이번 포스터는 RNN의 대표적인 모델 LSTM을 알아보자.
장기기억과 단기기억을 이용하는 LSTM: Long Short-Term Memory로 long-term dependency문제와 vanishing/exploding gradient 문제를 해결하기 위해 만들어졌다.
long-term dependency
가까운 거리의 정보는 잘 전달이 되겠지만, 앞 부분의 정보는 다가올 수록 정보 손실이 생겨 유지하기 어렵다. 그렇기에 중요한 정보가 앞 부분에 있었다면 좋은 결과가 나오지 않게 된다. 이렇게 갭이 큰 경우 앞부분 정보 손실이 일어나는 문제를 long-term dependency라고 한다.
하나의 hidden state에 모든 정보를 넣고 넘겨야 하는데, 하나에 넣기는 쉽지 않을 뿐더러 그렇다고 해서 무작정 hidden state의 dim을 키워버리면 학습해야 할 weight parameter가 많아진다.
따라서 LSTM에서는 hidden state 이외의 cell state를 만들어 중요한 정보와 중요하지 않은 정보를 선별하여 기억한다.
RNN에서 Whh와 Wxh가 있었던 것과 같이 LSTM에도 존재한다.
맨 위는 기억을 저장하는 line이라고 한다면, 처음 line은 기존 기억에서 중요하지 않은 것을 지워주는 역할을 하고, 두 번째와 세 번째는 새로운 정보를 cell state에 저장하는 작업을 한다. 마지막 두 line을 통해 cell state의 정보를 밖으로 꺼내 output을 만드는 작업을 한다.
즉, 안에 있는 것들이 long term으로 사용할지 short term으로 사용할지 조절해 주는 장치라고 생각하면 된다.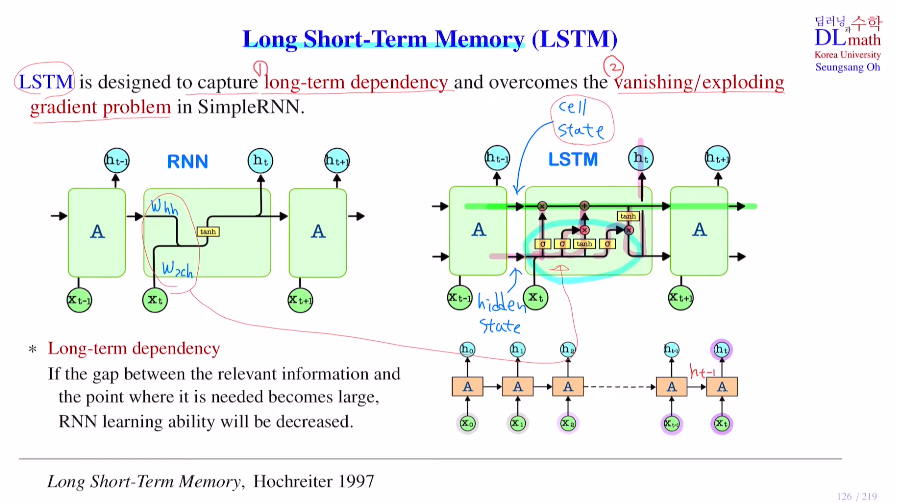
우선 LSTM의 기본 구조를 살펴보자.
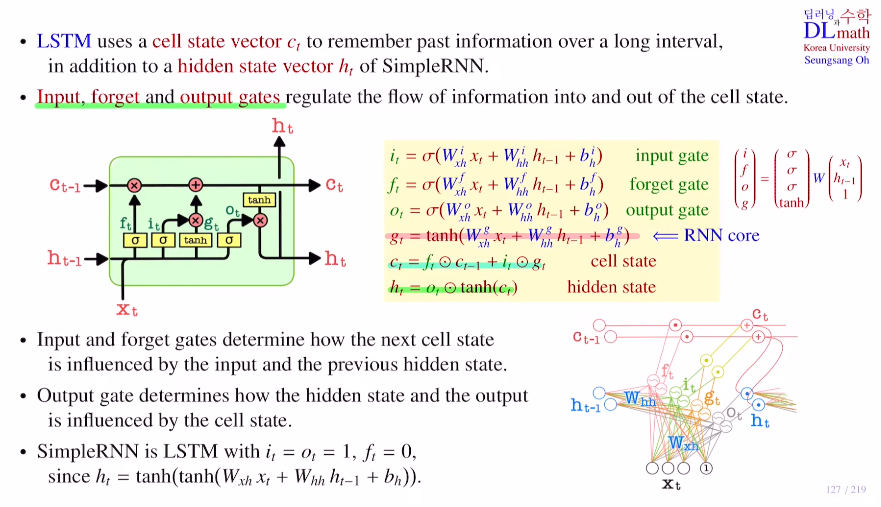
cell state vector ct는 long interval의 과거 정보를 가지고 있는다고 생각하면 된다. hidden state vector와 cell state vector는 사이즈가 동일하다.
