- 링크 : https://arxiv.org/abs/2410.05779
- 출간일 : 2024.10
- 저자 : Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, Chao Huang
- 코드 : https://github.com/HKUDS/LightRAG
Abstract
- 기존 문제점
- 복잡한 관계나 문맥을 제대로 이해하지 못함
- 단편적인 답변을 제공- > 질문이 여러 주제에 걸쳐있을 때 문제 발생 ex) 전기차의 증가가 도시의 공기질과 대중교통 인프라에 어떤 영향을 미치는가?
- 논문 제안
- 텍스트 색인 및 검색 과정에 그래프 구조 도입
- 저수준(세부 사항), 고수준(넓은 주제)를 모두 다룰 수 있는 이중 레벨 검색 시스템
- 증분 업데이트 알고리즘으로 새로운 데이터만 부분적으로 업데이트
증분 업데이트(incremental update algorithm)란,
새로운 데이터만 부분적으로 업데이트 하는것을 말함 - 기존 RAG 시스템들과 비교하여 더 높은 검색 정확도, 더 빠른 검색 속도 제공
1. Introduction
- 일반적인 측면
- 그래프 기반 RAG 시스템을 개발하는 것이 기존 방법의 한계를 극복하는 중요한 방법임.
- 그래프 구조를 통합함으로써, 복잡한 관계를 더 잘 이해하고 맥락적으로 풍부한 응답 생성
- 방법론적 측면
- LightRAG는 이중 레벨 검색과 그래프 기반 텍스트 색인을 결합하여, 저수준과 고수준 정보를 모두 포괄하는 효율적이고 적응 가능한 RAG 시스템을 제공.
- 증분 업데이트 알고리즘을 통해 새로운 데이터를 신속하게 통합하고, 전체 색인을 다시 구축하지 않으므로 계산 비용을 절감하고 적응 속도를 높일 수 있음.
- 실험적 결과
- 광범위한 실험을 통해 LightRAG의 성능을 기존 RAG 모델들과 비교했으며, 검색 정확도, 모델 성능(모델 결함 분석 포함), 응답 효율성, 새로운 데이터에 대한 적응성 등 여러 측면에서 상당한 개선을 확인했음
2. Retrieval-Augmented Generation
RAG : 사용자 쿼리를 외부 지식 데이터베이스에서 검색한 관련 문서들과 통합하여
처리하는 시스템
- 검색 컴포넌트
- 외부 지식 데이터베이스에서 관련 문서나 정보 가져옴
- 생성 컴포넌트
