이번 포스터부터는 Attention에 대해 알아보자!
이번 포스터는 이미지에 Attention을 적용한 Visual Attention을 알아보자.
Image Captioning은 input으로 어떤 이미지가 들어오면 이 이미지에서 중요한 context를 찾아내어 문장으로 표현한 captioning을 하는 것이다. 여기서 CNN은 image에서 특징을 추출하는 것이고, LSTM은 text(Captioning)를 만들어 내는 것이다. 이렇게 전반부 인코더와 후반부 디코더로 구분된다.
사실 정교한 image classify하는 것도 꽤 어려운 일인데, 여기에 captioning까지 하는 것은 더 복잡하고 아주 많은 데이터가 필요하다. 이에 더해 captioning이 되어 있는 이미지 데이터도 구하기 어렵다. 그렇기에 이미 per-training된 CNN 모델을 가져와 사용한다. 보통 VGG-16 or Resnet을 사용한다. : use pertrianed CNN
이를 통해 큰 사이즈의 image를 아래와 같이 4096 dim(small feature vector x)으로 줄이고 final FC classification layer를 없앤 후 LSTM으로 보내 text를 만들어 내는 것이다!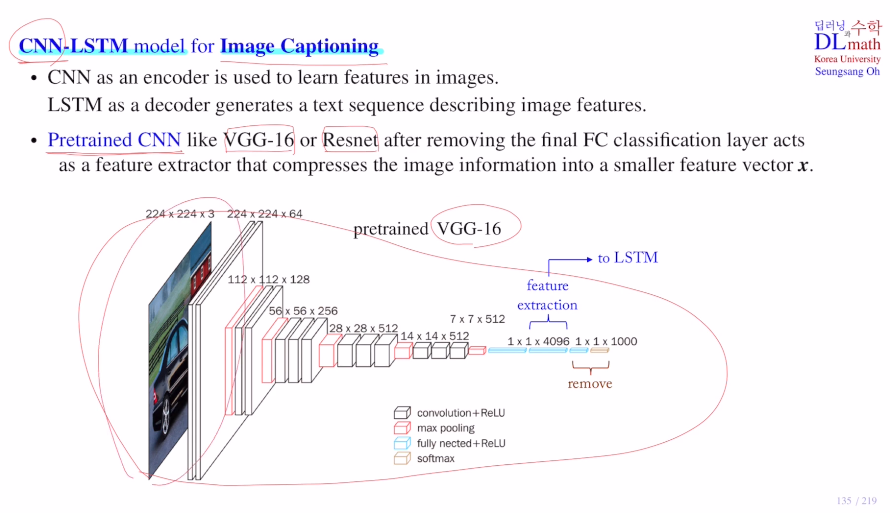
이제 이렇게 pre-trained CNN으로 image information을 압축한 인코딩 결과 feature vector 데이터를 LSTM에서 어떻게 다루는지 알아보자.
두 가지 방법이 있는데, feature vecot를 첫 번째 LSTM cell에만 넣는 방법과 모든 LSTM cell에 넣는 방법이 있다.
첫 번째 방법은 image가 너무 커서 feature vector의 크기가 클 때, hidden state도 어느 정도 크게 해야 하기에 부담이 크다. 만약 작게 한다면 cell을 지날 수록 정보 손실이 많이 일어난다. 따라서 적절한 text를 만들 수 없다.
그렇다면 두 번째 방법은 어떨까? 매번 hidden state이외의 feature vector를 참고할 수 있기에 hidden dim size가 작아도 수월하게 text를 만들 수 있는 것이다. 그렇기에 image가 큰 경우는 두 번째가 적합하다.
이제 caption을 하는 과정을 알아보자
start라는 token을 생성하는데 이는 caption을 시작한다는 의미이다.
첫 번째의 경우 start를 생성하고 previous hidden state를 보내고 input은 생성했던 start를 받아 'A'를 만든다. 이렇게 hidden state를 통해 feature vector에 대한 정보가 이어지고 기존에 생성했던 token을 받아 새롭게 생성하는 것이다.