긴 문장을 가져와 번역을 할 때, 긴 문장이 input vector로 들어오는데 예를 들어 apple이 중요한 단어일 경우 이를 저장하고 a와 같은 관사는 중요하지 않기에 저장하지 않는 방식으로 cell state vector에 저장한다. 그렇기에 cell state vector가 효율적으로 함축된 정보를 갖고 있게 된다. : input, forget, output gate로 이루어져 있다.
LSTM구조에는 simple RNN구조 gt가 있고 input it, forget ft, output ot gate를 추가적으로 만든 것이다.
1) forget gate 적용
새로운 current input xt를 가지고 과거의 정보를 얼마나 지울지 결정한다.
예를 들어 xt가 새로운 문장이 시작하는 주어라면 forget gate를 통해 cell state의 값(앞의 정보)들을 많이 지우는 것이다.
2) input gate 적용
current input을 새로운 cell state에 넣는 방법이다.
current input의 새로운 정보는 gt인데, 이를 cell state에 얼마나 넣을 지도 조절해야 하기에 input gate it를 이용하여 gt를 cell state에 얼마나 넣을지를 조절하는 것이다.
=> 이 두 1)2)를 통해 ct = ftㆍct-1 + itㆍgt (ㆍ:element-wise 곱)을 만드는 것이다.
3) output gate 적용
현재 current input을 참고해서 ht를 만들고자 한다.
우선 cell state vector ct에(이 ct는 xt에 대한 정보를 포함하고 있다.) tanh를 씌우고, xt를 참고하여(sigmoid를 씌워 0~1값으로 변경) 이 ot와 element-wise곱을 통해 ht를 만든다.
이런 구조로 이루어져 있기에 LSTM은 RNN보다 weight parameter개수가 4배 많다.(Wg,Wo,Wf,Wi)
또한 LSTM은 it=ot=1이고, ft=0일 때, Simple RNN와 같기에 gt를 RNN Core라고 한다.
마지막으로 정리하자면 과거 축적 정보 ct-1에서 얼마나 잊을 지 forget gate를 지나고, current data의 정보 gt를 얼마나 넣을 지 input gate를 지나 ct-1과 합해 ct를 만들고, 최종 output을 만들기 위해 output gate를 통해 ct에서 얼마나 가져올 지 값을 도출해 ct와 곱하여 ht를 만든다.
이 LSTM을 통해 기존 초반 layer로 역전파 진행 시 반복적인 W곱으로 인해 생겼던, vanishing/exploding gradient 문제를 해결할 수 있다.
중요한 것은 cell state인데, cell state에서는 FC가 없고 단순 곱,합으로 표현된다. ct에서 ct-1로 backpropagation을 할 경우 ct는 ft와 ct-1, it의 경우 매 time step마다 달라지기에 0으로 수렴할 확률이 굉장히 낮다.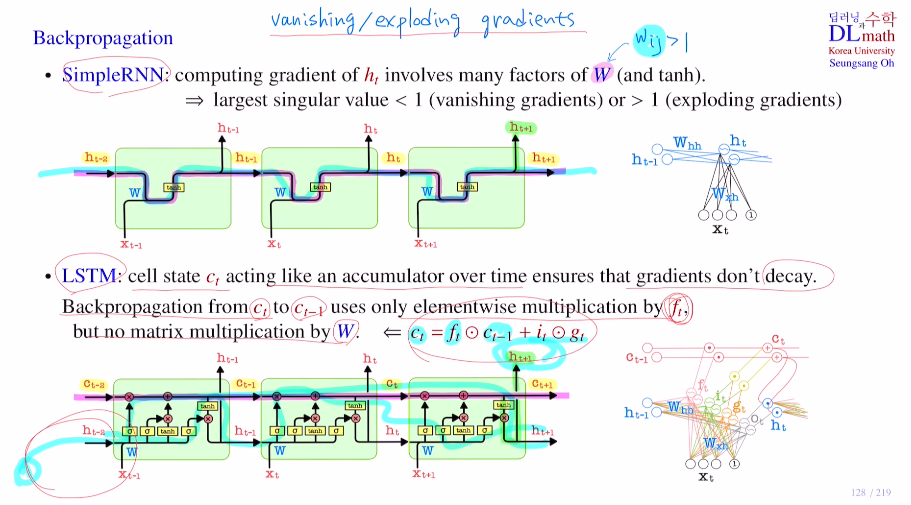
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=4iCOmNGjSWc&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=30
