이전 포스터에서는 AE에 대해 배웠다면, 이번에는 이 AE를 이용한 다양한 모델들을 알아보자!
우선 Tied weight Auto-Encoder이다.
가운데 hidden layer가 latent vector가 된다.
non-linearity를 고려하지 않는다고 가정하면 ipnut x에 대해 weigh matrix W로 Wx를 통해 dim=100짜리 latent vector를 만들고, 만약 이 W의 역행렬이 존재한다면 이를 통해 복원시킬 수도 있는 것이다. 문제는 W가 정방행렬이 아니기 때문에 역행렬이 존재하지 않는다.
우선 알 수 있는 것은 복원시킬 때 사용할 matrix는 인코더의 W의 dim과 transpose된 것일 것이다. 인코더의 W1가 100x1000라면 디코더의 Weight matrix W2는 1000x100일 것이다.
이 W2를 W1의 transpose로 같은 값을 갖게 하는 것이 Tied weight AE가 된다.
W2 = W1^T 이기에 mirror image구조를 갖고 있다.
엄밀히 말하면 W2는 W1의 inverse matrix역할을 해야 한다. 그렇기에 단순히 W1을 transpose시킨다고 해서 inverse의 역할을 하는 것이 아니다. 이렇게 하는 이유는 최소한 학습해야할 파라미터의 개수가 절반으로 줄어들기에 학습속도를 빠르게 하고 오버피팅을 줄일 수 있기 때문이다.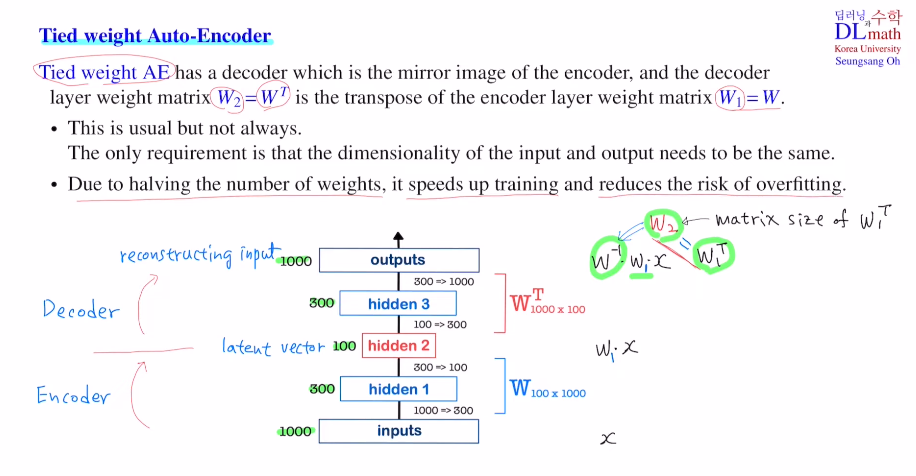
두 번째는 Denoising Auto-Encoder이다.
말 그대로 noise가 있는 데이터를 AE를 통해 clean data로 복원하는 것이다.
target은 무엇으로 잡을까? 노이즈가 있는 input을 사용하면 안 된다. 우리의 목적이 clean data복원이기에 target은 깨끗한 데이터를 사용해야 할 것이다.
Training을 할 때는 clean data에 노이즈를 주어 input으로 넣게 되는데 random Gaussian noise를 사용한다. 이렇게 noisy input을 넣고 나온 output을 clean data와 비교하는 것이다. 이를 반복하며 noise가 없는 clean data를 생성하게 된다.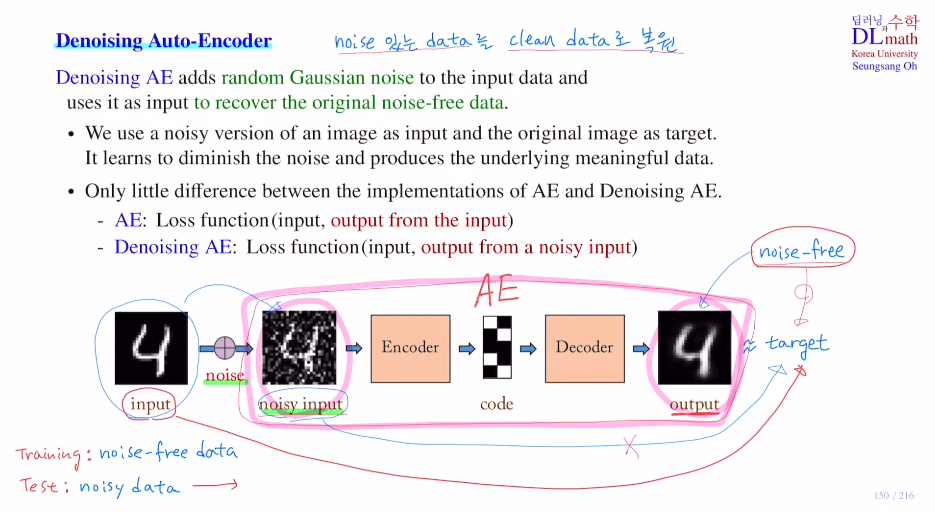
세 번째는 Stacked Auto-Encoder이다.
