GAN의 장점과 단점에 대해 살펴보자!
장점
GAN의 장점은 비지도학습이라는 점과 GAN이 만들어 내는 이미지가 high quality image라는 것이다. 우리가 알아보았던 GAN, AE, VAE 들은 대표적인 비지도 학습이었다.
또한 GAN은 대표적인 generaive model이다. 물론 VAE도 generaive model이지만 노이즈를 복원하는 것이기에 이미지가 흐린 경우가 종종 있다. 하지만 GAN은 판별자가 쉽게 fake라고 하기에 이를 극복하려고 생성자가 성능을 올려서 훨씬 좋은 이미지를 뽑아 낸다.
GAN은 역전파를 그대로 사용할 수 있다. 동시에 학습은 불가하지만 VAE와 같이 reparametarizatoin trick같이 따로 작업 없이 역전파가 가능하다.
단점
GAN의 단점은 non-convergence로 two player minimax problem으로 global optimum을 내쉬균형으로 찾게 된다. 하지만 이 내쉬균형은 항상 존재하는 것이 아니다. 따라서 이 convergence가 보장되어 있지 않다는 것이다.
두 번째는 Diminished gradient로 학습하는 과정에서 gradient가 0에 가깝게 가는 경우가 빈번하게 있다. 이로 인해 학습속도가 느려 학습하는데 어려움이 있다.
세 번째는 Mode collapse이다. GAN을 통해 data를 만들 때 data의 퀄리티가 좋아야 하며 다양한 이미지를 만들어야 한다. 하지만 GAN은 이 Mode collapse로 인해 다양한 그림을 만들지 못 할때가 많다.
추가적으로 언급할 내용은 GNA은 fake data를 생성하지만 이 분포를 알려주지는 않는다. 또한 하이퍼파라미터를 선택할 때 굉장히 민감하다.(판별자가 보통 생성자보다 빠르게 학습되어 버리기에 둘을 잘 조절해야 한다. 이 k step을 잘 설정해야 한다.) 중간중간에 manually babysit 처럼 학습 초기에 하이퍼파라미터를 잘 조절해주어야 한다는 것이다. 또한 elvaluation metric도 없다. G의 성능이 좋은지 안 좋은 지 어떻게 평가할 수 있을까? 그에 대한 기준이 없다. 그리고 어느정도까지 해야 학습을 멈출지에 대해서도 정해져있지 않는다.
: real data와 유사한지에 대한 image quality와 다양한 종류의 이미지를 만들 수 있는지에 대한 diversity를 고민해야 한다.
(inception score나 inception distance가 있긴 하다. 하지만 우리에게 익숙한 acc같은 metric은 따로 없다.)
이제는 GAN을 학습하는데 어려운 점 세 가지를 알아보자.
: Difficulty in Training GAN
1) Non-convergence
in two player minimax problem에서 수렴을 보장하기에는 어렵다.
학습을 진행할 때는 G or D를 고정시킨 후 학습을 진행한다.
만약 유니크 내쉬 균형이 있어 도달하면 최적이지만, 서로 update하는 과정에서 서로가 서로의 성능을 낮출 수 있기에 도달하지 않을 수도 있다. 아래 그림과 같이 saddle이 있을 때 x방향으로는 minimize, y방향으로는 maximize시키고 싶은 것이다. 여기서 만약 x방향으로 update할 때 한 point에서 minimize를 위해 움직였을 때 완전 minimum보다 조금 더 갔다고 해보자. 그 이후 y방향을 maximize하는 쪽으로 update할 텐데 여기서도 조금 더 넘어갔다고 해보자. 이렇게 x방향 y방향을 반복하며 optimal에 수렴하지 않을 수 있다는 것이다. oscillate (not to converge) 이것이 GAN을 학습하는 데 가장 어려운 점이다.
2) Diminished gradient
D가 너무 강력하다면 G는 제대로 학습을 진행할 수 없을 것이다.
왜냐하면 D(G(z))가 거의 0으로 가기 때문에 기울기가 대부분 0에 가깝기 때문이다.
이번에는 D의 성능이 안 좋다면, G는 너무 쉽게 속여 문제가 된다.
이 두 경우는 아무 피드백을 받을 수 없게 되어 둘 다 개선이 되지 않는다.
3) Mode collapse
이것은 GAN의 non-convergence problem에서 가장 중요한 문제인데, real data의 분포는 대부분 multimodal(최빈값이 많은 경우)이다. G가 골고루 집중해서 만들어야 하는데, G가 특정한 부분의 이미지만 만들어내면 다양성이 떨어지게 된다. 맨 아래 첫 번째 그림은 8개 분포로 잘 만들지만 두 번째 그림은 한 쪽에만 몰려 그 부분의 이미지만 생성하는 것이다.
G가 MNIST에서 7을 잘 만들어 D를 속인다면 G는 7만 계속해서 만들어 버리는 것이다. 이렇게 local optimal에 빠져 한 두가지만 집중적으로 만들고 다양하게 만들지 못하는 경우가 생긴다.
