이제부터는 RNN과 관련하여 알아보자!
Feedforward neural network와 Recurrent neural network를 비교해보자.
우선 MLP는 MNIST의 경우 정보가 한 쪽 방향으로만 흐른다. 즉, 이전의 정보들이 필요하지 않고 현재 데이터만 본다.
그에 반해 RNN은 주식 데이터의 경우 하루하루 지날 수록 데이터가 쌓이고, 이 경우에 하루의 데이터를 가지고 내일의 주식을 예측하는 것은 불가능하다. 이전의 데이터들을 이용해서 예측해야 한다는 것이다. 정보가 여러방향으로 흐른다.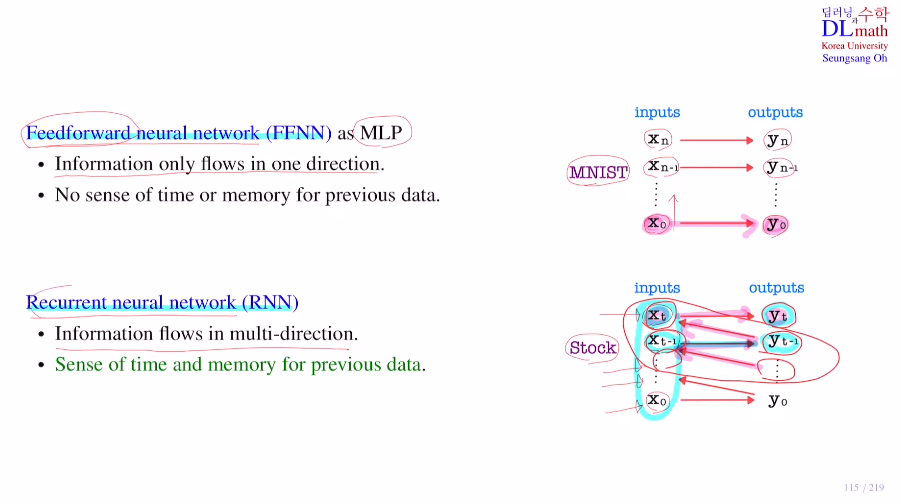
이렇게 주식과 같은 데이터들을 이전 것들을 기억하며 이를 기반으로 예측해야 하는데, 어떻게 실현할 수 있을까?
우선 RNN방식은 아니지만 TDNN: Time Delay Neural Network를 알아보자.
시간 개념이 들어간 sequential data를 다루며, 단순한 모델에 사용된다.
MLP를 이용하는데 input을 window로 정해진 며칠간의 데이터를 묶어서 넣는다.
ex) 내일을 예측하기 위해 오늘 기준 n일 전까지의 연속된 데이터를 한 번에 MLP input으로 넣는다.
마치 CNN의 1-d conv에서 stride가 1인 것과 같다.
MLP를 다룰 때 중요한 조건은 iid(independent & identically distributed)이다.
VAE 이해하기 위한 내용(2) - iid / 확률분포
를 참고하면 좋은데 독립 항등 분포이어야 한다는 것이다.
즉, 아래의 input(t), input(t-1), input(t-2), ... 들이 모두 독립임을 보장받아야 한다는 것이다. (xt, xt-1, xt-2,...)들은 당연히 시간의 개념이 포함되어 있지만 이를 학습할 때는 무시할 수 있어야 한다는 것이다.
정리하자면, TDNN을 사용할 때 window size=4 라면 이 4일 말고 나머지는 고려할 수 없다는 것이다.

이제는 TDNN의 단점을 살펴보자.
만약 이 단점들이 문제가 되지 않는 경우라면 TDNN이 RNN보다 단순하기에 더 빨리 학습되고 우수한 경우가 나올 수 있다.
단점 1) 적당한 window size를 정해야 한다.
window size를 잘 잡는 것이 성능에 큰 영향을 미치는데, 너무 작게 잡으면 long dependency를 잡을 수 없다. 너무 크면 학습 파라미터가 너무 많아지고 행여 데이터가 window size보다 작거나 하는 경우에는 노이즈가 들어갈 수 있다.
Atari game에서 공이 내려올 때 하나의 화면만으로는 커서를 어디로 할지 예측하기 어렵다. 4개 정도 화면을 받으면 대충 어디로 공이 올지 예측할 수 있게 된다. 이는 강화학습의 대표적인 모델인 DQN은 4개의 프레임을 갖고 진행한다.