이는 AE안의 layer숫자를 키우는 방법으로 Deep AE라고도 부른다.
아래의 맨 오른쪽 그림을 보면 만약 Tied weight AE를 사용한다고 가정하면 W1,W2와 W1^T,W2^T로 weight matrix가 구성될 것이다.
layer가 깊어질 수록 weight matrix가 점점 증가하며 파라미터가 증가하게 된다.
또한 1000->100->1000으로 갈 때 100에는 너무나 많은 정보가 함축되어 있기에 다시 복원하기에는 꽤 어렵다.
=> 따라서 이 단계를 차례대로 천천히 진행시키는 것이 Stacked AE이다.
아래의 그림을 보면 맨 오른쪽과 같이 한 번에 진행시키는 것이 아닌, 1st AE, 2nd AE를 거쳐 output을 만드는 것이다. 1st를 보면 1000->300->1000으로 W1만 학습하면 되고, dim이 많이 줄어들지 않았기에 학습하기 용이하다. 이 dim 300짜리 latent vector는 2nd AE의 input으로 들어간다. 즉, 2nd AE에서는 이 latent vector를 복원하는 것이다. 그러면 W2만 학습하면 되고 300->100->300으로 부담도 없다. 이렇게 각각 weight matrix를 학습한다.
이렇게 한 후 만들어진 weight matrix 1, 2를 그대로 가져와 하나로 합쳐 사용하는 것이다. 이렇게 각 layer가 하나만 있는 AE를 통해 따로 weight matrix를 학습하고 만들어 내어 이를 최종적으로 합쳐 사용하는 것이 Stacked AE이다.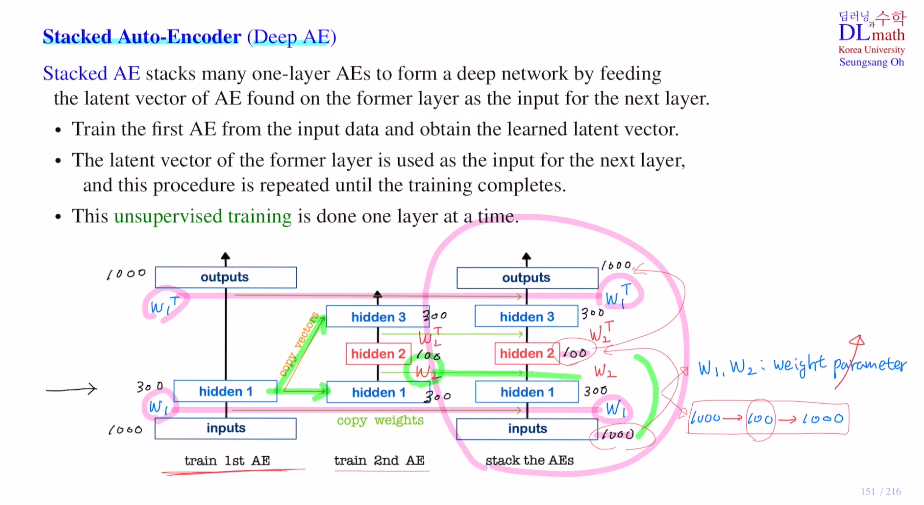
이번에는 이 Stacked AE를 이용하여 classification task에 적용해보자.
AE는 비지도학습인데, classification은 지도학습이므로 둘을 합쳐서 사용한다.
우선 AE를 비지도학습으로 학습한다. 여기서 디코더 파트는 버리고 인코더 파트만 가져온다.(weight 값들도 똑같이, latent vector인 hidden 2까지)
이후 FC layer를 붙인다. 이렇게 되면 새로운 W3, W4 등의 weight matrix들이 생길텐데, 이것을 fine-tuning을 통해 학습한다.
여기서 중요한 점은 가져온 인코더 부분은 frozen을 통해 얼린다.
즉, upper network만 weight update를 하는 것이다. 이는 지도학습으로 진행된다.