두 번째는 feature vector를 input으로 항상 넣기에 기존에 생성했던 token은 넣지 않는다. 이렇게 start token1 token2 ... end 로 생성하게 된다.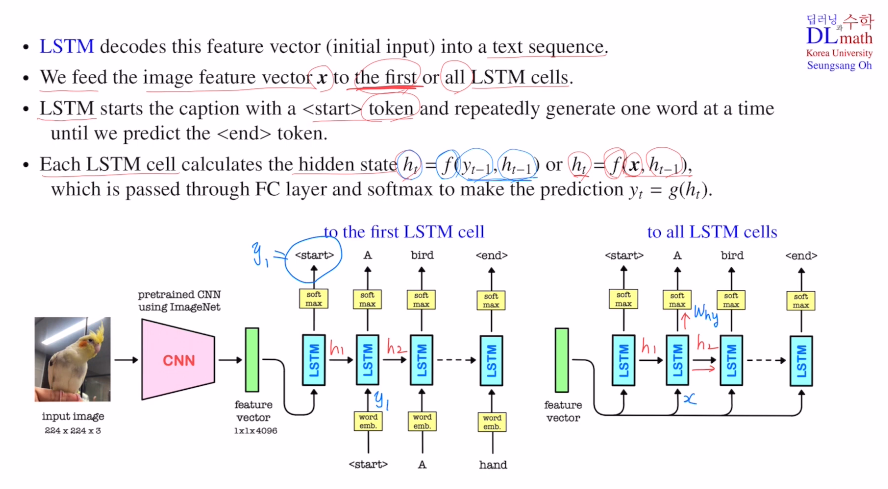
만약 image가 너무도 커서 feature vector의 사이즈도 너무 크다면?!
첫 번째는 hidden size를 늘리면 부담이되고, 줄이면 정보 손실이 일어난다.
두 번째는 이렇게 큰 feature vector를 계속해서 input으로 넣기에 input size가 굉장히 큰 LSTM cell을 학습시켜야 한다.
=> 이러한 문제를 해결하기 위해 Attention mechanism을 사용한다!
이미지를 구분할 때는 전체를 보는 것 보다는 일정 부분을 집중해서 보고 구분하게 된다. 그렇기에 Attention이라고 부른다.
(Show, Attention and Tell)
예를 들어 아래의 사진 중 A woman is throwing a 라고 생성했다면 다음 text를 generate하기 위해 어디를 보아야 할까? 자연스럽게 여자의 손에 있는 주변을 집중하게 될 것이다. 이렇게 함으로 전체 그림을 보는 것 보다 훨씬 효율적으로 예측할 수 있는 것이다.
이미지를 grid로 나누어 어느 부분을 집중해야 하는 지 찾는 방법을 실행한다.
VGG-16모델을 통해 image feature vector를 찾고 LSTM으로 넣는다.
이를 통해 next hidden state ht = f(x, ht-1)를 만든다.
이제 attention을 써서 만들어야 하기에 수식은 ht = f(attention(x, ht-1), ht-1)이 된다.(x대신 attention 모듈로 대체된다. : attention할 x는 위에서 말했 듯 이미지를 조각별로 잘라 image feature별로 적용한다.)
이렇게 집중하고자 하면 이미지의 spartial information 공간 정보를 알고 있어야 한다. 하지만 압축된 feature vector는 공간 정보가 사라져 있다. 따라서 이 x를 직접 attention모듈로 사용할 수 없다.
=> 그렇다면 어떻게?
x까지 오지 않고 CNN을 거쳐 오던 중간까지를 잘라 이 feature map을 이용하는 것이다!
이 feature map을 잘라 x = {x1,x2,..}로 만들고 이를 약간 변형시켜 zt를 만든다. 그 후 이 zt를 이용하여 LSTM에 input feature로 넣는다.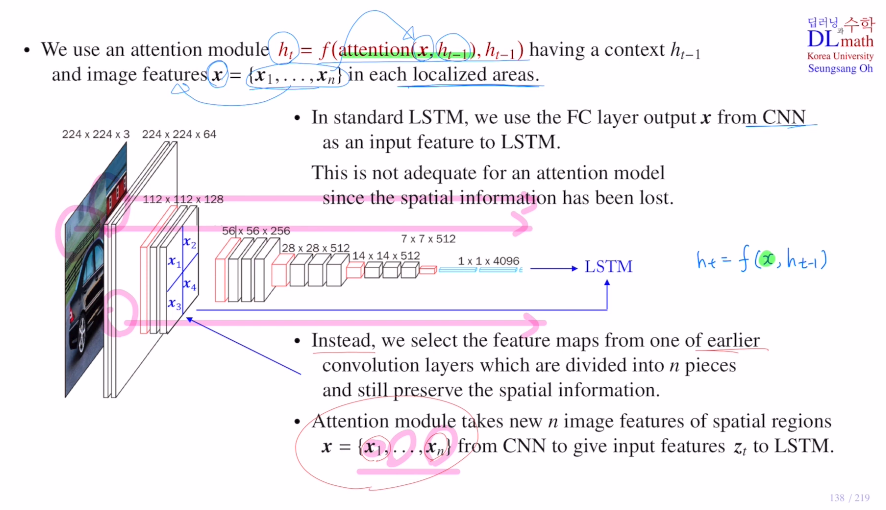
이제는 x를 매번 input을 넣는 것이 아닌 zi를 넣게 된다.
