이번에는 기존까지 배운 down sampling과는 반대로 up sampling에 대해 알아보고, U-Net에 대해 알아보자!
U-Net: Convolutional Networks for Biomedical Image Segmentation - 논문 리뷰
를 참고하면 이해가 수월할 것 같다.
CNN에서는 주로 Conv layer와 Maxpooling을 사용하는데 이를 사용하면 점점 feature map의 사이즈가 줄어들게 된다. : down sampling
이렇게 되면 resolution 즉, 해상도가 점점 줄기에 이와 반대로 up sampling을 통해 늘리고 싶은 것이다. 이미지를 low resolution -> high resolution로 generating하는 방법이다.
앞부분 특징을 고도화 하는 작업은 Encoding이라고 하며 generate하는 작업은 Decoding이라고 한다.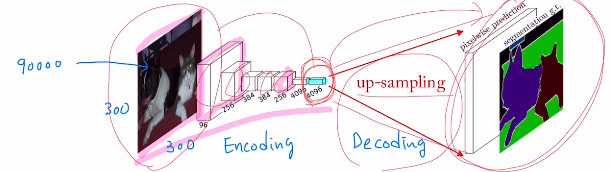
예를 들어 2x2를 4x4로 보낸다고 해보자. 단순히 아래와 같이 적용시키면 될까?
그렇지 않다. 우리가 원하는 것은 high resolution을 해야 하는데 이를 만족시킬 수 없기 때문이다.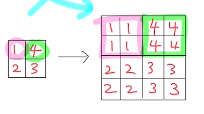
Q. 어떻게 하면 매끄럽게 확장할 수 있을까?
1) Non-learnable : 딥러닝을 사용하지 않고 수학적인 방법(manual feature engineering)으로 사용한다. interpolation method로 사이에 빈 값을 nearest, linear, cubic과 같은 방법을 채우는 것인데, 데이터 분석을 진행할 때 Null값에 효율적으로 채울 수 있는 방법이기도 하다.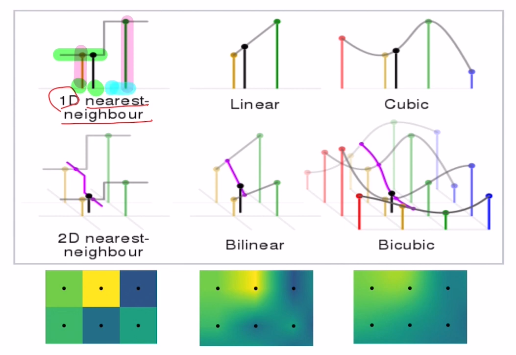
하지만 위와 같은 방법으로는 예를 들어 4x4-> 300x300으로 보내면 굉장히 흐릿한 high resolution을 갖지 못하는 값을 도출한다. 따라서 아래와 같은 딥러닝을 이용해 학습 가능하게 하여 이용한다.
2) Learnable : 두 가지 방법이 있는데, Transposed convolution, Fractionally-strided convolution이 있다.
Transposed convolution
우선 Convolution의 가장 큰 특징 중 하나는 이미지의 위의 위치에 있는 정보는 위로 전달되고 아래 위치에 있는 정보는 아래로 전달되는 positional connectivity가 있다는 것이다. 또 다른 특징은 3x3xF필터로 인해 3x3xF정보가 하나의 픽셀 값으로 가는 many-to-one relationship이 있다.
이것을 반대로 하고 싶은 것인 Transposed convolution이다. positional connectivity가 있어야 하고, one-to-many relationship이 있어야 한다.
기존 conv는 conv opteration을 conv matrix를 이용하여 표현한다. 이를 transpose 시켜서 transposed conv matrix를 사용한다. matrix형태만 가져올 뿐 weight는 새로 학습해야 한다.
아래의 예시를 보자.
기존 3x3 conv를 사용할 때, 이를 conv matrix 를 통해 4x16 16x1 = 4x1로 구할 수 있다. (conv matrix는 9개의 weight만 있기에 이 9개만 학습하면 된다.)