Q. 여기서 궁금증이 생기는데 왜 한번에 W3,4를 같이 학습시키지 않았을까?
input의 dim=1000으로 상당히 큰데, 이렇게 큰 dim을 통해 W1,2,3,4까지 모두 학습해야 하기에 꽤 어려운 학습이 진행된다. 만약 인코더를 가져와 froze시키고 학습하면? input자체가 100으로 줄어들고 weight matrix도 3,4두개만 학습하면 되기에 훨씬 가볍게 학습할 수 있다!
W1,2는 classification에 관계가 전혀 없는 weight이다. 하지만 학습 완료 후 latent vector바로 몇 개 전 matrix만 froze를 풀어주고 fine-tuning을 하면 classification에 더욱 알맞은 모델이 될 수도 있다.
추가적으로 언급할 점은 처음 학습할 때 W1,2를 froze시키지 않고 바로 W3,4와 다같이 학습하면 이전에 Stacked AE로 학습하여 만들어진 W1,2의 값들이 확 망가진다. W3,4는 초기화 되어 있는 값들이기에 W1,2를 풀어줘버리면 W3,4에 맞추며 확 망가지기 때문이다.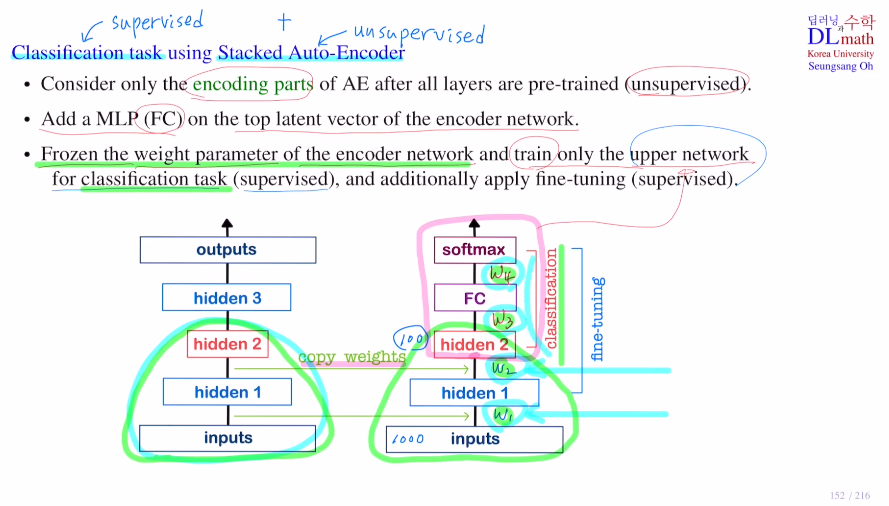
마지막으로 AE를 사용하여 Semi-supervised learning과 Anomaly detection을 나타내는 모델을 알아보자.
1) Semi-supervised learning using Stacked AE
이름과 같이 지도학습과 비지도 학습이 합쳐져 있는 것을 말한다. 많은 unlabeled data를 비지도학습으로 다루고 일부 labeled data를 지도학습을 통해 두 가지 방법을 사용하는 것이다.
100만장의 image data가 있을 때, 데이터가 너무 많아 1만장만 label을 만들었다고 하자. 이러한 경우 둘 다 사용하고 싶기에 이 Semi-supervised learning을 사용하는 것이다.
앞에서 말한 것과 같이 Stacked AE를 통해 비지도학습으로 학습하고, 인코더만 가져와 task에 맞는 network를 그 위에 얹고 지도학습을 추가적으로 진행하는 것이다.
2) Anomaly detection using Stacked AE
기존 dataset에서 outlier를 찾아내는 것이다.
예를 들어 고양이 사진이 100만장 있을 때, 강아지 사진 10개가 있다면 이를 찾아내는 것이다.
특이한 것을 찾아내는 것이기에 따로 label data를 사용하지 않는다.
AE를 통해 비지도 학습으로 Anomaly detection을 하고 싶다.
우선 AE는 output과 target사이에 오차를 줄이는 방향으로 다가간다. 학습이 충분히 되었다면 test시 고양이 사진을 넣어도 output으로 잘 만들어 낼 것이다.
하지만 강아지를 넣는다면? target과 output사이의 오차가 크게 나올 것이다.
이 error를 reconstruction error라고 하는데 이 error가 임계값을 넘는다면 이를 특이한 데이터(outlier)로 고르며 Anomaly detection을 수행하는 것이다!
(기존의 해커 공격, 시스템 모니터링, 스마트기기에서 음성 인식, 비행기가 날아갈 때 비정상적 라인으로 갈 때 등에 사용)
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=7PuZGRCIFnU&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=35
