지난 포스터에서는 이미지를 다루는 Visual Attention을 알아보았다면, 이번에는 기계번역을 위한 Attention LSTM을 알아보자!
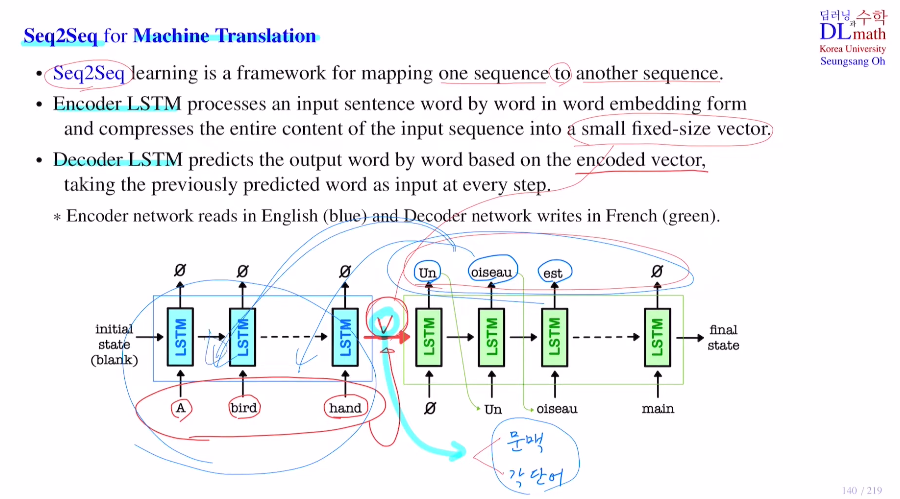
우선 Seq2Seq를 알아보자.
하나의 Seq에서 또 다른 Seq로 보내는 framework이다.
하나의 문장을 이해(인코더 LSTM) -> 이를 통해 새로운 문장 생성(디코더 LSTM)
우선 Encoder LSTM에서는 word by word로 하나씩 받아 들인다.
이 각 word는 vector로 임베딩 시켜 이 vector를 받는다. 이것을 hidden state를 통해 Decoder로 보낸다. 보낼 때는 small fixed-size vector V로 압축하여 보낸다.
이 작은 size 벡터를 통해 디코더에서 단어를 하나씩 word by word로 생성하는 것이다. 디코더에서는 small fixed-size vector가 hidden state를 따라 오기도 하지만 직전에 생성된 단어도 input으로 받게 된다.
V는 앞의 전체 문장을 압축한 vector인데 사이즈를 너무 키우면 뒤의 디코더 부분에서 hidden state dim이 큰 상태로 있어야 하기에 부담이고 너무 작으면 모든 정보를 하나에 넣기가 어렵다.
=> 이러한 문제를 해결하기 위해 Attention mechanism을 사용한다!
기존 Seq2Seq의 bottleneck은 전체 input을 작은 vector로 압축해야 한다는 점이다. 따라서 꽤 많은 정보가 손실된다.
Attention은 디코더가 새로운 것을 생성할 때 인코더의 hidden state를 참고할 수 있게 해준다. 인코더의 각 hidden state들에 weighted average를 취하여 사용한다. 이 weight를 주는 방법이 쿼리, 키, 벨류를 사용하여 정하게 된다.
현재 time step의 privious hidden state와 previous output을 이용하여 current output을 예측할 때, ht-1을 통해 다음 생성할 단어가 목적어이면 input문장의 목적어 부분을 집중해서 보게 된다. 그렇기에 디코더의 hidden state ht-1이 중요하며, 이를 기준으로 앞의 input 문장의 어느 부분을 집중할지 기준을 잡는 것이다. 이 디코더의 각 hidden state이 쿼리이다.
value vector는 쿼리에 의해 집중해야 할 단어들이 있으면 이 각각을 value vector라고 한다.
(단어라고 말하지만 집중해야 할 인코더의 hidden state이 더 정확하다.)
key는 어느 단어를 주시해서 봐야 할지 weight를 계산하기 위해 사용되는 vetor들이다. 이 경우에는 encoder의 hidden state를 보며 계산한다.
지금은 키, 벨류 모두 encoder의 hidden state를 이용하는데 더 복잡한 모델로 가면 세 가지가 정확히 구분된다.
query st-1 : 디코더의 previous hidden state로 ht-1을 가지고 input 문장에서 어느 부분에 집중해야 할지를 요청하는 vector
key hi : query의 요청에 의해 encoder hidden state에 곱할 weight를 계산하기 위해 사용되는 vector
value hj : weight가 계산되었다면 이 weight를 가지고 average를 구하게 되는데 이 단어와 관련된 hidden state의 weight average를 구한다.디코더의 쿼리를 이용해 인코더의 hidden state에 각각 적용해서 weight를 계산
이 weight로 hidden state를 기준으로 weighted average를 취하고 이를 디코더의 새로운 input으로 집어넣어 최종 output을 도출하게 된다.
