저번 포스터에서 알아본 LSTM에서 단순화 시킨 GRU에 대해 알아보자!
큰 차이점은 LSTM에서는 hidden state와 cell state가 존재하는데 GRU는 hidden state만 존재한다는 점이다. 여기서는 cell state과 hidden state를 합친다.
또한 input gate와 forget gate를 합쳐 update gate를 만든다. 그리고 output gate 없이 reset gate를 사용한다. 주로 shot-term dependency와 관련한 것들은 reset gate를 이용하고, long-term dependency와 관련한 것들은 update gate를 이용한다.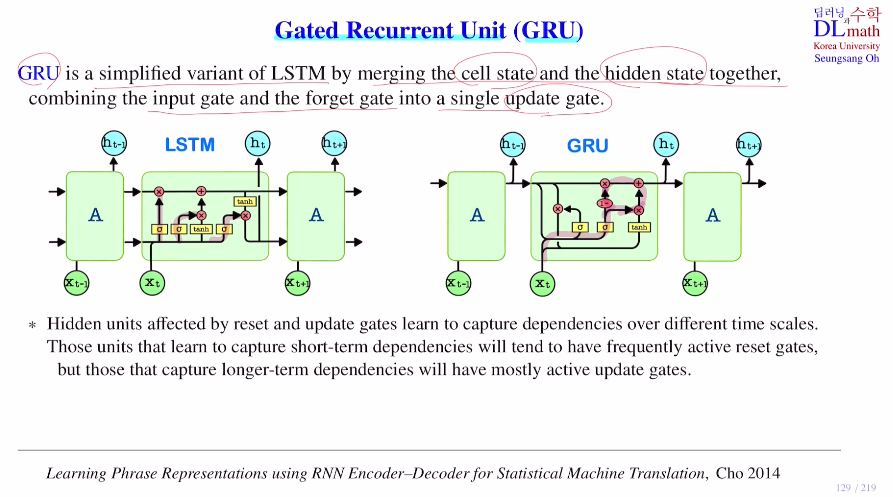
이제 LSTM과 GRU가 얼마나 다른지 확인해보자.
GRU도 마찬가지로 RNN core(Simple RNN)가 존재고, z=r=1을 대입하면 ht=ht틸다=tanh(Wx+Uh+b)로 Simple RNN이 된다. 이렇기에 RNN core에 zt와 rt가 어떻게 적용되는지 확인해보자.
(Wz=Wxh, Uz=Whh 이다.)
우선 update gate를 보면 current data와 previous hidden state ht-1를 이용하여 시그마를 거친다. 이는 나중에 ht를 만들 때 h틸다와 ht-1을 얼마나 반영시킬 지 정해준다. 그리고 reset gate를 보면 이도 마찬가지로 xt와 ht-1을 이용하는데 이는 마치 forget gate처럼 ht-1에서 필요없는 것을 없애주는 역할을 한다. 이렇게 만든 rt를 통해 xt와 함께 h틸다를 만들어 준다. 이 h틸다를 바로 사용하는 것이 아닌 ht-1과 함께 만들어놨던 update gate zt를 이용해 반영시켜 ht를 최종적으로 만들게 된다.
이렇게 변형함으로 cell state를 없애 학습해야 할 weight matrix를 네 세트에서 세 세트로 줄였다.(어느 모델이 더 성능이 좋은지는 경우에 따라 다르다.)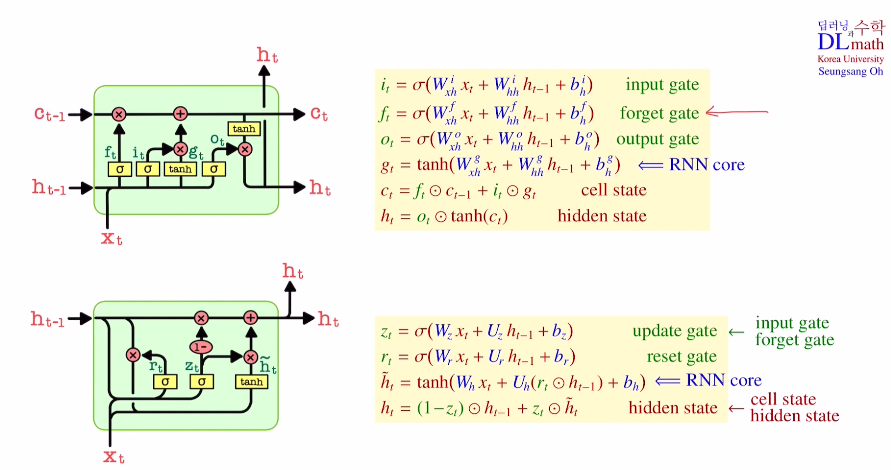
이번에는 Bidirectional LSTM을 알아보자!