- 검색된 정보를 바탕으로 LLM을 활용하여 응답 생성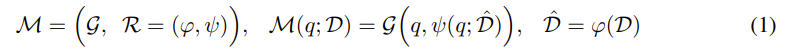
[RAG 프레임워크]
-
R의 주요 기능
- Data Indexer (φ(·))
- 외부 데이터베이스 D를 기반으로 특정 데이터 구조 Dˆ를 구축하는 역할
- Data Retriever (ψ(·))
- 쿼리를 색인된 데이터와 비교하여 관련 문서를 검색하는 역할
- 검색된 문서는 "관련 문서(relevant documents)"로 표시
- Data Indexer (φ(·))
-
ψ(·)를 통해 검색된 정보와 초기 쿼리 q를 활용하여, 생성 모델 G(·)는 적합한 응답을
생성할 수 있음 -
효율적인 RAG를 위해 필요한것
- Comprehensive Information Retrieval(포괄적인 정보검색)
- Data Indexer (φ(·))는 글로벌 정보를 추출하는 능력 필요
- Efficient and Low-Cost Retrieval(효율적이고 저비용의 검색)
- 색인된 데이터 Dˆ는 많은 양의 데이터 쿼리를 빠르게 처리할 수 있어야함
- Fast Adaptation to Data Changes(데이터 변경에 따른 빠른 적응)
- 데이터 구조를 빠르게 조정하여 최신 상태를 유지해야함
- Comprehensive Information Retrieval(포괄적인 정보검색)
3. The LIGHTRAG Architecture
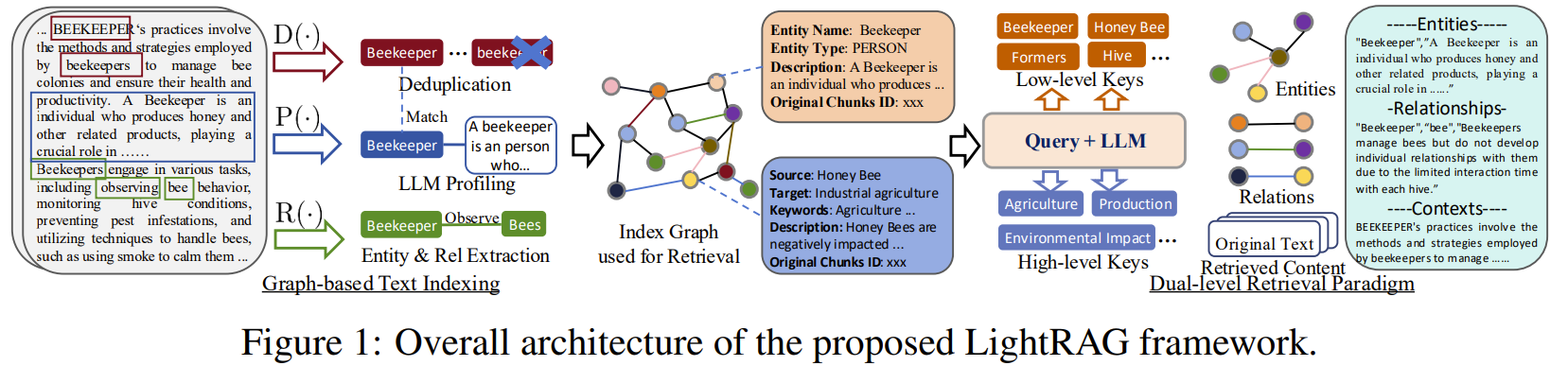
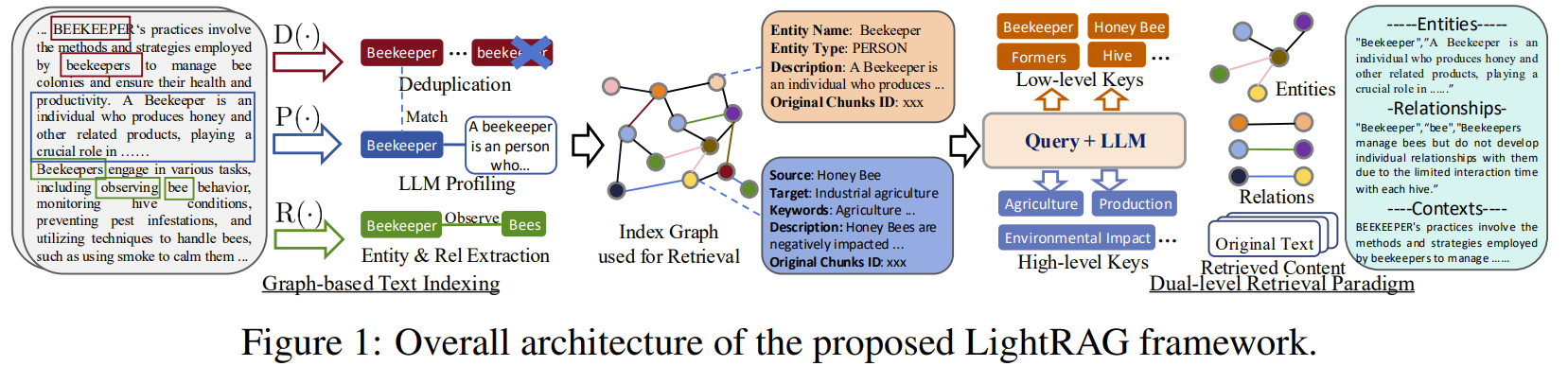
3-1. Graph-Based Text Indexing
문서를 그래프 형식으로 만듦
이 단계에서 LLM과 Prompt Template을 사용하여 텍스트를 분석하고 처리함

-
Extracting Entities and Relationships. R(·)
- 효율성을 높이기 위해 D를 여러 조각의 Dˆ로 분할
- 텍스트 데이터에서 개체(entities | nodes)와 그들 간의 관계(relationship | edges) 식별
- 심장 전문의(개체 | node), 심장병(개체 | node),
진단(관계 | edge)
- 심장 전문의(개체 | node), 심장병(개체 | node),
-
