이번 포스트에서는 RNN에서 weight를 업데이트 하는 방식인 backpropagation through time이라는 BPTT에 대해 알아보자.
Simple RNN
매 입력 time step t에 대해 아래와 같이 표시한다.
input:xt, output:yt
prior hidden state : ht-1, current hidden state : htRNN에서 학습해야 할 파라미터는 Wxh, Whh, Why가 있다.
(input->hidden, hidden->hidden, hidden->y)
결국 ht를 만들어 이를 통해 yt를 구하는 것이 목표인데,
ht = tanh(Wxhㆍxt + Whhㆍht-1 + bh) 가 되고
yt = σ(Whyㆍht + by) 가 된다.
아래의 맨 오른쪽 예시의 경우 각 FFNN으로 위 식처럼 만드는 것이다. 이 때, weight matrix들에는 t가 없는데, 각 time step마다 동일한 weight matrix들을 가지고 사용하고 이것을 업데이트 하기 때문이다.
hidden state의 node수는 하이퍼마라미터로 정해준다.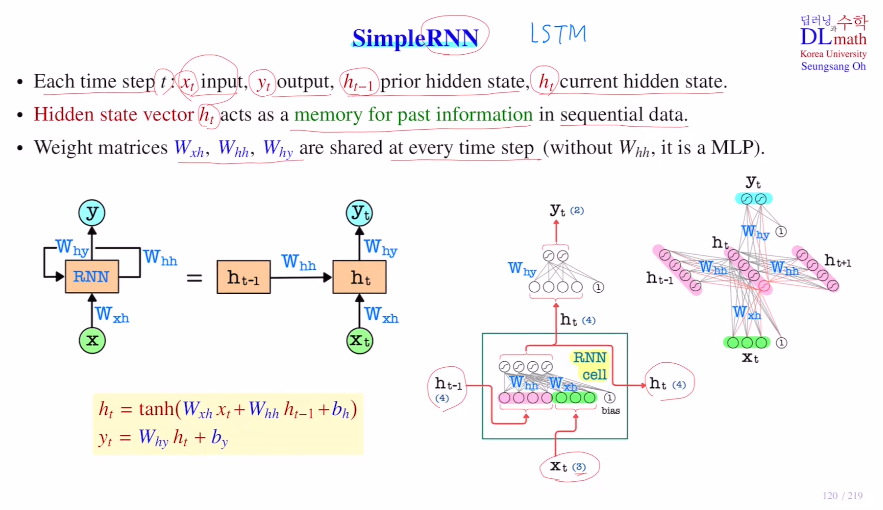
이제 이를 어떻게 backpropagation을 진행하는지 알아보자.
RNN에서는 시간 개념이 있기에 Backpropagation throuh time : BPTT 이라고 한다.
기존 DNN은 Cost ft을 minimize시키는 방향으로 weight를 업데이트 한다. 하지만 RNN은 이 backpropagation을 사용할 수 없기에 BPTT로 temporal dependencies를 control해준다.
앞에 설명했던 바와 같이 업데이트 할 Wxh(U), Whh(V), Why(W) 세 가지 weight matrix들이 있다. 아래 unfold network에서 모두 같은 값을 가진 채로 시작한다. 그렇기에 부담이 없다.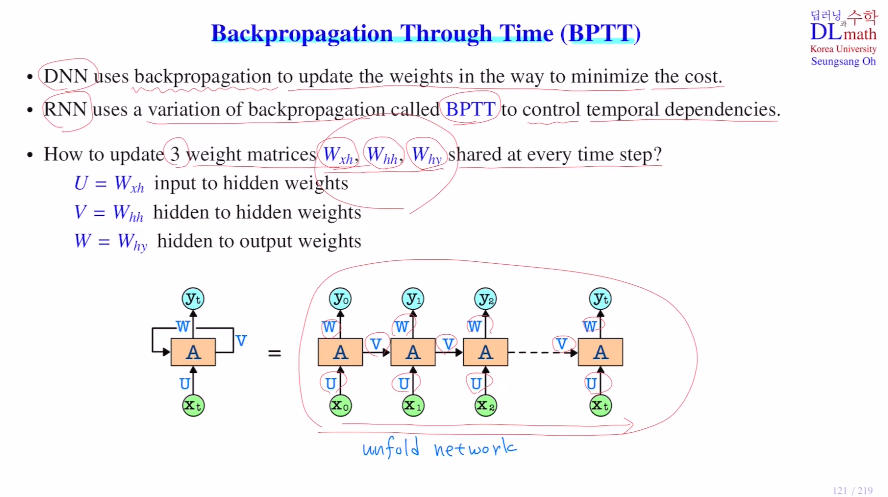
이제 weight update 를 알아보자.
위에서 말한 U, V, W는 각 layer에서 같은 값을 가진다.
만약 다 다르다면 (U0,U1,U2,.. 등), gradient를 계산할 때 모든 구간에서 미분을 해야 한다.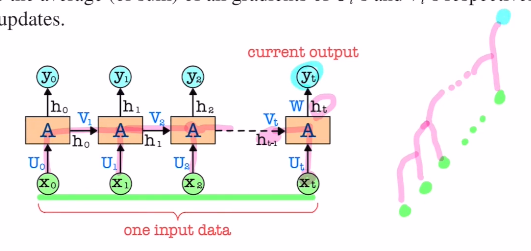
위와 같은 구조를 자세히 그리면 아래와 같다.
Q. 이런 구조에서 weight update를 어떻게 진행할까?
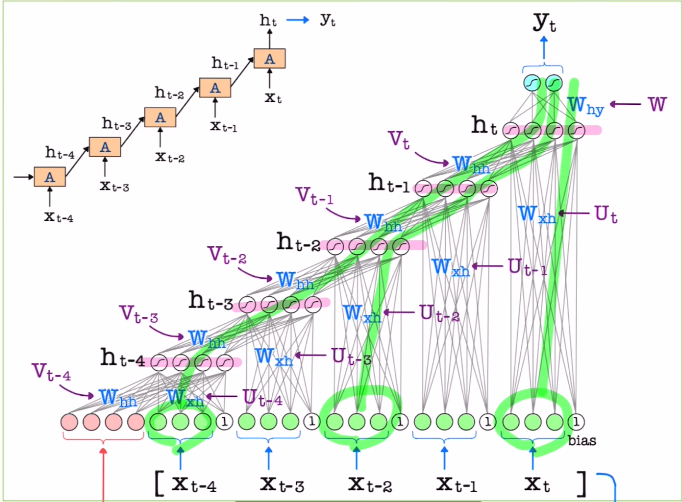
각 weight에 따라 동일한 weight matrix를 사용하지만 backpropagation에서 gradient값은 다르게 나온다.
BUT! 우리는 모두 같은 weight matrix를 쓰기로 했다. 따라서 업데이트 할 때는 같은 값을 이용해 업데이트를 진행해야 한다.
=> 따라서 이 목적을 위하여 평균을 내거나 합해서 하나의 값으로 취한 후, 한 번만 업데이트만을 진행하게 된다.
이렇게 모든 time step마다 같은 weight를 share하기 때문에, layer가 깊어질 수록 계산량은 늘어나지만 학습해야 할 파라미터 수는 증가하지 않는다!
이것이 Backpropagatoin through time의 핵심이다.
하지만 time step이 너무나 커진다면?!
중간에 짤라서 생각하게 되는데 이 방법이 다음 포스터에 언급할 truncated backpropagation throuh time 이다.
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=-QYPDtDQf_U&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=28
