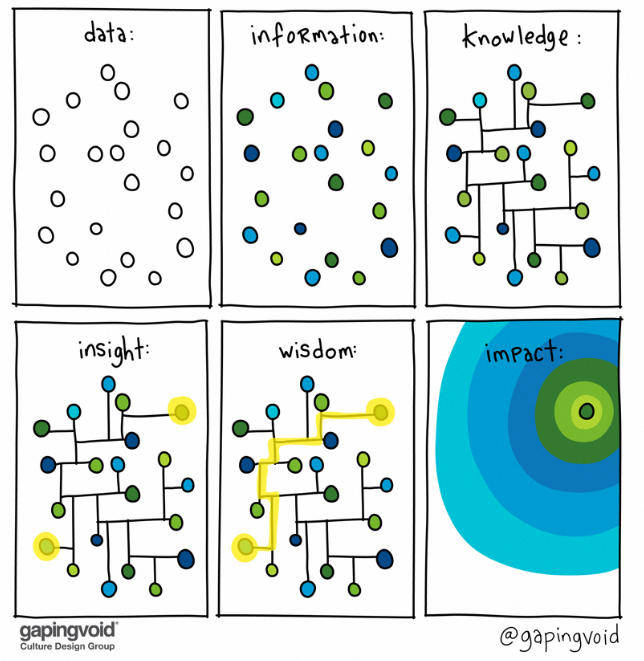
데이터와 정보
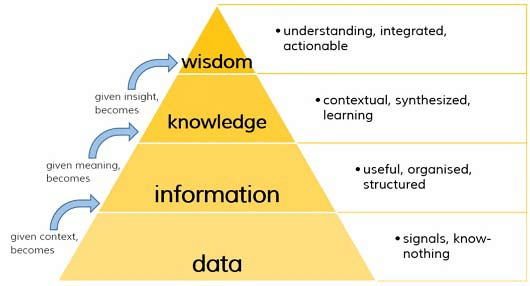{kind=link}

- 데이터
- 단순히 모인 기록물 ⇒ 분석 X
- 정보
- 데이터를 가공하여 분석이 가능한 것 형태로 변경함
데이터 전처리
데이터 클리닝
- 이전 자료 참고
데이터 통합
- 출처가 다양한 데이터 단일화
- 동일 데이터로 통합함
- 날짜 기반으로 join할 때, 시간이 제대로 겹치는가?
- 10분 단위 정보와 1시간 단위 정보의 join?
- 날짜 기반으로 join할 때, 시간이 제대로 겹치는가?
- 동일 데이터로 통합함
데이터 변환
데이터 축소
- 분석이 불가능할 정도로 큰 데이터 ⇒ 저차원, 저용량으로 변경
데이터 이산화
- 카테고리를 숫자로
데이터 표준화 & 정규화
실습
titanic
import pandas as pd
df = pd.read_csv('test.csv')
df_org = df.copy()
pd.concat([df.head(), df.sample(5), df.tail()])Age 항목의 결측치를 파악해 아래 분석을 모두 수행
- 결측치를 0으로 대체 (fillna 함수 이용 가능)
- 전체 값의 평균으로 대체 (mean 함수 이용 가능)
- 중앙값으로 대체 (median 함수 이용 가능)
mean, median = df.Age.mean(), df.Age.median()
ages = [
df['Age'],
df['Age'].fillna(0),
df['Age'].fillna(mean),
df['Age'].fillna(median),
]
titles = 'default 0 mean median'.split()plot_num = len(ages)
fig, axes = plt.subplots(2, plot_num, figsize=(plot_num * 6, 2 * 4)) # fig를 (1, 2)로 분할
# 히스토그램
for i in range(plot_num):
ages[i].plot.hist(title=titles[i], ax=axes[0][i], ylabel = ' ')
axes[0][i].set_ylabel("")
# boxplot
for i in range(plot_num):
ages[i].plot.box(ax=axes[1][i])
axes[1][i].plot([median] * 3, ls = ':', color = 'r', label = 'original median')
axes[1][i].plot([mean] * 3, ls = ':', color = 'b', label = 'original mean')
axes[1][3].legend()
datas = pd.DataFrame()
for i in range(plot_num):
datas[titles[i]] = ages[i].describe()
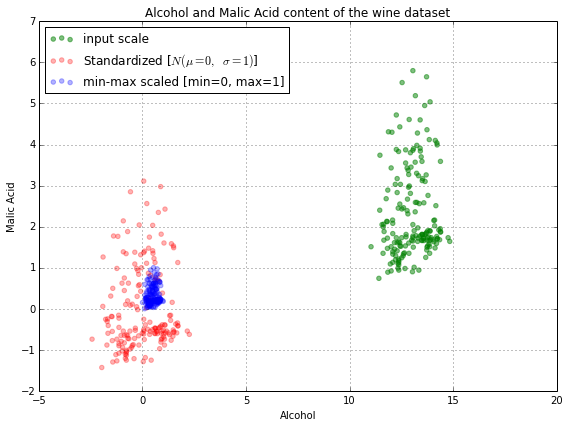
datas나이 정보를 확인한 뒤, 나이 정보를 표준화/정규화 작업을 모두 수행해 보자
from sklearn import preprocessing as preprocessing
origin = pd.DataFrame(df['Age'].values.reshape(-1, 1))
ages = [
origin,
pd.DataFrame(preprocessing.MinMaxScaler().fit_transform(origin)),
pd.DataFrame(preprocessing.StandardScaler().fit_transform(origin)),
]
titles = 'origin min_max standard'.split()
fig, axes = plt.subplots(3, 3, figsize=(12, 12)) # fig를 (1, 2)로 분할
fig.subplots_adjust(hspace=0.3)
ylims = []
# boxplot
for i in range(3):
for j in range(3):
tmp = ages[j].plot.box(ax=axes[i][j], title=f'value : {titles[j]}\nylim : {titles[i]}')
if i == 0:
ylims += [tmp.get_ylim()]
axes[i][j].set_ylim(ylims[i][0], ylims[i][1])요금 정보의 outliar를 확인하고, 해당 정보를 어떻게 처리할지 생각해보자
df['Fare'].plot.box()- IQR로 소거
# IQR
def iqr_outlier(series):
q1 = series.quantile(0.25)
q3 = series.quantile(0.75)
iqr = q3 - q1
series = series.loc[
(q1 - iqr * 1.5 < series) &\
(series < q3 + iqr * 1.5)
]
return series
iqr_outlier(df['Fare']).plot.box()- 표준편차로 소거
# stq
def std_outlier(series, threshold = 2):
# 1 = 0.68, 2 = 0.95, 3 = 0.997
series = series[
series.apply(