LLM Profiling for Key-Value Pair Generation. P(·)
- 개체(node) V와 관계(edge)에 대해 Key-Value (K, V) 생성
- Key : 효율적인 검색을 가능하게 하는 단어나 짧은 구문
- Value : 데이터에서 관련된 부분을 요약한 잛은 텍스트
- 관계(edge)는 여러개의 Key를 가질 수 있음
- 심장 전문의(개체 | node, Key), 심장병(개체 | node, Key),
심장 전문의는 심장을 주로 보는 의사로서 ~~ (Value)
심장병은 심장에 생기는 병으로 ~~ - 의사(개체 | node, Key), 심장병(개체 | node, Key),
의사는 사람의 건강을 ~~(Value)
- 심장 전문의(개체 | node, Key), 심장병(개체 | node, Key),
- 관계(edge)는 여러개의 Key를 가질 수 있음
-
Deduplication to Optimize Graph Operations. D(·)
- 서로 다른 Dˆ 조각에서 동일한 노드와 엣지 식별하여 병합하는 중복 제거
- overhead 줄여 그래프 크기 최소화, 효율적인 데이터 처리
-
Fast Adaptation to Incremental Knowledge Base (점진적 지식 베이스 적응)
- 데이터 변경 시 외부 데이터베이스 전체를 재처리할 필요 X
- 새로운 문서 D에 대해 동일한 Data Indexer (φ(·)) 시행
- 새로운 노드집합 Vˆ, Vˆ’, 새로운 엣지 집합 Eˆ, E’의 합집합을 취합
- 기존 연결의 무결성을 유지하며, 그래프 충돌이나 중복 없이 확장
- overhead 감소
3-2. Dual-Level Retrieval Paradigm
관련 정보를 특정 문서 조각과 복잡한 상호 의존성에서 검색하기 위함
- Generating Query
- Q : AI가 교육에 미치는 영향은 무엇인가?
- Specific Queries(세부 쿼리)
- 그래프 내의 특정 노드를 참조
- 특정 노드나 엣지와 관련된 정보를 정확하게 검색해야함
- ex) ‘AI’, ‘교육’
- Abstract Queries
- 넓은 주제, 요약 도는 포괄적인 주제
- ex) AI 교육에는 어떤 기술이 사용되는가?
AI가 성적에 미친 구체적인 영향은?
- ex) AI 교육에는 어떤 기술이 사용되는가?
