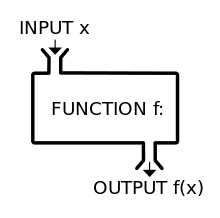
함수
- 없어도 되지만, 유지보수에 큰 어려움
함수의 모습
def 함수이름(변수이름):
반환값 = 변수이름 * 2 # 연산
return 반환값 # 결과 반환
def func(): # 변수가 없을 수 있음
print('출력') # 반환값이 없을 수 있음
def dumy():
pass # 아무것도 하기 싫으면 pass함수를 쓰는 경우
def func(x, y): # 함수 이름 매개변수(variable) 이름을 설정
result = x + y # 연산을 실행
result += x
return result # 아래 코드는 무시됨
result **= 2
result /= y
# print도 함수!
print(func(1, 2)) # 함수의 반환값을 출력함
print(func(2, 3)) # 함수의 반환값을 출력함
print(func(3, 4)) # 함수의 반환값을 출력함- 9 줄
- 수식이 잘못 됐을 때, 수정 횟수 1회
함수를 쓰지 않는 경우
x, y = 1, 2
result = x + y
result += x
result **= 2
result /= y
print(result)
x, y = 2, 3
result = x + y
result += x
result **= 2
result /= y
print(result)
x, y = 3, 4
result = x + y
result += x
result **= 2
result /= y
print(result)- 18 줄
- 수식이 잘못 됐을 때, 수정 횟수 3회
지역변수 & 전역변수
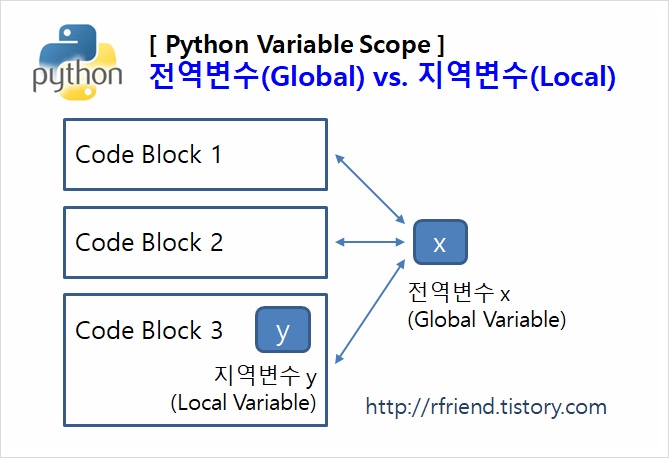
x = 10 # 전역변수
def func():
y = 10 # 지역변수
print(x + y)
print(y) # 오류 발생
def func():
global x # 외부 변수를 불러옴
x = 11
print(x) # 변경 가능Comprehension
- 한줄 반복문
lists = []
for i in range(5):
lists += [i ** 2]
# 또는
# lists.append(i ** 2)
# 한줄로
[i ** 2 in i for range(5)]df.apply()
import pandas as pd
df = pd.read_excel('시청자미디어재단_체험형미디어교육_20221109.xlsx')
df['강좌정원수'].apply(lambda x : str(x)[-1] == '5')실습
함수와 반복문
입력된 두 수의 제곱을 각각 리턴하는 함수를 만든다
nums = list(map(int, input().split()))
def pow2(i):
return nums[i] ** 2
# list(map(pow2, range(len(nums))))
[pow2(i) for i in range(len(nums))]두 숫자를 입력받고 첫번째는 팩토리얼 두번째는 제곱을 반환
from math import prod
nums = list(map(int, input().split()))
def pow2(i):
return nums[i] ** 2
def factAndPow(arr):
return [pow2(v) if i % 2 == 1 else prod(range(2, v + 1)) for i, v in enumerate(arr)]
factAndPow(nums)재귀 함수 팩토리얼
def fact2(num):
if num > 1:
return fact2(num - 1) * num
else:
return 1Comprehension
1 ~ 99 범위 중 짝수만 남기고 나머지는 0으로 리스트
[i if i % 2 == 0 else 0 for i in range(1, 100)]
# 짝수인 것만 추출
[i for i in range(1, 100) if i % 2 == 0]
100 ~ -100 범위 중 끝자리가 5인 리스트
list(range(95,-96,-10))'apple', 'bird', 'cat', 'dog', 'e' 문자에서, 각 문자를 대문자로 만든 리스트
str_list = ['apple', 'bird', 'cat', 'dog', 'e']
[i.upper() for i in str_list]실제 데이터 다루기(저번 데이터와 동일)
import pandas as pd
df = pd.read_excel('시청자미디어재단_체험형미디어교육_20221109.xlsx')
df_org = df.copy()교육종료일자 가 각각 몇 월인지 알아보기
df['교육종료일자'].apply(lambda x: x.split('-')[1])
# 또는
pd.to_datetime(df['교육종료일자']).dt.month데이터기준일자가 3의 배수인 날짜를 True로 수정
df['데이터기준일자'] = df['데이터기준일자'].apply(lambda row: True if int(row[-2:]) % 3 == 0 else row)
# 또는
df['데이터기준일자'] = df['데이터기준일자'].apply(lambda row :True if row.day % 3 == 0 else row)
# 또는
# 전부 동일 날짜에 수집됨
df['데이터기준일자'] = True센터가 수도권에 위치하고, 교육대상이 “법정 성인” 이상인 강좌를 확인
- 서울특별시·인천광역시·경기도 등 서울 및 주변지역을 통칭하는 권역.서울대도시권.