이 zi는 CNN을 통한 feature map을 잘라 만든 x={x1,x2,..} 를 attention을 취하여 만든 것으로 이 각 z1,z2,z3,...들이 매 LSTM input으로 각각 들어가는 것이다!
localized area에 대한 feature vector xi들을 이용하기에 dim을 작게 해도 문제가 없다.
1) soft attention (0~1 : 이미 확정된 값이기에 deterministic)
zt를 만들 때 매 time step마다 xi들의 조합에 weight를 다르게(어느 local에 집중할 지) 주어 각기 다른 값을 생성한다. 이렇게 zt를 잘 만들어야 좋은 text를 만들 수 있다.
zt를 만들 때 이렇게 fatt(x, ht-1)로 이전 hidden state를 참고하여 x에서 어느 부분에 weight를 더 줄지 weight값을 만드는데 이 값을 ati라고 한다.
이 방법은 MLP를 사용하여 tanh(Wht-1 + W'xi)로 ati를 만든다.
이 ati(가중치 값)에 softmax를 취해 합이 1로 만들고, 이 attention weight를 통해 각 image feature xi와 곱해 zt를 생성하는 것이다. (zt dim은 xi dim과 같다.)
또한 두 함수는 미분가능하기에 역전파가 가능하다.
2) hard attention (0 or 1 : stochastic sampling)
xi를 버릴 지 가져갈 지 정하는 것이다.
soft의 경우 0~1 값을 갖는 attention weight를 잘 구했다면, hard에서는 이 attention weight를 확률로 한다.
예를 들어 soft에서 weight 값이 0.2라면 0.2를 곱해주는 것이지만 hard에서는 0.2라면 0.2의 확률로 살아있는 것이다.(10번 중 2번 정도만 살아있게 된다.)
상당히 많은 sampling을 하면 weight를 0.2곱한 것과 같게 되는데 이를 Monte Carlo method라고 한다.
이는 확률의 개념이 들어가기에 미분이 불가하다. 역전파 사용 불가하다. 따라서 이 경우는 강화학습의 방법을 사용한다.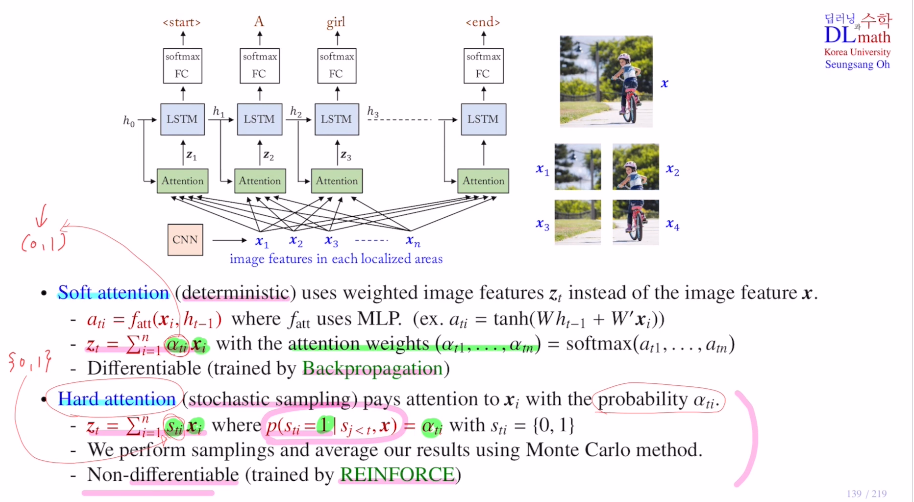
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=9RHb9B4cJso&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=32
