오늘은 ResNet SENet에 대해 알아보자!
GoogleNet과 VGG의 모델은 역전파 진행 시 기울기 소실 문제로 인해 layer층을 깊게 쌓을 수 없었다. 이 문제를 해결한다면 더욱 깊은 층을 쌓아 좋은 모델을 만들 수 있을 것이다. 이를 ResNet이 residual block으로 해결하며 152 layer층을 쌓고 우수한 성능을 보였다.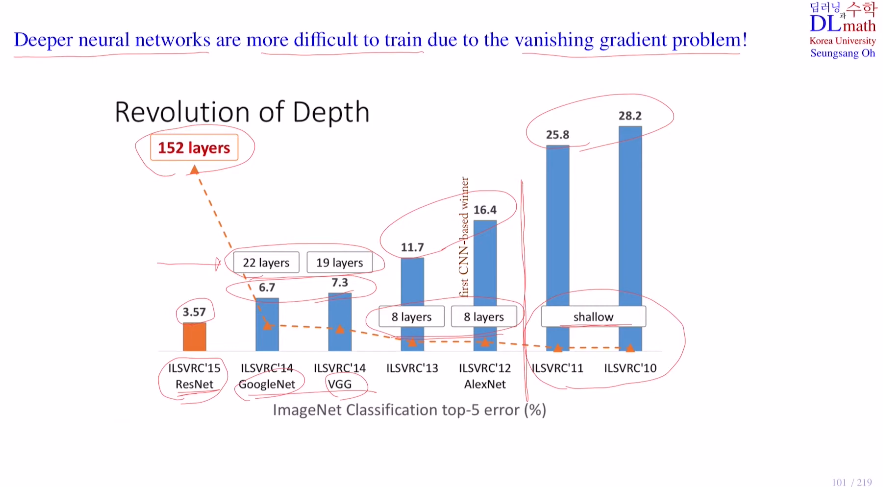
VGG-19와 34laye plain 모델은 큰 변화가 있지는 않지만 34는 더 layer가 많기에 정교할 순 있으나 vanishing gradient 문제를 해결해야 한다.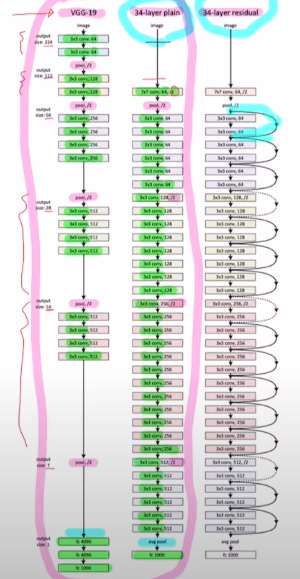
ResNet은 residual block을 사용하여 이를 해결했다.
이 방법은 input x를 두 conv layer를 거친(conv 개수는 유동적으로 조절) F(x)와 identity shortcut x와 더하여 내보낸다.(더하는 것은 concat이 아닌 element-wise합) 이 방법으로 기존의 모델을 크게 바꾸지 않고 Max pooling도 적게 사용한다. 또한 많은 양의 파라미터를 학습해야 하는 FC layer도 한 번만 사용한다.
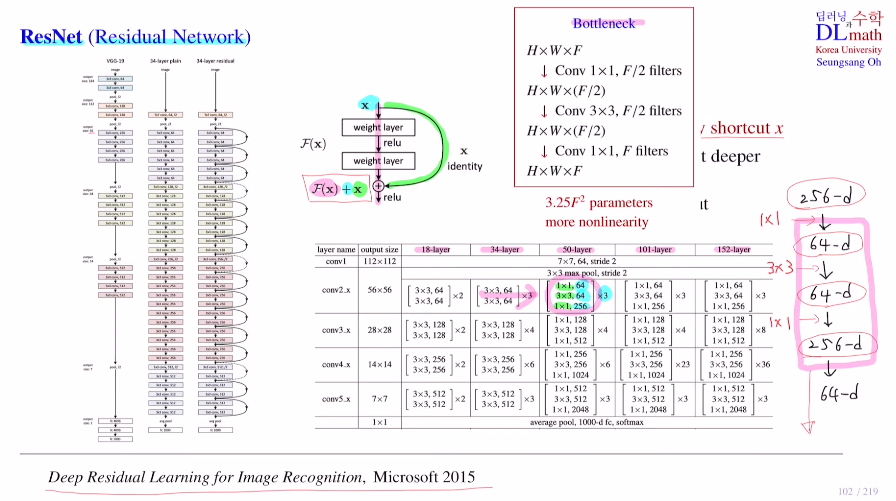
50 layer이상을 보면 초반 256채널을 1x1으로 64개로 줄이고 3x3을 64유지하고 1x1으로 다시 256으로 늘리는 작업을 반복한다.
왜 이렇게 줄였다 늘렸다 반복할까?
이 이유는 이전 포스터에서 언급했던 Bottleneck구조 때문이다.
이를 통해 non-linearity를 많이 사용하고, 특히나 채널 수를 줄인다음 3x3를 거치게 하고 다시 1x1으로 채널수를 늘리기에 파라미터 수를 많이 줄일 수 있다는 장점이 있다! 그렇기에 layer도 더 깊게 쌓을 수 있다.
