변형된 convolution과 conv에 쓰이는 dropout에 대해 알아보자!
첫 번째로 알아볼 convolution은 Dilated Convolution이다.
정해진 kernel size만큼 sliding하는 것이 아닌, 인위적으로 면적을 넓히는 방식이다.
Q. 이것이 왜 필요할까?
우선 classification task에서 Conv layer와 Max pooling을 반복적으로 사용하며 translation invariance(조금씩 움직여도 모두 같은 객체로 잘 인식) 특징을 갖게 된다.
이에 더 나가서 Segmentation을 진행하면 픽셀별로 세세하게 구분할 수 있어야 한다. 이것은 translation invariance와 정반대이다. 위치가 조금만 바뀌어도 픽셀단위로 움직여서 탐지해야 하기 때문이다! 이를 dense prediction task라고 한다.
classification은 layer가 깊어질 수록 픽셀 당 전체 이미지 정보가 들어가기에 좋지만(enlarge the receptive field), segmentation의 경우는 각 픽셀의 공간적 정보를 잃어버리기에 좋지 않다.
=> 이를 해결하기 위해 Dilated Convolution을 사용한다!
kernel size를 키우지 않고, conv layer를 늘리지 않고 효율적인 방법이다.
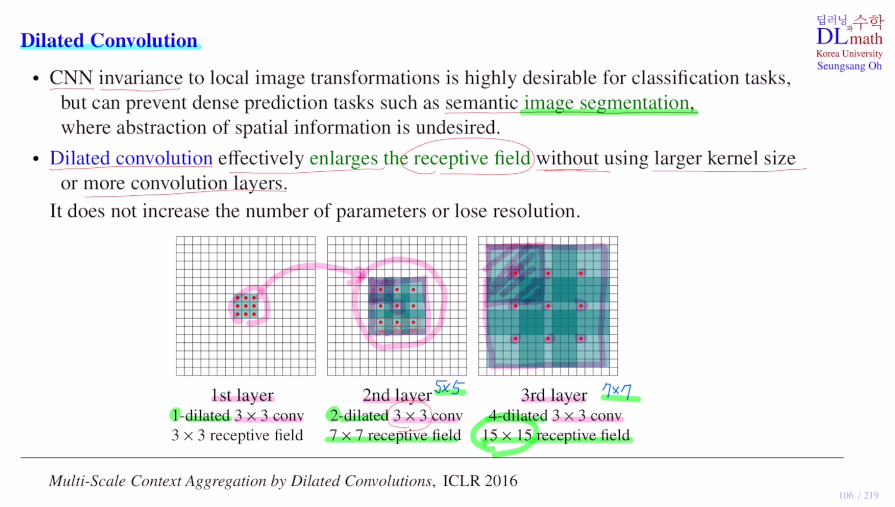
기존 방법은 아래의 그림과 같이 3x3을 적용하면, 2nd layer의 한 픽셀은 이전 layer의 9개 픽셀이 모아진 것이기에 실질적으로 2nd layer의 3x3 구간은 5x5 receptive field를 갖게 된다. 이제 3rd layer로 넘어가서 3x3을 보면 이전 5x5 receptive field가 넘어온 것이기에 7x7 receptive field를 갖게 되는 것이다.
이를 효율적인 방법으로 해결해 보자.
1st layer에서 넘어오는 9개의 값이 함축된 하나의 값을 2nd layer에서 각 각 하나씩 띄어서 구성하자! 이렇게 되면 기존 5x5 이 아닌 7x7 receptive field를 갖게 된다.각 픽셀당 거리가 2가 되었기에 이를 2-dilated convolution이라고 한다.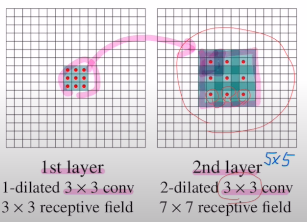
다시 3rd layer로 4-dilated conv로 넘기면 한 픽셀은 이전의 7x7 receptive field에서 넘어온 것이므로 총 15x15 receptive field를 얻게 된다.
이렇게 함으로 kernel size는 늘리지 않고 receptive field를 늘리며 layer를 깊게 쌓지 않음으로 우리가 원하던 '전체적인 그림의 윤곽을 보면서 공간적 위치를 잃지 않는 효과'를 얻을 수 있게 되는 것이다!
꼭 이러한 segmentation 상황 이외에도 classification에서 이미지 크기가 너무 클 때, dilated convolution을 사용하여 더 빠른 시간 내에 전체적인 그림의 윤곽을 볼 수 있다.
이제 또 다른 Depthwise Separable Convolution을 알아보자.
이는 Depthwise conv + Pointwise conv로 light weight CNN을 구현할 때 사용한다. 즉, 파라미터 수나 계산량을 적게 해야 할 때 사용한다.
