오늘은 dqn의 같은 계열로 dueling dqn을 알아보겠습니다!
기존의 dqn은 output으로 모든 action에 대한 q value 값을 출력하는 것 이었습니다. 그래서 dqn의 핵심인 st가 들어오면 cnn을 사용합니다.
dueling dqn은 q value ft을 output으로 출력하는 것이 아닌, advantage ft과 state value ft 두 가지를 output으로 출력합니다. q network가 이제는 두 개의 스트림을 가져서 하나는 (s,a)에 대한
advantage ft값을 출력하고, 하나는 state에 대한 state value 값을 출력합니다.
뒤에 있는 state value ft은 action과 관계가 없기에 action independent합니다. 그래서 output으로 두 개의 함수를 출력하게 되는데 아래 그림을 보면 이해가 수월합니다.
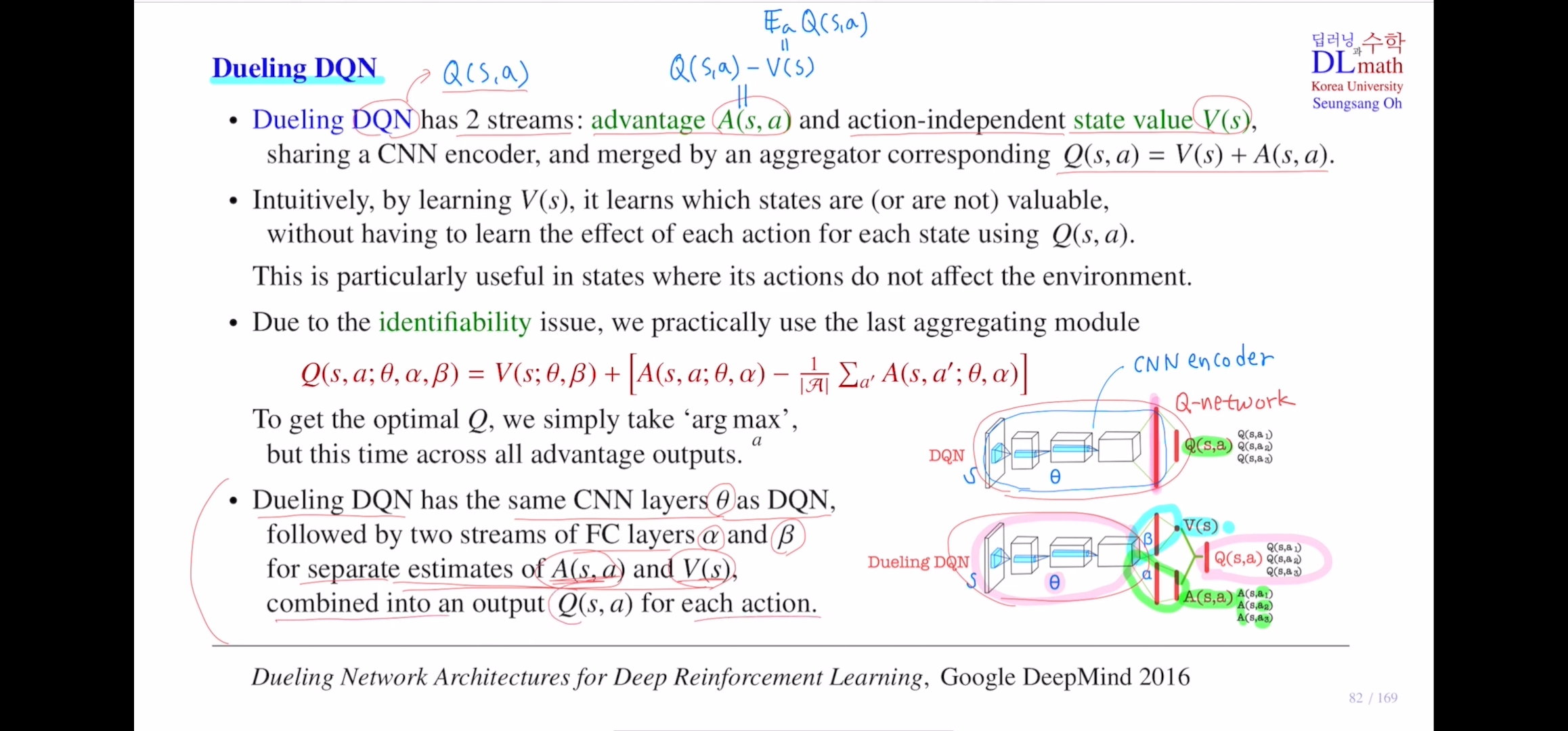
먼저 dqn을 살펴보면 input으로 sr가 들어오면 이것에 대해 cnn을 지나 output으로 모든 action에 대한 q값들을 출력합니다. 그래서 q network라고 합니다.