lambda row : abs((row - series.mean()) / series.std()) <= threshold
)
]
return series
std_outlier(df['Fare'], 1).plot.box()- IForest, DBSCAN 생략
SibSp 값에 따른 Fare 변화를 구함
- SibSp 값이 1 이상인 경우, 별다른 처리를 하지 않는다
- SibSp 값이 0인 경우, Age 값을 고려하여 분석한다
df.loc[df['SibSp'] == 0, 'Age'].describe()
#0.33살 아이가 혼자 탑승df.loc[(df['SibSp'] == 0) & (df['Age'] > 5)]Embarked 값에 따른 Fare 변화를 구한다
- 같은 Embarked 그룹에서 Fare 값이 지나치게 차이가 나는 경우 outliar로 취급하여 삭제한다
- 단, 위와 같은 경우지만 SibSp가 높은 경우, 인원수를 고려해 처리한다
# 인원수 고려를 위해 연산을 미리해둠
df['Fare/SibSp'] = df['Fare'] / (df['SibSp'] + 1)
df.pivot(columns='Embarked', values = 'Fare/SibSp').plot.box()
fig, ax = plt.subplots()
_ = ax.boxplot(
[
iqr_outlier(df_embarked_fare['C']).dropna(),
iqr_outlier(df_embarked_fare['Q']).dropna(),
iqr_outlier(df_embarked_fare['S']).dropna(),
],
labels = 'C Q S'.split()
)시청자미디어재단_체험형미디어교육
import pandas as pd
df = pd.read_excel('시청자미디어재단_체험형미디어교육_20221109.xlsx')
df_org = df.copy()
pd.concat([df.head(), df.sample(5), df.tail()])아래 목적을 위해 데이터 전처리함
- 교육기간을 계산
df['교육기간'] = df['교육종료일자'] - df['교육시작일자']- 지역별 분류
df['센터명'].unique()
# 손실 변환을 피해야 함 = 센터명을 지우면 안됨
df['지역'] = df['센터명'].apply(lambda row : row[:2])
import seaborn as sns
sns.countplot(
x = df['지역'],
order = df['지역'].value_counts().index
)- 교육대상 분류
df['교육대상구분'].unique()
categorys = {
'유아' : '청소년 미만',
'미취학' : '청소년 미만',
'유아,아동' : '청소년 미만',
'6~7세' : '청소년 미만',
'초등학생' : '청소년 미만',
'청소년' : '청소년 이상',
'중학생' : '청소년 이상',
'중고등학생' : '청소년 이상',
'고등학생' : '청소년 이상',
'고등학생,장애인' : '청소년 이상',
'중학생,장애인' : '청소년 이상',
'성인' : '청소년 이상',
'대학생' : '청소년 이상',
'성인,장애인' : '청소년 이상',
'노인(65세~)' : '청소년 이상',
'초등학생 이상' : '혼합',
'일반' : '혼합',
'모든연령' : '혼합',
'지역주민' : '혼합',
}
df['나이구분'] = df['교육대상구분'].replace(categorys)- 운영요일에 따른 통계 기법 적용
df['운영요일'].unique()from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['요일_label'] = le.fit_transform(df['운영요일'])from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
pd.concat(
[
df,
pd.DataFrame(
ohe.fit_transform(df['운영요일'].to_numpy().reshape(-1, 1)).toarray(),
columns=ohe.categories_
),
],
axis=1
)- 차원이 많이 생김(5개 초과) = X
회고
- 데이터와 정보의 차이가 확실함을 확인함
- 데이터 통합을 할 때, 다양한 상황을 고려하는 것이 필요함
- 데이터 변환을 할 때, 요구하는 내용을 확인하고 그에 맞는 처리가 필요함
- 표준화와 정규화가 어떻게 다른지 생각하게 됨
- 애매한 질문에 정확한 결과를 도출하는 것이 어려움을 느낌
- 애매한 질문은 추가 질문을 통해 해결해야 함
Ref
- 데이터란 무엇인가? - brunch
- Dimensionality Reduction for Data Visualization in korean - velog
- About Feature Scaling and Normalization - blog
- Titanic - Machine Learning from Disaster - kaggle
- 시청자미디어재단_체험형미디어교육 - 공공데이터포털
- One Hot Encoding 과 Label Encoding 을 비교해보자 - blog

DA DE DS
열정적인 수강일지 잘 읽었습니다~ 앞으로 남은 과정 끝까지 화이팅입니다!! 제니아가 응원 드릴게요 ~! ^.^