- 넓은 주제, 요약 도는 포괄적인 주제
- Retrieval Paradigm
- Low-Level Retrieval(저수준 검색)
- 세부 정보 중심
- 그래프 내의 특정 노드나 엣지에 대한 정확한 정보 추출을 목표
- Hight-Level Retrieval(고수준 검색)
- 포괄적인 정보 중심
- 여러 관련 개체와 관계에 걸쳐 정보를 종합
- 세부 사항보다는 상위 개념이나 요약에 대한 정보
- Low-Level Retrieval(저수준 검색)
- Integrating Graph and Vectors for Efficient Retrieval
효율적인 검색을 위한 그래프와 벡터의 통합

- Query Keyword Extraction(쿼리 키워드 추출)
- k(l) : 세부적인 키워드
- ex) “AI”, “교육” 과 관련된 정보를 검색하는 데 사용되는 구체적인 키워드
- k(g) : 포괄적인 키워드
- ex) “인공지능과 교육” 과 같은 넓은 주제를 다루는 키워드
- k(l) : 세부적인 키워드
- Keyword Matching(키워드 매칭)
- 벡터 데이터베이스 사용
- k(l)은 벡터 데이터베이스를 사용하여 후보 개체들과 매칭
- 키워드와 데이터베이스에 저장된 개체들이 얼마나 유사한지 계산
- k(g)는 여러 개체들 간의 엣지를 찾는데 사용
- Incorporating High-Order Relatedness.(고차 연관성 통합)
-
검색된 노드와 엣지의 인접한 노드들을 추가로 수집
- ex) Q = 의사가 심장병을 진단한다
의사, 심장병 뿐 아니라 병원, 치료법 등과 같은 관련 개체들도 함께 제공 -
vi = 그래프 노드
-
V = 전체 노드 집합
-
Nv, Ne = 검색된 노드(v)와 엣지(e)의 1-홉 이웃 노드 집합
-
3.4 Complexity analysis of the LightRAG framework
프레임워크 복잡도 분석
- Graph-based Index phase
- LLM을 사용하여 텍스트의 각 조각에서 노드와 엣지를 추출(문서 or 데이터베이스)
- tokens / chunk size번 호출
- 추가적인 overhead 발생 X
- Graph-based retrieval phase
- 사용자 쿼리에 맞는 정보를 찾기위해 LLM이 관련 키워드 생성
- Vector-based Search
- 개체와 관계를 중점으로 검색
- 기존의 RAG처럼 텍스트의 특정 부분이 아니라, 문서에서 추출한 개체와 관계의 상호작용을 검색
- 검색 overhead 감소
- 기존의 GraphRAG에 비해 훨씬 효율적임
4. Evaluation
-
(RQ1)
How does LightRAG compare to existing RAG baseline methods in terms of generation
performance?LightRAG는 생성 성능 면에서 기존 RAG 기준 방법들과 어떻게 비교되는가?
-
(RQ2):
How do dual-level retrieval and graph-based indexing enhance the generation quality of LightRAG?이중 레벨 검색과 그래프 기반 색인이 LightRAG의 생성 품질을 어떻게 향상시키는가?
-
(RQ3):
What specific advantages does LightRAG demonstrate through case examples in various scenarios?다양한 시나리오에서 LightRAG는 어떤 구체적인 이점을 보여주는가?
-
(RQ4):
What are the costs associated with LightRAG, as well as its adaptability to data changes?LightRAG의 비용은 어떠하며, 데이터 변화에 대한 적응성은 어떤가?
4-1. Experimental Settings
-