256future vector를 Fc를 통해 q값들을 출력합니다. 이 안의 cnn구조는 dim이 아주 큰 input vector를 함축시킨다고 해서 Cnn encoder라고도 합니다.
이 cnn encoder부분을 dueling dqn에서는 어떻게 하는지 확인해보면 마찬가지로 동일한 st가 input으로 들어오면 dqn의 output인 q값이 아닌, advantage ft과 state value ft의 값을 output으로 출력합니다. advantage ft은 모든 action에 대해 출력하기에 action개수만큼 나옵니다. 그에 반해 state value ft은 action independent이기에 딱 하나의 값만 출력하게 됩니다. 그래서 원칙적으로 advantage ft을 출력하는 net과 state value ft을 출력하능 net을 따로 만들어야 하지만 파라미터가 너무 많아지기에 여기서는 앞부분은 같이 공유합니다. 하나의 파라미터 세타를 같이 사용하다가 마지막 부분에서는 ad는 알파라는 파라미터를, s v ft에서는 베타라는 파라미터를 사용하게 됩니다.
이렇게 두 값을 구하게 됩니다. 궁극적으로 loss ft을 구하기 위해서는 q값을 찾아야 합니다.
이 q값은 ad ft값과 s v ft값을 그냥 더하면 되는 것입니다. (v는 q ft의 기댓값을 취한 것이기 때문입니다.)
모든 action에 대한 평균값을 빼줬다는 것이기에 ad ft값이 양수가 나왔다는 말은 현재 action이 다른 action에 비해 좋은 것임을 알 수 있습니다.
따라서 q ft은 ad ft과 state value ft을 더해서 얻을 수 있게 되는 것 입니다.
마지막 부분을 agrgregating이라고 합니다.
사실 q ft과 ad ft은 비슷한데 state value ft을 대입하고자 이를 만든 것 입니다. 이는 현재 state가 가치가 있는지 였습니다. 사실 강화학습에서는 action을 위해 q ft이 더 중요합니다. 하지만 현재 state이 좋은지 참고하면 좋을 때도 많이 있습니다. 예를 들어 action이 별로 영향이 없을 때 현재 state이 가치가 있는지를 확인할 때 사용됩니다.
이 dueling dqn을 사용하면 몇가지 문제가 있는데
1) identifiability 문제 : aggregating module을 사용하여 빼줍니다.
++highest q값을 찾을 때 v는 영향을 잘 미치지 않기에, 더하기 전에 A에서 maximize시키는 action을 찾고 선택합니다.
state value ft V(s)값을 직접 계산하면 어떤 장점이 있는지 알아보겠습니다.
여기에서는 value and ad ft에 대한 saliency map이라는 것이 있습니다. 이는 cnn이 estimate할 때 어디를 주로 보는지 붉은 색으로 하이라이트한 것 입니다. 일종의 attention과 비슷한 것 입니다.
아타리 게임중에서 enduro게임인데 자동차게임입니다.
위의 그림은 안전한 상태, 아래 그림은 위험한 상태입니다.
첫번째는 앞에 자동차가 멀리 있기에 어떠한 action을 취해도 상관이 없어 ad ft을 계산할 때 거의 아무것도 참고하지 않습니다. 그렇기에 딱히 attention을 취하지 않습니다.
하지만 그에 반해 value ft은 현재 상황이 좋은지 좋지 않은지를 평가하는 것이기에 차가 멀리 있다는 것을 보고 안전한 상태라고 인식하게 됩니다. 그래서 멀리 수평선에만 집중해서 바라보게 됩니다.
