, 값이 같이 변경됨
lst_shallow= lst # 얕은 복사
lst_shallow is lst # 객체가 같음
lst_deep = lst.copy() # 깊은 복사
lst_deep is lst # 객체가 다름실제 데이터 핸들링
공공데이터포털
- 위 사이트를 통해 양질에 공공 데이터을 사용하자!
데이터 살펴보기
# 파일 경로와 코드 경로가 동일할 것
df = pd.read_csv('시청자미디어재단_체험형미디어교육_20221109.csv', encoding='cp949')
pd.concat([
# 상위 5개 확인
df.head(),
# sampling 5개 확인
df.sample(5),
# 하위 5개 확인
df.tail(),
])
# df의 인덱스 정보, 컬럼 정보(이름, 결측값, 데이터 종류) 확인
df.info()
# df 통계적 정보 확인
df.describe()
# 컬럼별
for col in df.columns:
# 컬럼 이름
print(col)
# 속성 이름 확인
print(df[col].unique())
# 속성 갯수 확인
print(df[col].nunique())
# 속성별 갯수 확인
print(df[col].value_counts())
print('*' * 50)마스킹
# 교육대상구분이 청소년인지 확인
masking = df['교육대상구분'] == '청소년'
# 확인된 결과를 토대로 접근
df[masking](Column & index) | (추가 & 삭제)
# 브로드캐스팅 추가
df['new_col'] = 0 # col 추가
df.loc['new_row'] = 0 # row 추가
# 크기가 다름
df['error'] = [1,2,3,4]
# 크기가 같으면 가능 & 덮어쓰기
df['new_col'] = range(len(df))
# 브로드캐스팅 삭제
df.drop('new_col', axis=1) # col 삭제
df.drop('new_row') # row 삭제index 초기화
# 인덱스 변경
df.index = range(0,400,4)
# 인덱스 초기화
df.reset_index()실습
pandas
df = pd.DataFrame([range(1, 7), range(7, 1, -1), [7, 4, 1, 8, 5, 2]], columns= list('xyzwab'))01 y, 2 데이터
print(df.loc[2, 'y'])02 w,0에서부터 w,2까지의 데이터
print(df['w'])03 b,1에서부터 b,2까지의 데이터
print(df.iloc[1:,-1])04 x,0에서부터 w,0까지의 데이터
print(df.iloc[0,:4])05 y,1에서부터 w,2까지의 데이터
print(df.loc[1:2,'y':'w'])
print(df.iloc[1:3, 1:4])실제 데이터 다루기
센터명 column의 문자열 변경
for i in df['센터명']:
# 울산이면 울산을 제거 후 출력
if '울산' in i:
print(i.replace('울산', ''))
continue
# 광주라면 역순 출력
if '광주' in i:
print(i[::-1])
continue
# 미디어 센터만 제거 후 출력
print(i.replace('미디어센터', ''))
# 또는
print('\n'.join(
df['센터명'].apply(
lambda row : row.replace('울산', '') if '울산' in row else row[::-1] if '광주' in row else row.replace('미디어센터', '')
).tolist()
)
)교육종료일자 - 교육시작일자 를 계산해 교육기간 확인
for i in df.index:
a = int(df.loc[i, '교육종료일자'].split('-')[-1])
b = int(df.loc[i, '교육시작일자'].split('-')[-1])
print(a - b + 1)
# 또는
df['교육종료일자'].apply(lambda row : int(row.split('-')[-1])) - df['교육시작일자'].apply(lambda row : int(row.split('-')[-1])) + 1
# 또는
print('\n'.join(
(
(
pd.to_datetime(df['교육종료일자']) - pd.to_datetime(df['교육시작일자'])
).dt.days + 1
).astype(str).tolist()))강좌정원수 가 20 이상 30 이하인 강좌명 뽑기
# 조건을 idx에 목표를 column에
df.loc[(20 <= df['강좌정원수']) & (df['강좌정원수'] <= 30), '강좌명']
# 또는
query_expr = '20 <= 강좌정원수 <= 30'
df.query(query_expr)['강좌명']복잡한 요청 처리하기
# 업무 전에 원본을 저장해두자!
df_org = df.copy()
# 인덱스를 내림차순으로(값 상관 X)
df.index = range(len(df),0,-1)
# 또는
df.index = df.index[::-1]
# 강좌내용, 교육대상구분 columns 제거
df.drop(['강좌내용', '교육대상구분'], axis=1, inplace = True)
# 교육방법구분이 온라인인 항목을 df_online 변수에 저장
df_online = df[df['교육방법구분'] == '온라인']
# 온라인 항목을 df에서 제거
df = df[df['교육방법구분'] != '온라인']
# 또는
df.drop(df['교육방법구분'] == '온라인'].index, axis=0)변경 요청 처리하기
# 인덱스를 내림차순으로(값 같이)
df.sort_index(ascending=False, inplace=True)
# 또는
df = df[::-1]
# 제거한 columns 복구
df['강좌내용'] = df_org['강좌내용']
df['교육대상구분'] = df_org['교육대상구분']
# 강좌정원수의 평균을 전체와 온라인을 기점으로 구하라
print(df['강좌정원수'].mean(), df.loc[df['교육방법구분'] == '온라인', '강좌정원수'].mean())
# 또는
df.pivot_table('강좌정원수', '교육방법구분', aggfunc=np.mean)
# 또는
df.groupby('교육방법구분').mean()추가 과제
- 센터간 강좌정원수가 유의미한 차이가 있는지 확인해라(T-Test 분석을 해라)
df_incheon = df.loc[df['센터명'].str.contains('인천'), '강좌정원수']
df_busan = df.loc[df['센터명'].str.contains('부산'), '강좌정원수']
result = stats.ttest_ind(df_incheon, df_busan)
print(result.pvalue < 0.05)
# 0.24 < 0.05
# 귀무가설 성립
# 차이가 없다회고
- 패키지에 대해 간단하게 살펴보고 라이브러리가 다양하게 존재하는 것을 알았음
- pandas의 다양한 데이터 프레임 생성 방식을 어떻게 응용할 수 있을지 생각해 볼만 함
- 상대경로와 절대경로에 대해 알고 있어야 함
- 통계만 보고 값에 형태를 예측할 수 있으면 좋음
- 실제 데이터를 핸들링하면서, 실전 감각을 느낄 수 있었음
- 한 문제라도 다양한 해결책이 존재함을 느낌
- 앞서 배운 KISS 하며 DRY한 코드가 제일이라고 생각함
Ref
- 헷갈리는 용어 정리 - 라이브러리/패키지/모듈, 함수/메서드, 매개변수/(전달)인자, 클래스/객체 blog
- 파이썬 표준 라이브러리 docs
- Top Python Libraries For Data Science In 2022 blog
- pandas docs
- Data Wrangling with pandas Cheat Sheet cheat sheet
- 절대주소 vs 상대주소 개념 정확히 이해하기 inflearn
- 기술통계 book
- numpy docs
- 리스트의 할당과 복사 알아보기 코딩도장
- 공공데이터포털 공공데이터
- 시청자미디어재단_체험형미디어교육 공공데이터

DA DE DS