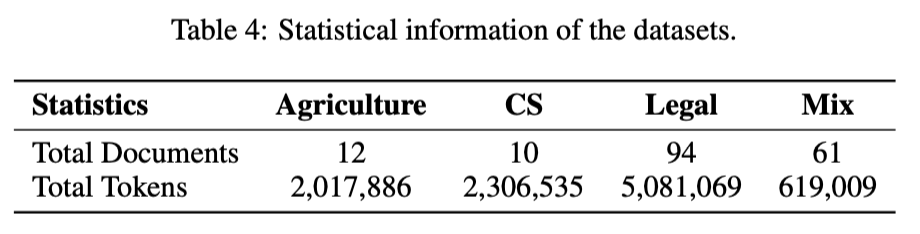
UltraDomain benchmark
- 428개의 대학 교과서에서 수집되었으며, 농업, 사회과학, 인문학 등 18개의 다양한 도메인을 포함
- https://arxiv.org/abs/2409.05591
-
농업(Agriculture), 컴퓨터 과학(CS), 법률(Legal), 혼합(Mix) 데이터셋을 선택
- 데이터셋 설명
- 농업(Agriculture): 이 도메인은 농업 관행에 중점을 두며, 양봉, 벌집 관리, 작물 생산, 질병 예방과 같은 주제
- 컴퓨터 과학(CS): 이 도메인은 컴퓨터 과학에 중점을 두며, 데이터 과학과 소프트웨어 엔지니어링의 주요 영역을 포함함. 특히, 추천 시스템, 분류 알고리즘, Spark를 사용한 실시간 분석 등의 머신러닝 및 빅데이터 처리에 대한 내용을 강조
- 법률(Legal): 이 도메인은 기업 법률 실무에 중점을 두며, 기업 구조조정, 법적 계약, 규제 준수, 거버넌스 등의 주제를 다루며, 법률 및 금융 분야에 초점
- 혼합(Mixed): 이 도메인은 문학, 전기, 철학 텍스트 등 다양한 자료를 제공하며, 문화적, 역사적, 철학적 연구를 포함한 폭넓은 학문 분야
- 데이터셋 설명
-
Question Generation

-
LLM에 5명의 사용자와 각각의 사용자에 맞는 5개의 작업을 생성하도록 함
-
LLM은 전체 corpus를 이해해야 하는 5개의 질문 생성
-
총 125개의 질문 생성됨
-
Baselines
- Native RAG
- 기존 RAG 시스템에서 표준 모델로 사용됨
- 원본 텍스트를 여러 조각으로 나누고, 이를 텍스트 임베딩을 사용하여 벡터 데이터베이스에 저장
- Query에 대해 벡터화된 표현을 생성하여 가장 유사한 텍스트 조각을 검색함
- RQ-RAG
- 쿼리를 여러개의 하위 쿼리로 분해
- 하위 쿼리는 rewriting(재작성), decomposition(분해), disambiguation(모호성) 해결 등의 기술을 활용하여 정확도를 높이는데 도움을 줌
- HyDE
- 입력 쿼리를 기반으로 LLM이 가상의 문서 생성
- 생성된 문서는 관련 텍스트 조각을 검색하는 데 사용됨
- 이를 바탕으로 최종 응답 형성
- GraphRAG
- LLM을 사용해 텍스트에서 개체와 관계를 추출하여 노드와 엣지로 표현
- 요소에 대한 설명을 생성
- 노드를 커뮤니티로 그룹화하여 커퓨니티 보고서를 생성해 글로벌 정보 수집
- 상위 수준의 쿼리를 처리할 때 커뮤니티를 탐색하여 포괄적인 정보 검색
- Native RAG
-
Implementation and Evaluation Details.

-
nano vector database 사용
https://github.com/gusye1234/nano-vectordb
- nano vector database (NanoVectorDB)는 대규모 벡터 집합에서 효율적으로 쿼리를 처리할 수 있도록 설계된 경량화된 벡터 데이터베이스입니다. 이 데이터베이스는 numpy와 같은 최소한의 의존성을 사용하여 구현되었기 때문에 다양한 프로젝트에 쉽게 통합할 수 있습니다.
주요 특징:
-
벡터 저장: NanoVectorDB는 벡터 데이터를 저장하고 관리할 수 있으며, 각 벡터에 대한 사용자 정의 필드를 지원합니다.
-
빠른 쿼리 처리: 최대 100,000개의 벡터 데이터를 관리하면서도, 쿼리 결과를 100밀리초 내에 반환하는 빠른 성능을 자랑합니다.
-
간단한 데이터베이스 연산: 데이터 삽입(업서트), 쿼리, 데이터 조회, 삭제 등의 기본적인 데이터베이스 연산을 제공합니다.
-
효율적인 저장: 대량의 벡터 데이터를 저장할 때도 효율적으로 인덱스를 생성하며, 예를 들어 100,000개의 벡터를 저장한 인덱스는 약 520MB 크기의 JSON 파일을 생성하고, 벡터 삽입 시간은 약 2초 정도 걸립니다.