주식을 예측하는 경우에는 꽤 긴 주기를 갖고 있기에 window size를 크게 해야 하지만, long-memory problem이 일어나기에 TDNN은 적합하지 않다.
단점 2) fixed window-size
하이퍼파라미터로 정해줘야 하는데 고정되어 있다. 예를 들어 10로 잡았을 때, 대부분 두 단어로 이루어진 문장의 경우 노이즈가 많이 섞이게 된다. 혹은 너무 긴 문장의 경우 제대로 인식하지 못하는 경우가 발생한다. 이런 경우에는 TDNN은 적합하지 않다.
단점 3) 과거 데이터에 대한 기록이 정확히 있지 않다.
이는 가장 큰 단점으로 TDNN은 MLP이기에 iid를 만족해야 하므로 window size 밖에 있는 데이터들은 전혀 고려되지 않는다.
또한 아무리 window size를 조절하여 데이터가 들어오지만 이를 시퀀스라고 인식하지는 않는다. multidimensional feature vector로 "단순히 데이터가 4개 있다." 라고만 인식하는 것이다. 이를 Unaware of the temporal structure라고 한다.
이러한 단점들이 있지만 이를 고려하지 않아도 되고, 단순한 모델을 원할 때는 유용하게 사용된다.
이제 본격적으로 RNN에 대해 알아보자.
중요한 점은 TDNN과 달리 들어오는 데이터들을 시퀀스로 인식해 temporal structure를 인식한다는 점이다.
기존 FFNN는 들어온 하나의 input만을 가지고 예측을 한다. 하지만 RNN(LSTM)은 현재 들어온 input 뿐 아니라 이전에 들어왔던 input들도 같이 활용한다.
how?
current input xt 뿐 아니라 past input들에 대한 중요한 정보 일부를 저장해둔 hidden layer에서 hidden layer로 가는 hidden state vector ht들도 가져온다.
아래의 그림을 보면 x0가 들어왔을 때 h0를 저장해두고, 다음 x1이 들어올 때 h0를 가져와 같이 사용하여 h1을 만들어 낸다. 이렇게 x0와 x1의 정보가 들어 있는 h1을 이용해 y1을 만든다.(y1으로 예측한다.)
이를 반복하면 나중 xt가 들어왔을 때, ht는 이전의 값들의 정보 ht-1과 함께 만들어 지는 것이다. ht로 yt를 만든다.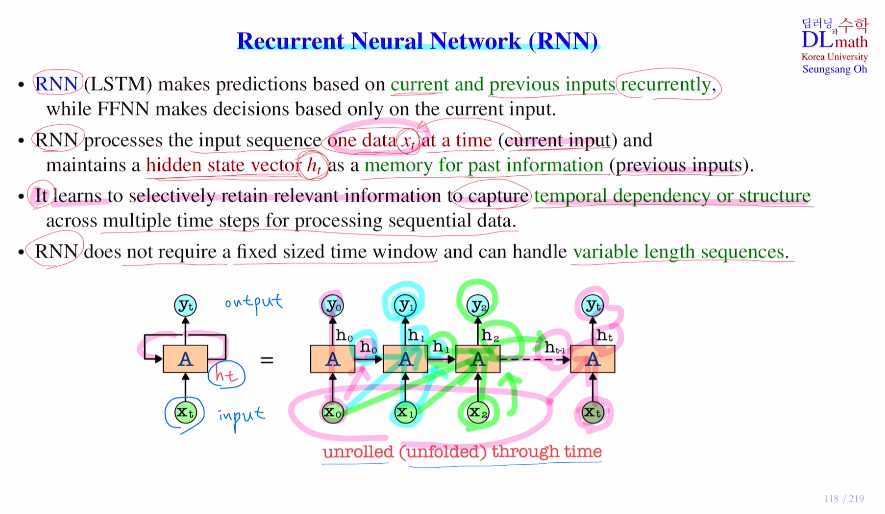
이 RNN이 사용되는 세 가지 형태를 확인해보자.
1) one to many
image captioning에서 그림 하나가 input으로 왔을 때, A girl rides a bicycle 을 만들자.
하나의 input으로 들어왔는데, 많은 input을 보냈기에 one to many라고 한다.
2) many to one
sentiment classification(ex) 문장이 호인지 불호인지)에서 문장(단어 시퀀스)이 들어오고 하나의 결과값이 나오기에 many to one이다.
3) many to many
Machine Translation. 번역의 경우 문장이 들어오고 문장이 나가기에 many to many이다.
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=jM3kGYmCr88