아래 그림을 보겠습니다.
바로 앞에 차가 있습니다. ad ft을 계산할 때는 왼쪽 차는 피했지만 앞에 차가 있기에 현재 action을 취할 때 가장 중요한 것은 앞의 차가 됩니다. 따라서 앞의 차에 집중합니다.
value ft은 멀리 있는 차도 중요하지만 당연히 앞의 상황도 중요하기에 앞 또한 집중해서 봅니다.
강화학습에서는 위의 그림처럼 어떤 action을 취하는지가 중요하지 않을 때가 있습니다. 이때는 state value ft이 더 중요하게 됩니다.
dueling dqn은 매 action에 따라 state을 기준으로 state value값이 업데이트 됩니다. 따라서 훨씬 효율적으로 state value를 학습할 수 있습니다.

하지만 이를 합쳐서 사용할 때는 identifiability문제가 마지막 aggregating module에서 생긴다고 했습니다. 이 부분을 확인해보겠습니다.
마지막에 더해버리면 unidentifiable로 특정한 값으로 identify할 수 없게 됩니다. 다시말해 state value ft값과 action ad ft값을 unique하게 찾을 수 없게 됩니다. q가 10이라고하면 v ad가 1 9 or 8 2 어떻게 될지 모릅니다.
v 7 a 3이라고 했을 때, GD를 사용할 때는 q값을 기준으로 정하게 됩니다. 그렇기에 파라미터를 업데이트할 때 8 2로 기준을 두고 업데이트할 수 있는 것 입니다. 제대로 estimate할 수 없게 됩니다. 
따라서 이를 해결하기 위해 어느 하나를 기준으로 정합니다. A를 기준으로 잡을건데 best action을 선택했을 때 ad값이 0이 되게 잡습니다. 이 말은 맨 위에서 optimal policy를 적용하먼 ad값이 0이 되는 것을 적용하겠다는 것 입니다.
그러기 위해서 ad값을 아래의 대괄호와 같이 잡아줍니다. 그렇다면 왜 이것이 best action에서 ad값이 0이 될까요?
highest q값을 갖는 action이나 highest ad ft값을 갖는 action은 같은 action입니다.
그렇기에 best action a* 을 취하면 A-maxA는 0이되기에 Q=V가 됩니다.
이렇게 되면 각각 estimator역할을 하게 되어 unidentifiable하지 않게 만들 수 있습니다.
highest ad ft값을 갖는 action을 찾을 때 변동성이 너무 커서 stability가 불안정합니다. 따라서 각 action에 대한 평균값을 사용하게 됩니다.
그래서 아래 최종 식이 max 대신 mean을 사용하게 되는 것 입니다. 실제 dueling net에서 V는 마지막에 실수값 하나만 출력합니다. ad ft은 모든 actiom에 대해 action의 개수만큼 디멘젼을 갖는 벡터를 출력합니다. 모든 action에 대해 아래 식을 적용할 때는 모든 action에 대한 vector값에 동일한 V값을 모두 더해줍니다.
원래 max가 있어야 의미가 맞는데, max->mean으로 바꾸었기에 조금 더 작은 값을 빼주게 되는 것 입니다. 그렇기에 max-mean만큼 오차가 생깁니다. 이런 오차가 생기기는 하지만 max보다는 mean이 더 stable하기에 optimalization이 더 stable한 효과가 있습니다. 그렇기에 이론적으로는 optimal한 action의 ad ft값으로 max값을 취해야 하지만, 평균값을 사용하여 변화가 훨씬 더 적기 때문에 더 stable하게 학습할 수 있다는 장점이 생깁니다.
이것은 identifiable에 문제가 생기지 않습니다. 왜냐하면 입실론 그리디 policy에서는 q값을 극대화 하는 action을 찾는 것 입니다. v는 영향이 없기에 ad를 극대화하는 action을 찾는 것과 같습니다. 모든 action에서 모두 같은 값을 빼는 것이기에 ad값을 극대화하는 action을 찾는것에는 아무 문제가 없는 것 입니다.

고려대학교 오승상 교수님 강화학습 강의 : https://youtu.be/8E22UY6XXfc?si=de5v3YFN5VxDTF76