이제는 이 conv matrix를 transpose시켜서 해보자. 16x4 4x1 = 16x1으로 확장시킬 수 있는 것이다. 이렇게 되면 구조가 같기에(weight 위치와 0 위치들) 16x4 개의 weight를 학습할 필요 없이 똑같이 9개만 학습하면 되는 것이다!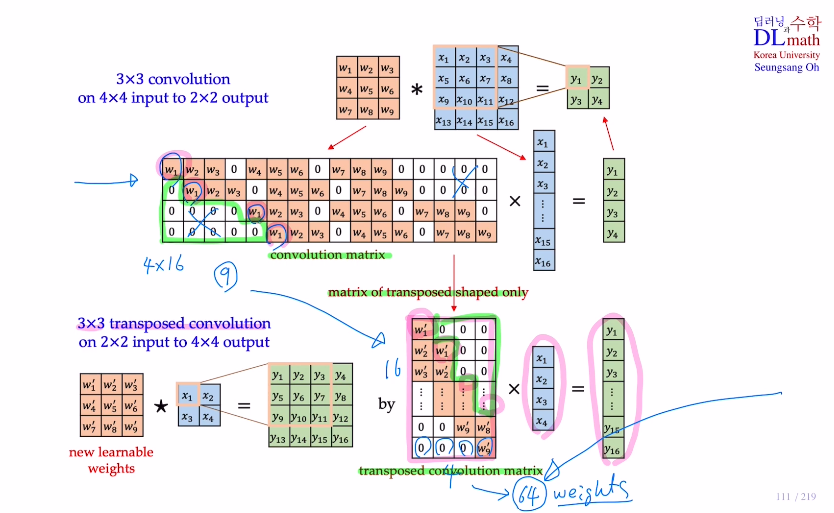
따라서 이렇게 활용하면 Encoding에 사용되었던 파라미터 숫자와 비슷하게 Decoding에서 사용되기에 약 2배 정도 늘어난다고 생각하면 된다.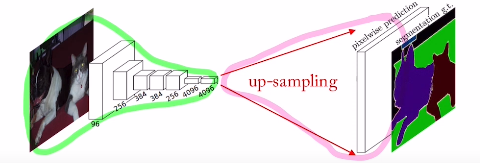
Fractionally-strided convolution
이제는 Fractionally-strided convolution에 대해 알아보자.
기존의 convolution과 정반대로 하는 것인데, 아래의 예시를 통해 설명해보자.
우리의 목표는 3x3크기의 conv로 5x5를 만드는 것이다. 하지만 그대로 확장하면 나머지는 바깥 부분이 모두 zero padding이 되어 좋지 않다. 따라서 픽셀들을 하나씩 띄어서 안 쪽에다가 zero padding을 하는 것이다.(한 칸씩 늘리고 stride를 1로 움직이기에 1/2strided 3x3 conv라고 한다. : 1/n strided면 n-1칸을 zero padding한다.)
이것이 fractionally-strided이다.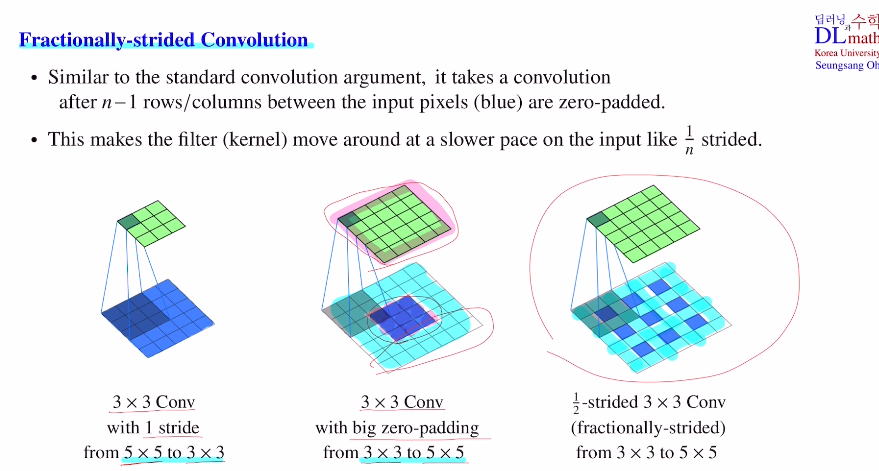
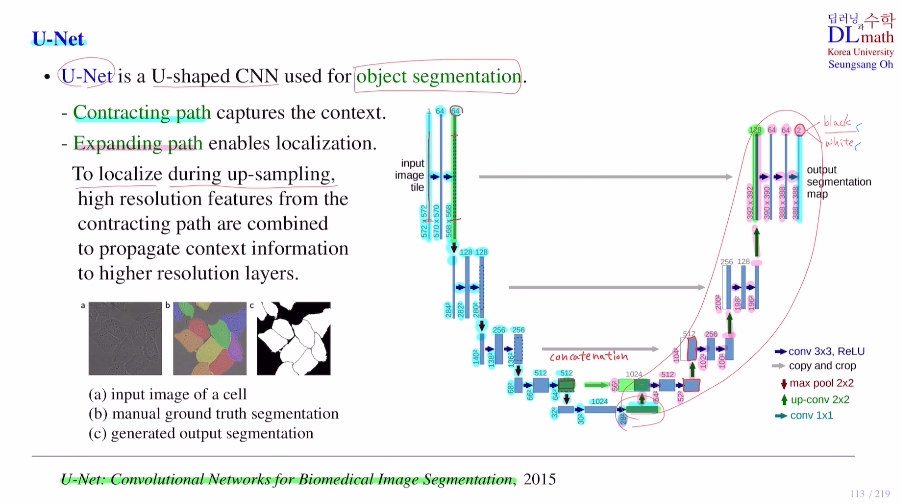
이제는 up sampling을 사용한 대표적인 모델 U-Net을 알아보자.