중간의 점선은 조금 다른데, x의 size가 56x56x64인 경우에서 stride를 2로 잡았기에 F(x)가 28x28x128이 된다. 그렇기에 이 둘을 더할 수가 없는 것이다. 따라서 이런 경우에만 x를 identity로 보내는 것이 아닌 stride2를 사용하고 feature map의 개수를 맞추기 위해 1x1 conv를 사용하여 128로 맞춰준다.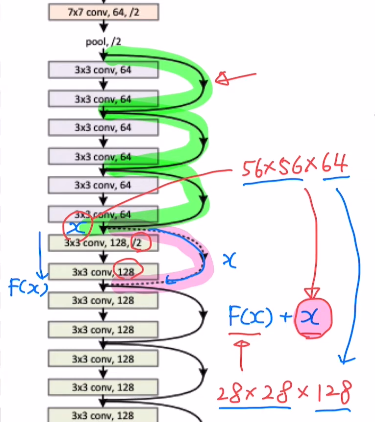
이제 identity mapping이 왜 중요한지 알아보자!
우선 forward pass부터 알아보자.
identity shortcut을 이용해 더해주었는데, 점화식을 이용하여 풀어보면 아래와 같이 쭉 나온다. 그렇게 되면 빨간 식과 같이 초기값과 F들의 합으로 표현이 가능하다.
즉, k->K로 갈 때 단순히 conv layer를 거친 F만 가는 것이 아니라 xk자신도 가는 것이다. 따라서 forward pass로 갈 땐 xk에 이 residual만 더하면 되고, 따라서 기존 weight matrix를 연속적으로 곱한 값들에 비해 단순 더하기로 효과적인 것이다!
(multiple-> additive)
다음으로는 backpropagation을 알아보자.
기울기 소실의 문제는 어떻게 해결될까?
cost에 대한gradient를 계산하면(초기 xk까지), K로 분해했을 때 위의 forward때 식을 가져와 미분하여 아래와 같이 (1 - ~ )로 표현 가능하다!
이렇게 되면 이것도 곱이 아닌 합으로 표현되기에 0으로 가는 것을 굉장히 막을 수 있게 되는 것이다! 따라서 vanishing gradient를 해결할 수 있다.
residual learning으로 layer가 깊어지더라도 identity mapping으로 인한 adding때문에 효과적인 모델과 함께 기울기 소실 문제를 피할 수 있게 되는 것이다.

ResNet의 18/34 모델은 그냥 conv layer를 거쳤고, 50/101/152 모델은 bottleneck 구조를 사용하였다. bottleneck 구조는 복잡해 보이지만 사실 파라미터의 수를 줄이고 layer를 깊게 쌓을 수 있게 한다.
why? 1x1을 함으로 feature map의 채널 사이즈를 줄이고, 이로 인해 파라미터 개수를 줄인 후에, 다시 1x1으로 faeture map의 채널 사이즈를 늘린다!
아래를 예시로 들었을 때, 18/34는 72K개 파라미터가 필요하고, 50/101/152는 68K개 만큼의 파라미터가 필요한 것이다. 이렇게 기존의 모델을 크게 바꾸지 않아도 residual block으로 인해 효율적이고 깊은 모델을 쌓을 수 있게 된다.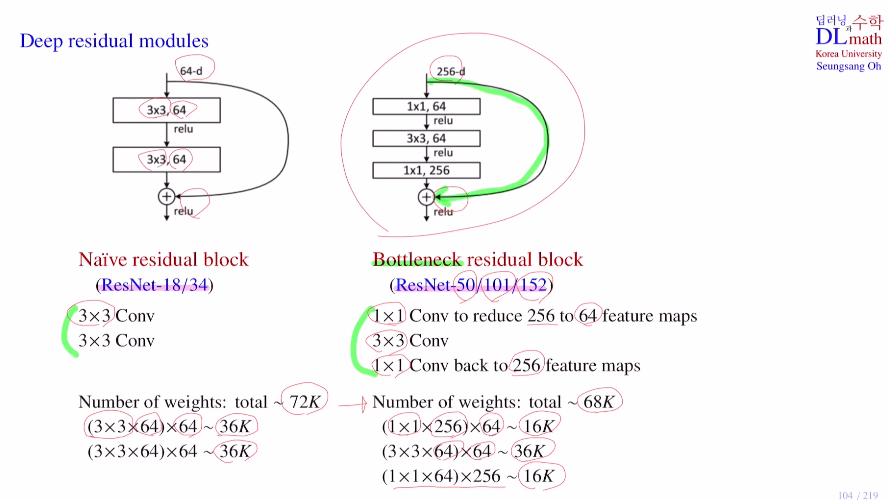
이제는 SENet(Squuze-and-Excitation Network)에 대해 살펴보자!
top5 error rate를 2.25%까지 내린 훌륭한 알고리즘이다. 또한 기존 CNN network에서 크게 변화를 주지 않고, 부분적으로 적용시킬 수 있기에 활동도도 높다.