NanoVectorDB는 특히 유사성 검색이 필요한 벡터 임베딩 기반 시스템이나 검색 증강 생성 시스템(RAG)과 같은 애플리케이션에 유용합니다. 이러한 시스템에서 벡터화된 데이터를 빠르게 검색할 수 있는 것이 핵심입니다.
사용법은 PyPi를 통해 쉽게 설치할 수 있으며, 데이터베이스 초기화, 데이터 삽입, 쿼리 처리 등의 API를 간단하게 제공합니다. 벡터 기반 검색이 필요한 프로젝트에 적합한 선택입니다.
더 자세한 정보는 여기에서 확인할 수 있습니다.
-
GPT-4o-mini 사용
-
chunk size = 1200
-
GraphRAG & LightRAG gleaning parameter = 1
- LightRAG, GraphRAG에서 데이터 추출과 검색 과정 최적화
- 그래프나 문서 조각에서 정보를 얼마나 많이 추출할지 조절함
- 1개의 엣지로 갈 수 있는 노드를 말함
-
평가 요소
- 답변에 대해 GPT-4o-mini가 아래 4가지 요소에 맞춰 어느 답이 더 좋은가 판단
- 답변이 제시되는 순서에 따른 편향을 방지하기 위해 답변의 위치 번갈아가며 배치
- Comprehensivness(포괄성)
- 답변이 질문의 모든 측면과 세부 사항을 얼마나 철저하게 다루는가?
- Diversity(다양성)
- 답변이 질문과 관련된 다양한 관점과 통찰을 얼마나 풍부하고 다양하게 제공하는가?
- Empowerment(이해력)
- 답변이 독자가 주제를 이해하고 정보에 근거한 판단을 내리도록 돕는데 얼마나 효과적인가?
- Overall(종합평가)
- 앞선 세 가지 기준에 걸친 종합 성능을 평가하여 가장 우수한 답변 선정
4-2 Comparison of LightRag with existing RAG methods(RQ1)
LightRAG는 생성 성능 면에서 기존 RAG 기준 방법들과 어떻게 비교되는가?
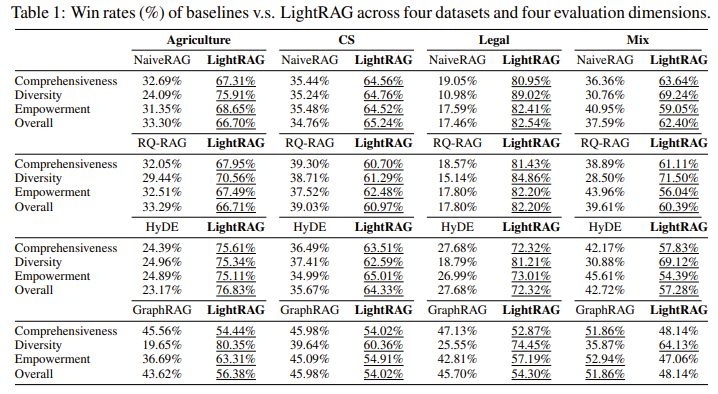
- 대규모 데이터에서 텍스트 기반 RAG보다 그래프 기반 RAG가 높은 승률을 보임
- 가장 큰 데이터셋인 Legal에서 확연히 드러남
- 다양성 향상
- Legal 데이터셋에 대해 LightRAG의 다양성의 승률이 높음
- dual-level retrieval paradigm의 역할이 크다고 봄
- 저수준과 고수준 모두에서 포괄적인 정보 검색을 가능하게 함
- 전체 맥락을 일관되게 포착함으로써 응답의 다양성을 높임
- GraphRAG 대비 우수함
- 대형 데이터셋에서 GraphRAG 보다 LightRAG의 승률이 더 높음
4-3 Ablation studies(RQ2)
이중 레벨 검색과 그래프 기반 색인이 LightRAG의 생성 품질을 어떻게 향상시키는가?