이렇게 encoding vector 뿐 아니라 앞의 문장을 다시 참고하면서 디코더가 새로운 단어를 생성하며 더욱 효율을 높였다. 또한 기존 DNN은 weight 값이 무엇을 의미하는지 알지 못하는 블랙박스였지만, attention은 weight값들이 어떤 단어에 집중하는지에 대한 값이기에 이를 출력하며 정보 확인이 가능하다. 이를 unveiling DNN black box라고 한다.(블랙박스인데 약간의 정보는 알 수 있다.)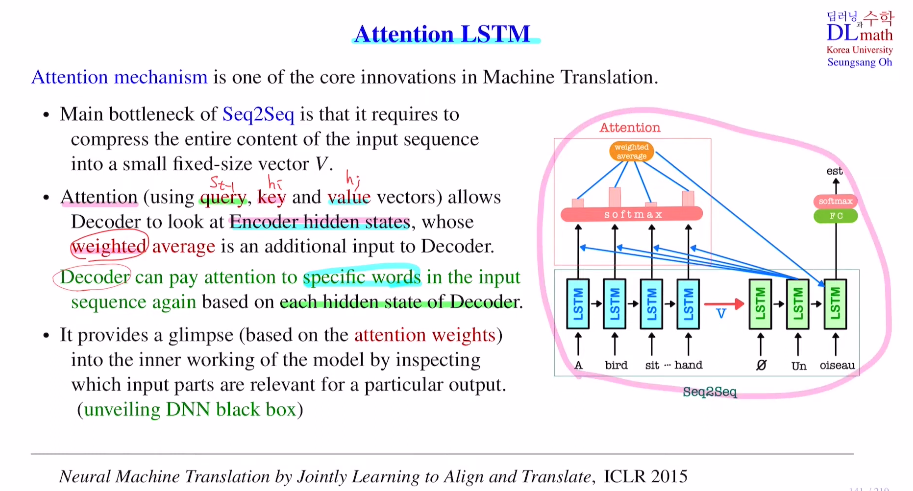
구조를 자세히 살펴보자.
어텐션은 다양한 방법이 있지만, 지금은 dot product attention에 대해 알아보자.
디코더의 previous hidden state인 query st-1과
인코더의 hidden state인 key hi와
동일하게 인코더의 hidden state인 value hj가 있다.
Transformer는 이 세개가 따로 구분된다.
이전 visual attention에서는 DNN fatt을 통해 가중치 ati = softmax(fatt(xi, ht-1))이었다.
이 visual attention은 쿼리가 ht-1, key가 localized area에서 xi이었다.
여기서는 쿼리가 st-1, key가 인코더의 hidden state인 hi이다.
attention weight : ati = softmax(st-1, hi)를 구하고
attention value : at = sigma(atj hj) 로 구한다.(weight average)
기존 standard LSTM에서는 st = f(st-1, yt-1) 로 구했지만, Attention LSTM은 attention value at를 이용하여 st = f(st-1at, yt-1)로 구한다. 이를 통해 current hidden state st를 더욱 정확하게 구할 수 있는 것이다.
1) 쿼리인 디코더 previous hidden state st-1(3x1이라 가정)을 인코더로 가지고 온다.
2) 이를 각각의 인코더 hidden state들인 키들(각 3x1)과 곱한 후 softmax를 취한다.
3) 이렇게 나온 attention weight를 벨류인 인코더 hidden state들과 weight sum을 통해 weight average인 attention value(3x1)를 구한다.
4) 이 attention value를 디코더의 st-1과 concat하여(6x1) 이것을 직전에 생성한 단어 yt-1과 함께 LSTM에 들어가게 되는 것이다.
5) 이렇게 나온 st로 최종 단어를 생성하게 된다.
(참고로 인코더의 LSTM과 디코더의 LSTM은 다른 구조를 가진다. 또한 지금은 dot product이기에 파라미터가 non-learnable이지만 성능을 높이기 위해 weight matrix를 추가한다면 학습해야 한다.)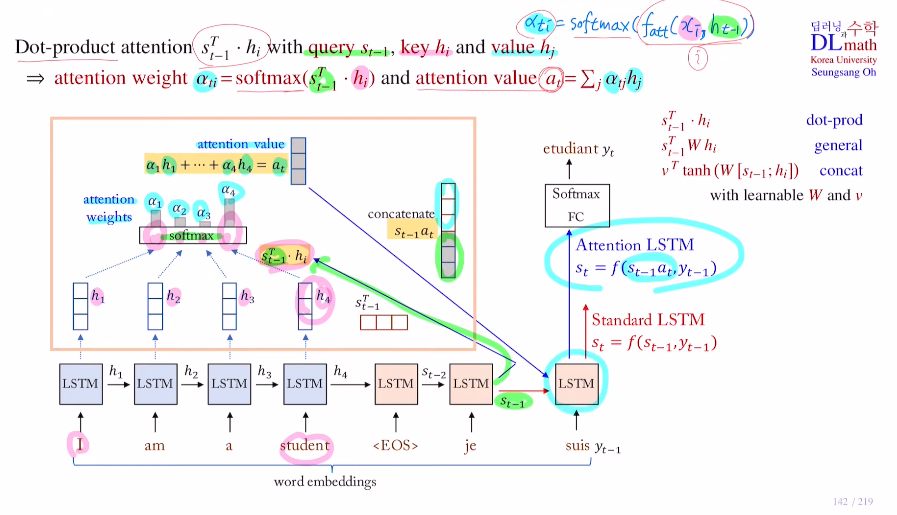
마지막으로 정리해보자
Seq2Seq은 하나의 hidden state로 함축해야 했기에 어려움을 겪었다. 이를 attention을 통해 참고할 수 있었고 이를 시각화도 가능하게 되었다.
attention LSTM의 단점은 아주 긴 문장이 들어오면 계속해서 하나씩 받아야 하기에 parallel computing이 불가하다. 따라서 training time이 증가한다. 또한 long-term dependency가 떨어지게 된다.
이를 개선하기 위해 만든 것이 Transformer이다.
인코더에서는 문장을 받고, 디코더에서 문장을 생성하는데 여기서는 self attention만을 통해 LSTM과 달리 word by word로 받아들이지 않고 한 번에 문장 전체를 받아들여 parallel computing을 하고 global dependency를 실행할 수 있게 된다!
transformer의 인코더를 이용한 구글에서 만든 BERT도 있다.
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=0aMn-XQ6xw&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=33_