이 목적은 object segmentation을 위한 것이다.
왼쪽의 부분은 contracting path로 CNN 구조(classification을 위한), 오른쪽 부분은 expanding path로 segmentation을 하기 위해 up-sampling으로 loacalization을 하는 부분이다.
contracting path로 572x572 image를 28x28x1024가 되었다. 그 후 expanding path를 진행하는데 중요한 점은 segmentation을 하기 위한 위치 정보이다. 이를 앞에 사용했던 feature map들을 가져와서 concat해준다.(이미지의 사이즈가 맞지 않기에 왼쪽 그림을 잘라서 붙여준다. : copy and crop) 이를 통해 high resolution feature를 사용하고, 이렇게 진행하며 최종적으로 마지막에 1x1conv를 거치며 388x388x2(하나는 black, 하나는 white로 segmentation)가 된다.
이 결과값을 사람이 segmentation 한 image값과 loss를 구하여 학습하게 되는 것이다!
(input은 572x572였기에 잘라서 388x388로 맞춰준다.)
추가적으로 1x1 conv를 사용하는 이유?
크게 세 가지 이유가 있다.
예를 들어 feature map 3개가 있을 때, 1x1 filter를 사용하면 아래와 같이 하나의 feature map이 탄생하게 된다.
이는 한 픽셀에 대해서만 진행하기에, 3x3 filter와 같이 공간적인 부분 정보를 포함하지 않는다. 단순히 앞의 채널에 적당한 weight값만 곱하기에 receptive field효과는 없다. 하지만 위에서 보는 것과 같이 마지막에 activation ft으로 non-linearity를 취해준다. 이를 통해 모델을 좀 더 정교하게 만들 수 있다는 특징이 있다.
두 번째로는 feaure map 단위로 보았을 때 각각을 노드로 생각하고 weight sum을 진행시키는 fully connected 효과를 얻을 수 있다.
세 번째로 많은 것을 변형시키기 않고 단순히 feature map의 개수만 조절하고자 할 때 유용한다. 아래 세 가지 경우를 예시로 보자.
single 3x3 conv는 3x3xFxF로 학습해야 할 파라미터 개수가 나온다.
1x3, 3x1 conv는 1x3xFxF + 3x1xFxF 이다. 앞에 비해 파라미터 개수도 적고 non-linearity도 많다.
Bottleneck은 필터개수 절반만 사용하여 1x1xFx(F/2) + 3x3x(F/2)x(F/2) + 1x1x(F/2)xF 로 구조는 복잡하지만 학습해야 할 파라미터 수가 훨씬 줄고 layer가 깊어 non-lienarity도 더 많다.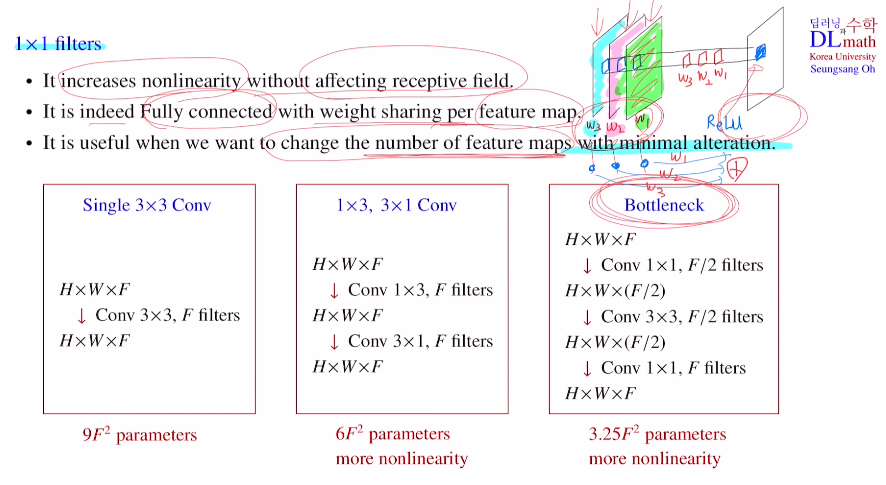
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=Q478gQQRKRs