주식 데이터의 경우 다음, 다다음 날의 데이터는 알 수 없기에 무조건 앞의 데이터만을 이용해야 한다. 이 경우는 Bidirectional LSTM를 사용할 수 없다.
이에 반해 기계번역의 경우 한 문장을 전체적으로 보고 번역할 수 있기에 이 경우 뒷 부분 내용도 사용하는 Bidirectional LSTM을 사용할 수 있다.
이는 어렵지 않다. forward로 가는 network하나와 backward로 가는 network 하나가 각 독립적으로 있는데, 각 독립적으로 나온 hidden state 값을 각 weight matrix를 곱하고 더하여 사용한다. 이렇게 앞의 단어들 정보와 뒤의 단어들 정보를 사용한다.
그렇다면 gradient는 어떻게 업데이트를 할까?
이는 각각 forward, backward pass를 따라 따로 yt부터 gradient를 계산해 weight update를 하면 된다.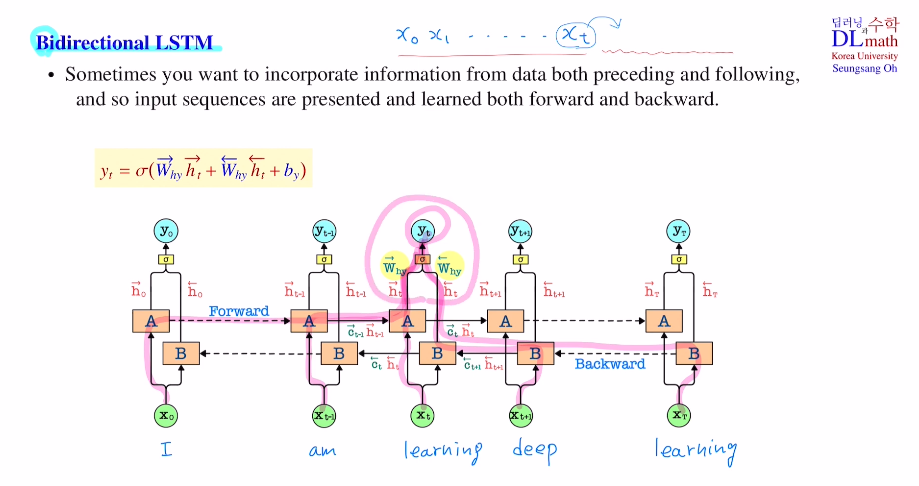
다음은 Stacked LSTM을 알아보자!
LSTM을 여러개 쌓은 것으로 input이 들어와 나온 hidden state를 다시 LSTM으로 넣는다는 점만 다르다. 아래와 같은 예시를 들어보자. 맨 아래 A라인만 가져오면 기존 LSTM이며, 보통 TBPTT를 사용하기에 x0부터 xt까지가 각 subsequence들이라고 생각하면 될 것 같다.
이 Stacked LSTM 모델은 A에서 yt로 가는 방향은 굉장히 다양하다. 그렇기에 gradient를 계산할 때도 양도 상당히 많고 복잡하다. 따라서 보통은 2~3개만 stack한다.
기존 RNN의 input shape는 (batch size(몇 개 subsequence), timestep(하나 subsequence 당 몇 개 데이터 사용), input dim)이고 output shape는 (batch size, output dim)이다.
하지만 이 모델은 A에서 나온 output을 input으로 사용해야 하기에, output shape은 (batch size, timestep, output dim)이다. 이를 코드로 나타내면
return_sequences = True 로 설정해야 한다.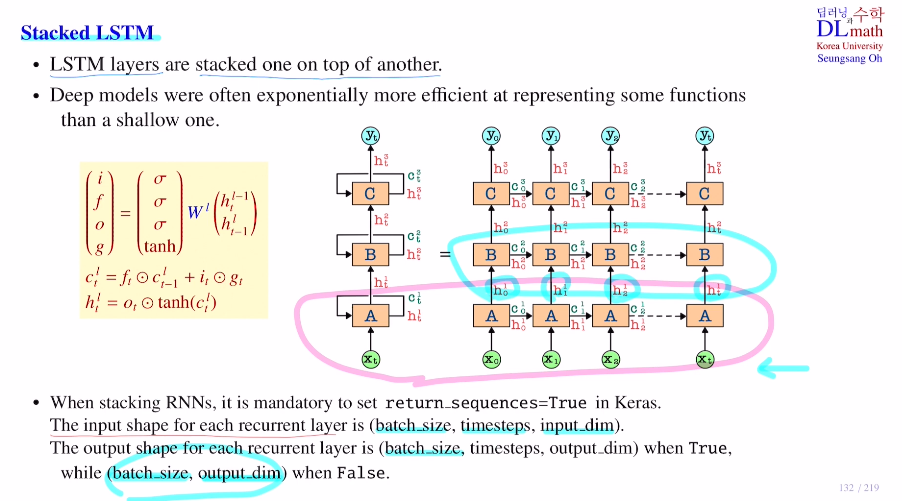
마지막으로 LSTM 안에서 Dropout을 적용하는 방법을 알아보자.