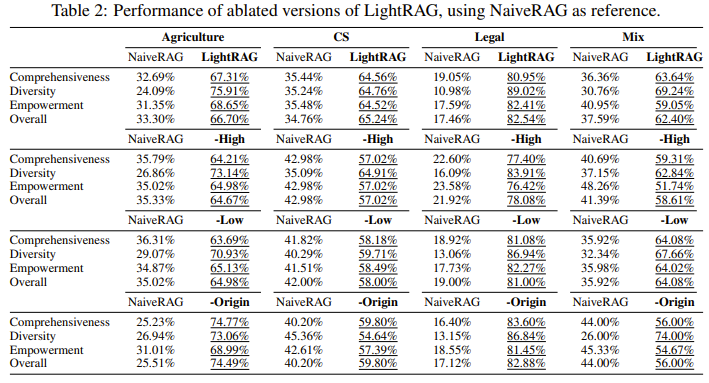
- 저수준 검색만 사용
- 전체적으로 성능이 저하됨
- 주로 구체적인 정보에 초점을 맞추기 때문에 발생하는 문제
- 포괄적인 통찰을 요구하는 복잡한 쿼리에 대해 필요한 정보 수집에 어려움을 겪음
- 고수준 검색만 사용
- 개체간의 관계를 활용하여 넓은 범위의 콘텐츠를 찾는데 초점을 맞춤
- 포괄성 측면에서 큰 이점, 광범위한 다양한 정보 수집
- 정확하고 상세한 답변이 필요한 작업에서 어려움을 겪음
- 하이브리드
- dual-level retrieval paradigm 사용
- 폭넓은 정보를 제공하는 동시에 구체적인 분석도 가능
- 균형 잡힌 성능
- Origin
- 검색 과정에서 원본 텍스트 사용 X
- 성능 저하가 두드러지지 않고 농업, 혼합 데이터셋에서는 오히려 성능 향상
- Graph-Based Text Indexing 과정에서 중요한 정보를 효과적으로 추출했기에 가능하다고 설명함
4.4 Case study(RQ3)
다양한 시나리오에서 LightRAG는 어떤 구체적인 이점을 보여주는가?
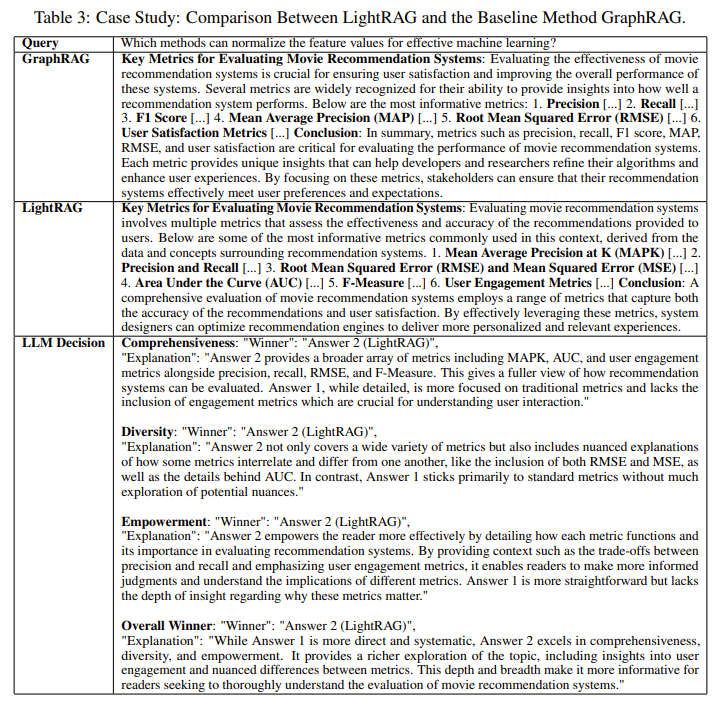
- 영화 추천 시스템의 주요 지표에 대해 질문함
- LightRAG가 평가의 모든 측면에서 우수하다고 말함
4-5 Model cost and adaptability analysis(RQ4)
LightRAG의 비용은 어떠하며, 데이터 변화에 대한 적응성은 어떤가?