- 제4조(성년) 사람은 19세로 성년에 이르게 된다.
df['센터명'].unique() # 서울, 인천, 경기도
df['교육대상구분'].unique() # 노인, 성인, 대학생
df[
(
df['센터명'].str.contains('서울') |
df['센터명'].str.contains('인천') |
df['센터명'].str.contains('경기')
) &
(
df['교육대상구분'].str.contains('노인') |
df['교육대상구분'].str.contains('성인') |
df['교육대상구분'].str.contains('대학생')
)
]
list_target_location = ['서울시청자미디어센터', '인천시청자미디어센터', '경기시청자미디어센터']
list_education_target = ['노인', '성인', '대학생']
query_expr = '센터명 in @list_target_location and 교육대상구분 in @list_education_target' # 외부 변수를 불러옴
df.query(query_expr)과제
원하는 요소 변경 및 저장
- 각 row 데이터에 대해 연산하기 (x+1)*2 (교육시작일자의 연도를 대상으로 함)
- 연산 결과는 ‘calc’ 열로 따로 저장하기
- 오늘 날짜로 저장
import time
df['calc'] = [(int(i[:4]) + 1) * 2 for i in df['교육시작일자'].astype(str)]
df.to_csv(f"{time.strftime('%Y%m%d')}.csv")
# 또는
df['calc'] = (df['교육시작일자'].dt.year + 1) * 2
# 또는
df['calc'] = df['교육시작일자'].apply(lambda row : (row.year + 1) * 2)판다스 패키지를 이용한다
1. 주어진 데이터를 이용해 각 row 데이터에 대해 연산하기 (x+1)*2 (교육시작일자의 연도를 대상으로 함)
1.
1. (오늘 날짜).csv 파일로 내보내기
1. 이 때, 반복문을 사용한 코드, 함수를 이용한 코드를 각각 작성해보자각 요일마다 몇 개의 프로그램이 진행되는지 확인
df['운영요일'].value_counts()
# "월, 화, 수, 목, 금" 어떻게 처리할지?
# 또는
for weekday in '월 화 수 목 금 토 일'.split():
print(weekday, df['운영요일'].str.count(weekday).sum(), end = '\t')교육시작일자 의 11월 전반기 후반기 비교
교육시작일자의 11월 전반기 후반기로 나눔- 11월 전/후반기에서 온/오프라인의 비중 변화 확인
- 11월 전/후반기에서 강좌의 연령층 변화 확인
masking = df['교육시작일자'].apply(lambda x: int(x[-2:]) > 15)
df_15 = df[-m]
df_30 = df[m]
df_15['교육방법구분'].value_counts()
df_30['교육방법구분'].value_counts()
df_15['교육대상구분'].value_counts()
df_30['교육대상구분'].value_counts()
# 또는
import numpy as np
df['반기구분'] = np.where(df["교육시작일자"].dt.day <= 15 , "전반기","후반기")
df['n'] = 1
df.pivot_table(
index = ['교육방법구분', '교육대상구분'],
columns = '반기구분',
values = 'n',
aggfunc = sum,
fill_value = 0,
)
# 또는
df.groupby(['교육방법구분', '교육대상구분', '반기구분'])['n'].sum().unstack().fillna(0)추가로 하고 싶은 것
# !sudo apt-get install -y fonts-nanum
# !sudo fc-cache -fv
# !rm ~/.cache/matplotlib -rfimport matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')df.pivot_table(
index = ['교육방법구분', '교육대상구분'],
columns = '반기구분',
values = 'n',
aggfunc = sum,
fill_value = 0,
).sort_values(
['전반기', '후반기'],
ascending=False
).plot.pie(
subplots=True,
figsize=(24,12),
legend = False,
colormap = 'gist_ncar'
)추가 과제
- 교육일정 기간과 강좌정원수의 상관관계 알아보기
df['교육기간'] = (df['교육종료일자'] - df['교육시작일자']).dt.days + 1
df[['교육기간', '강좌정원수']].corr()df.plot.scatter('교육횟수', '강좌정원수')- 상관관계를 판단을 쉽게 하기 위해서 기법
- outlier 제거
- binning(구간화)
- qcut()
- 축 단위 변경
- Log Transform
- Regression
회고
- 함수를 효과적으로 짜면, 분업 시에도 많은 도움이 될 것으로 생각됨
- 함수내에서 전역변수를 선언하는 것은 언제 사용하게 될지 모르겠음
- comprehension은 가독성을 떨어트리는 것 같지만, 경우에 따라 효과적일 것
- math의 prod 함수가 있음을 알게 됨
- 실제 회사에서는 추상적인 테스크를 줄 가능성이 있음을 알았음
- 추가로 merge나 pivot을 마음대로 사용할 수 있으면, 데이터 프레임을 조작할 때 편할 것
- 상관관계를 확인하기 위해 단순 시각화가 아닌 수치로 나타내는 방법이 있음!
Ref
- 함수 사용하기 코딩도장
- [Python] 변수의 유효범위 : 전역변수(Global variable) vs. 지역변수(Local variable) blog
- 수도권 한국민족문화대백과사전
- 성년 법령 민법 4조

DA DE DS