대표적인 방법 6가지를 알아보자.
1) RNN regularization dropout
timestep 당 동일한 dropout을 적용할지, 다른 것을 적용할지 정해야 한다.
다르게 적용하는 것을 per-step mask라고 한다.
모든 timestep에 동일한 dropout을 적용하는 것을 per-seuquence mask라고 한다.
두 cell 사이를 연결하는 connection을 recurrent connection이라고 한다. 반대는 non-recurrent connection이라고 한다.
우선 recurrent connection인 cell state에 dropout을 적용했다고 하자. cell state는 FC가 아니기에 per state mask로 지우면 아래와 같이 나온다. 하지만 이렇게 되면 하나를 지우면 이전의 정보가 모두 사라지기에 문제가 발생한다. 따라서 각 timestep마다 무작위로 지우면 long-term memory를 유지하기 어려워진다. 따라서 기본적으로 recurrent connection에는 per-step mask를 적용하지 않는다.
하지만 non recurrent connection에서는 상관없다. 그 대표적인 것은 RNN regularization dropout이다. input xt가 들어가는 것은 각각 독립적인 데이터가 들어가기에 상관이 없다. 이런 경우 per-step mask가 가능하다. dropout 비율이 p라고 하면 베르누이 분포를 따라 1-p확률로 1을 만들거나 p확률로 0을 만들어 이를 곱해 무작위로 지우게 된다.(ht(l-1)로 되어 있는 이유는 논문에서 stacked LSTM에 적용했기 때문이다.)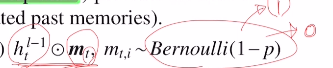
2) RNNdrop은 cell state에 dropout을 적용하는 것으로 위와 달리 t가 없다. 즉, timestep이 없다는 것이다. 그렇기에 per-sequence mask가 된다. hidden state or cell state에 이를 사용하면 지워지지 않은 노드는 다음에도 지워지지 않기에 long-term memory를 할 수 있게 되는 것이다. 같은 말로 지워진 노드는 계속 지워지기에 하나의 feature가 없어진 것이다. 이를 통해 co-adaption을 줄일 수 있다.
3) Variational RNN dropout도 동일한 dropout을 적용한다. 이는 xt, ht-1에 적용할 수 있다.
4) Weight-dropped LSTM: hidden에서 hidden으로 가는 Whh에 적용하는 것으로 노드에 적용하는 것이 아니다. 0or1로 구성된 matrix를 element-wise곱으로 곱한다. 이 방법은 node를 지우는 것이 아니기에 feature가 아예 없어지는 것이 아니다. 연결을 약하게 할 뿐.(FC로 예를 들면 node를 지우는 것이 아니라 connection을 지우는 것. 노드는 살아있다.)
5) Recurrent dropout : mt or m 두 방법 다 사용 가능하다.
current input xt를 cell state에 얼마나 집어 넣을지 정하고 넣기 직전 dropout을 적용한다.
그렇다면 1과 5는 무엇이 다를까? 1은 input data안에서 특정 entry값을 가리는 것이라면, 5는 이미 FC layer를 지났기에 적절하게 찾은 feature에 대해 dropout을 한 것이다. layer를 거칠 수록 feature각각이 더 정교해지기에 input node에 dropout보다는 5가 더 효율적이기는 하다.
6) Zoneout: 이 부분은 cell 전체를 건너 뛸지 말지를 정하는 것으로 당연히 per-step mask이다. 아래와 같이 mt가 0이면 업데이트를 진행하는 것이고, 1이면 xt와 ht-1을 무시하고 그냥 ct-1 그대로 넘기는 것이다. 중요한 점은 모든 데이터가 cell 전체를 뛰어 넘는 것이 아니라 cell state이 노드에 해당하는 feature에서 각각 따로 적용되는 것이다. 이 방법은 hidden state에서도 적용되는데 ht를 만들 때 xt와 ht-1을 무시하고 ht 그대로 보내는 것이다.
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=3w8eCWRPmTA&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=31