GAN이후 수 많은 GAN이 나왔는데 몇 가지를 알아보자.
Deep Convolutional GAN (DCGAN)
이는 GAN에 CNN을 접목시킨 것으로, vector arithmetic properies가 있다. 어떤 샘플을 생성할 때 특정 의미를 주어 특정 이미지를 생성할 수 있게 된다.
DCGAN의 구조를 살펴보면, 마찬가지로 G와 D로 구분되어 있다.
우선 G는 latent vector를 받아 fractionally-strided(or transposed) convolutions를 통해 64x64x3 image를 만드는 up sampling을 한다.
D는 이미지를 가지고 down sampling을 통해 real인지 fake인지 구분하게 된다. 여기서는 따로 FC를 사용하지 않는다. 또한 Max pooling없이 stride를 크게 주어 down sampling을 진행한다. batch norm을 사용하고 G는 Relu, D는 Leaky Relu를 사용한다.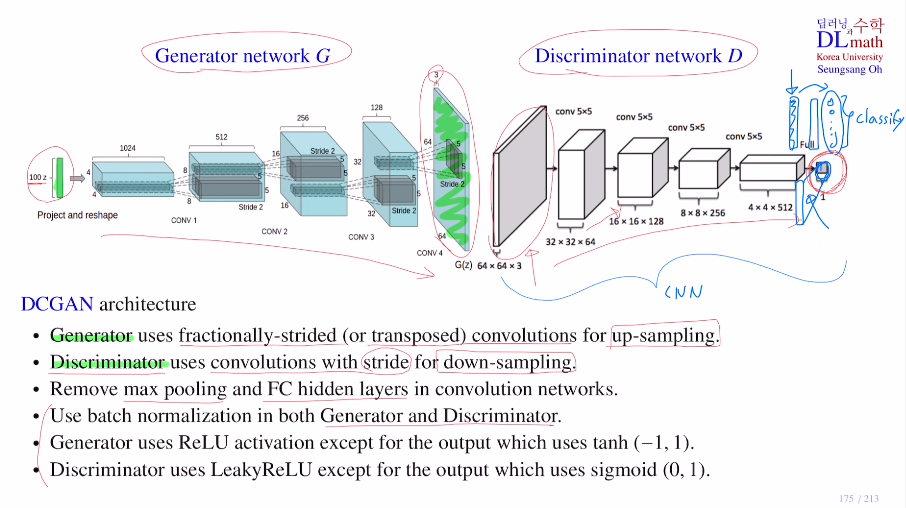
DCGAN의 재밌는 성질인 vector arithmetic을 알아보자.
만약 안경을 쓴 여자의 얼굴 데이터를 생성하고 싶을 때, vector arithmetic을 통해 latent vector를 조절하여 생성한다.
how?
안경을 쓴 남자 사진 latent vector들에서 평균(u)을 취하고 안경을 쓰지 않은 남자 사진 latent vector들의 평균(v)을 빼 주고, 여기에 안경을 쓰지 않은 여자 사진 latent vector들의 평균(w)을 더하여 새로운 latent vector를 만든다. : (u-v)+w
또한 latent vector v를 통해 만든 침실이 있고, latent vector w를 통해 만든 침실이 있을 때 이 둘을 이용하여 linear하게 만든다면 이 사이의 값들을 통해 중간 정도의 특징을 갖는 침실 모습을 만들 수도 있는 것이다.
이렇게 우리가 원하는 성질을 만들어 낼 수 있다!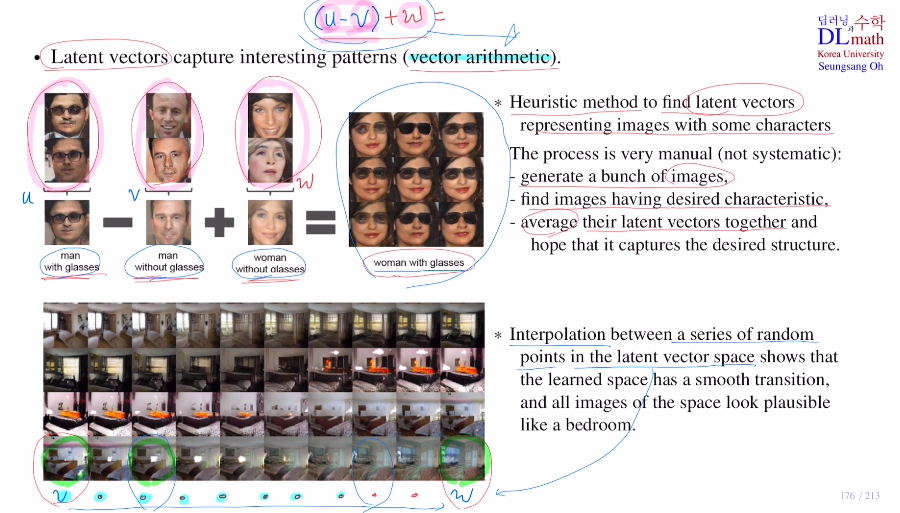
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=itjLt5BRzlU&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=40