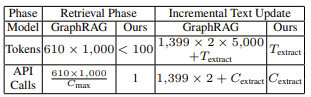
Figure 2 : Comparison of Cost in Terms of Tokens and API calls for GraphRAG and LightRAG on the Legal Dataset
- Retrieval Phase
- GraphRAG
- 1,399개의 커뮤니티 생성, 이 중 610개의 레벨 2 커뮤니티가 검색에 사용되었음.
- 각 커뮤니티 보고서는 평균 1,000개의 토큰을 사용
- 총 610 * 1,000 = 610,000 토큰이 사용됨
- 각 커뮤니티를 개별적으로 탐색해야 하기 때문에 API 호출 횟수가 총 토큰 수 / C_max가 되는것임
- LightRAG
-
100개 미만의 토큰을 사용
-
단 한번의 API 호출로 전체 프로세스 처리
-
그래프 구조와 벡터화된 표현을 통합하여 정보를 검색하는 메커니즘 덕분에 가능
-
대량의 정보를 사전에 처리할 필요가 없음을 의미
이 부분에 대해 어떻게 100개 미만의 토큰이 사용되는지에 대한 설명이 부실함
또한 왜 1번의 API호출을 사용 하는지에 대해 구체적인 설명이 없음
-
- GraphRAG
- Incremental Text Update
- GraphRAG
- 새로운 데이터셋이 추가될 때 기존 커뮤니티 구조 재구성
- 1399개의 커뮤니티를 각각 처리해야함
- 각 커뮤니티는 5000개의 토큰을 사용함
- 2를 곱하는 이유는 기존 데이터와 새로 추가된 데이터를 모두 다시 처리해야하기 때문
- LightRAG
- 새로운 데이터만 추가
- GraphRAG
Conclusion
이 연구는 RAG에서 그래프 기반 색인 방식을 통합하여 정보 검색의 효율성과 이해도를 향상시키는 새로운 발전을 소개함.
LightRAG는 포괄적인 지식 그래프를 활용하여 빠르고 관련성 높은 문서 검색을 가능하게 하며, 복잡한 쿼리에 대한 깊이 있는 이해를 지원함.
특징
- 이중 레벨 검색 패러다임: 구체적인 정보와 추상적인 정보를 모두 추출하여 다양한 사용자 요구를 충족시킴.
- 증분 업데이트 기능: 시스템이 최신 정보를 반영하고 새로운 정보에 신속하게 대응할 수 있도록 하여, 시간이 지나도 효과성을 유지함.
- 효율성과 효과성: LightRAG는 정보 검색과 생성의 속도와 품질을 크게 향상시킴.
- 비용 절감: LightRAG는 정보 검색 과정을 최적화하여 LLM 추론 비용을 절감함.
GraphRAG와 LightRAG 차이
Q : 심장병 관리 기업의 재무제표
GraphRAG
- ‘의료 기업’, ‘재무제표’ 커뮤니티가 검색
- 커뮤니티는 테이블과 같은 개념
- 두 커뮤니티는 연결되어 있지 않음
- Q가 두 커뮤니티 모드와 연관이 있기 때문에 시스템에서 기존 커뮤니티 간에 새로운 엣지를 생성하여 필요한 정보 연결
- 두 커뮤니티 간의 관계가 만들어지고 여기서 필요한 정보를 통합하여 제공
검색 후 노드간의 엣지 연결
LightRAG
- 상위 검색
- ‘심장병 관리’, ‘기업 재무’라는 큰 주제를 설정하고 관련 정보를 검색
- 하위 검색
- 재무제표와 관련된 구체적인 데이터 항목 탐색
- 세부 재무 항목(매출, 자산, 부채 등)을 검색하고 엣지를 탐색
처음부터 노드간의 엣지가 있기 때문에 빠르게 정보를 찾을 수 있음