예를 들어 스마트 폰이나 가전제품에 딥러닝 알고리즘을 적용시킨다고 하면 스케일이 작기에 최소한 가벼운 알고리즘을 넣어야 한다.
기존 알고리즘을 보면 아래와 같이 weights 개수는 KKCF로, 계산량은 KKCNNF가 된다.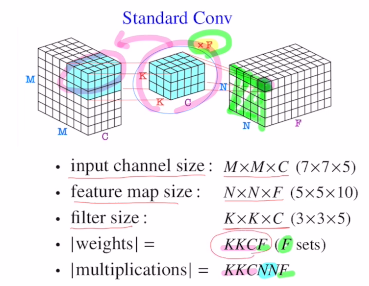
이제 Depthwise conv + Pointwise conv를 진행해 보자.
기존 3x3 conv를 1x3->3x1으로 나누었을 때, 실제로 receptive field는 동일하지만 학습해야할 파라미터가 줄어들고 non-linearity를 더 많이 쓸 수 있다. 이번에는 이렇게 하지 않고 채널별로 따로 한다. 이렇게 채널별로 따로 가기에 기존에 결과값이 하나의 픽셀로 가는 것이 아닌 각 채널별로 값이 나오게 된다. 그렇기에 output 채널 수는 필터 하나여도 똑같은 C개 채널이 되는 것이다. Depthwise Conv로 필터 하나만 사용하기에 weight 개수는 KKC개, 계산량은 KKCNN이다.
Q. 이렇게 하면 채널들 사이의 값은 합쳐지지 않는 것이 아닌가?!
이를 해결하기 위해 1x1 Conv를 F개 사용해준다. 그렇기에 Standard Conv와 최종 output size는 같게 된다.
그리고 파라미터 개수와 연산량은?!
weight 개수는 KKC + 1x1xCxF개이고, 연산량은 KKCNN + CxFxNxN이 되기에 기존보다 훨씬 줄어들게 된다.
비율로 따지면 1/F+1/K^2만큼 줄어들게 된다.
이번에는 Conv layer에 dropout을 적용시키는 방법을 확인해 보자.
기존 MLP에서는 random하게 node(즉, feature)를 지운다. 이를 똑같이 생각하면 random하게 픽셀을 지우는 것이다.(standard dropout)
하지만 픽셀 하나는 큰 정보를 가지고 있지 않기에, 지운다고 해서 어떤 feature를 없애는 것이 아니다. 또한 픽셀 하나를 지운다고 해도 바로 주변 픽셀들이 제거한 픽셀과 비슷한 값을 가지고 있기에 큰 의미가 없다.
즉, 이런 방법으로는 overfitting을 줄일 수가 없다.
그래서 feature를 지워야 하는데, 가장 간단한 방법은 feature map을 없애는 것이다. 이것이 spatial dropout이다.
또한 인접한 픽셀들을 묶어서 임의로 없애는 cutout도 있다. square amsk로 각 feature map마다 이 cutout dropout을 적용하게 된다.
마지막으로는 Conv에 적용시키는 것이 아닌, Maxpooling에 적용시키는 Max-pooling Dropout이 있다. 아래와 같이 2x2로 max pooling을 한다면 필터에 임의로 몇개를 masking하고 남은 것 중 maximum을 취하는 것이다. 이렇게 함으로 전체적인 값이 낮아지는 효과를 얻을 수 있다.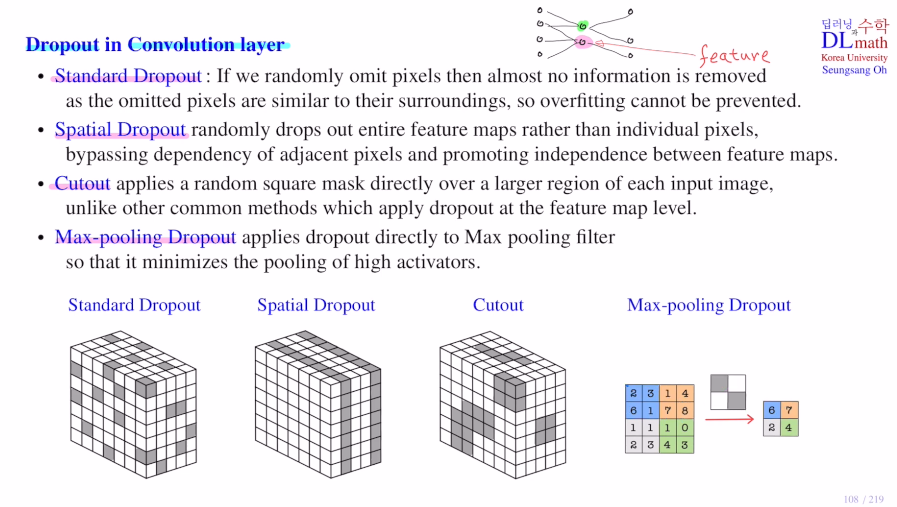
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=Y8WPW58SLaY