기본적으로 CNN은 KxK kernel size를 갖는 필터를 적용하면 채널수가 F일 때, local receptive fields (: KxKxF 아래 파란색)를 통해 다음 layer의 하나의 픽셀 값이 된다.
spatial information(KxK이기에) and chnnel-wise information(매 채널마다 적용) 이 둘을 합쳐서 그 다음 레이어의 픽셀의 값이 되는 것이다. 이렇게 정보를 갖는feature를 output으로 꺼내는 것을 convolution이라고 한다.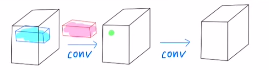
SENet은 이 Convolution가 kenel size만큼 정해진 부분만 보기에 전체적인 feature map의 특징을 잡기에는 어려움을 지적하고 이를 해결한다. 즉, local이 아닌 channel-wise global spatial information을 얻고 싶어 하는 것이다.
(공간적인 정보를 수합한 하나의 정보도 얻고 싶다!)
Q. 그렇다면 kernel size를 훨씬 키우면 되지 않는가?
하지만 이렇게 되면 학습해야 할 파라미터가 너무 많아진다. 그렇기에 필터의 사이즈는 키우고 싶지는 않다.
=> 따라서 여기서 SE block이라는 것을 생성한다.
Conv layer를 거치고 다음 conv를 실행하기 전에, 필요에 따라 사이에 SE block을 끼워 넣는다. 이를 통해 잠시 모양을 변형하고 다음 layer로 보낸다.
1) Squeeze
여기서 channel-wise global average pooling을 통해 전체 feature map의 값을 반영한다. how?) 각 채널 당 픽셀 값들을 평균 낸다. 이를 zc라고 한다. 그렇다면 각 채널 당 하나의 값이 나오니 1x1xC가 나온다.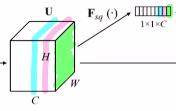
2) Excitation
이 zc를 2개의 FC layer를 거친다. 이를 통해 s를 얻는다.(Relu를 거쳤기에 모든 값들은 0~1)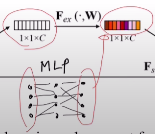
3) Recalibration
이 부분은 각 채널들이 중요한 채널이 있고 비교적 중요하지 않은 채널들이 있을 텐데, 각각 가중치를 주어 rescaling을 하고자 한다.
->바로 이 s를 이용해서!
기존 각 채널의 모든 픽셀에다가 s의 값들을 곱해준다. 이렇게 채널들의 값을 재보정해준다.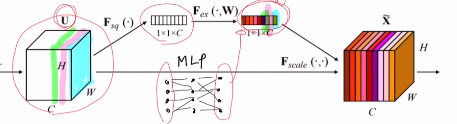
이러한 SE block방법을 통해 전체적인 feature map의 특징을 부여할 수 있게 되는 것이다. SE block은 필요에 따라 simple하게 사용할 수 있다.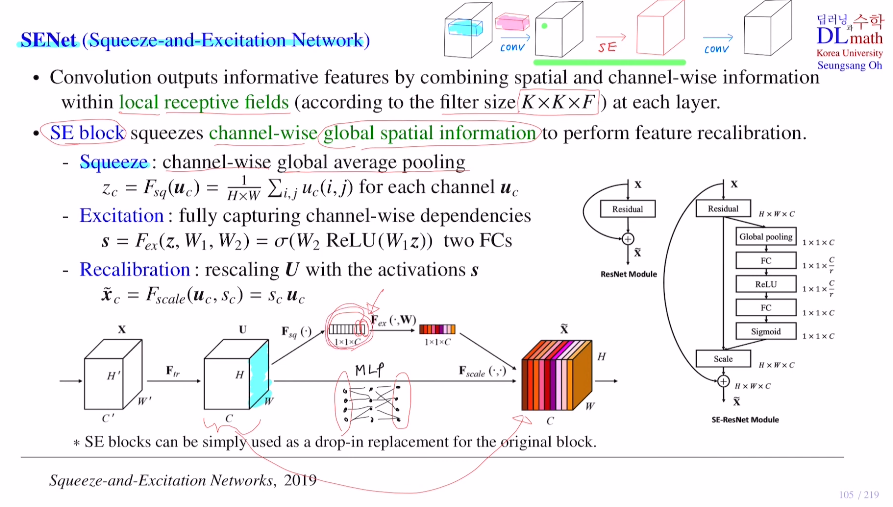
이를 residual block과 합하여 SE block을 실행하면 아래와 같이 더욱 효율적인 SE block활용이 가능하게 된다. conv를 거친 것에 identity shortcut을 더하기 전 SE block으로 전체적 특징을 부여하고 identity shortcut을 더하는 것이다!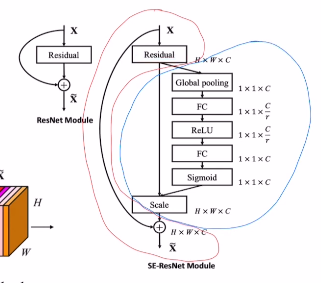
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=DFdjW7a55b0&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=25
