이전 포스터에서 DCGAN에 대해 알아본 것과 같이, 이번에도 다양한 GAN의 변형들을 알아보자.
우선 Progressive growing GAN : PGGAN 이다.
이 PGGAN은 이미지의 선명도를 올리게 한 모델이다. 아래는 PGGAN을 통해 만든 사람 얼굴이며 상당히 퀄리티가 높다. 또한 stability와 다양성도 더욱 높였다.
우선 전체적인 low resolution image로 전체적인 윤곽을 그린다. 그 후 점차적으로 resolution을 높이며 생성한다.
그렇기에 초기에는 전체적인 윤곽에 대해 학습하게 되고, 점점 레이어를 늘리며 세밀한 부분까지 초점을 맞춰 학습을 진행한다. 따라서 훨씬 빠른 속도로 학습하고 안정적으로 학습이 진행된다.
PGGAN의 구조는 아래와 같다.
real data가 1024x1024일 때 이를 전부 low resolution 4x4 data로 바꾼다.
이 latent vector를 생성자를 통해 fake data를 만들고 4x4 real data와 같이 판별자를 학습하게 된다. 이 경우는 저해상도의 이미지를 학습하기에 생성자, 판별자는 쉽게 학습할 수 있게 된다.
이번에는 레이어를 하나 더 늘려 진행시켜보자.
우선 1024x1024를 8x8 image로 바꾸고 이것을 real data로 생각한다. 그리고 생성자는 4x4를 8x8로 늘리며 생성하여 real data와 비교하며 학습한다. 여기서는 G와 D가 4x4까지는 이미 학습이 앞에서 되었기 때문에 4x4로 만들고 판단하는 것은 잘한다.
++ 기존 레이어들도 update를 진행하긴 한다!
이렇게 점점 레이어를 늘려가며 체계적으로 resolution을 늘려가며 학습을 진행한다.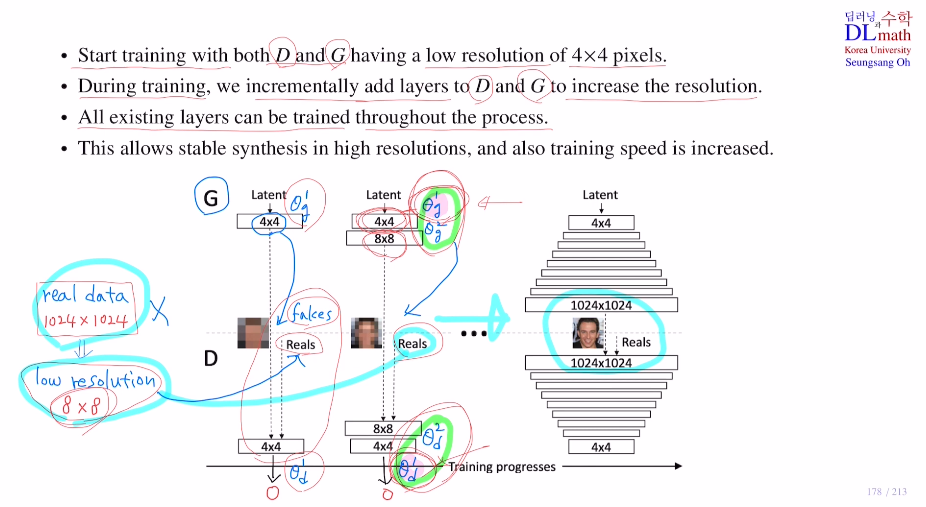
이번에는 Conditional GAN : cGAN에 대해 알아보자!
예를 들어 MNIST로 학습한다면 0~9사이의 적당한 수를 만들 것이다.
만약 특정한 수를 만들어라 라고 하고 싶다면?
학습하는 이미지 z에 대한 라벨과 같이 원핫 y로 함께 G와 D에 넣어 주어야 한다.
이렇게 condition part를 추가한 것이다.
이제는 real (x,y), fake (G(x,y), y) 로 목적함수에도 contion |y가 붙었다.
따라서 GAN은 비지도학습이지만 이 cGAN은 지도학습이라고 봐도 무방하다.
아래 5라는 condition을 주어 원하는 데이터를 생성하게 한다.
또한 사람의 나이에 맞게 generate하는데 나이라는 condition을 통해 사람의 얼굴을 생성해낸다. 물론 GAN은 같은 사람을 만드는 것이 아니라 다양한 것을 만드는 모델이기에 여기서는 identity preserving으로 추가적인 내용이 포함된다.
이번에는 cGAN을 사용한 Pix2Pix 이라는 모델을 알아보자.
이 모델은 image-to-image로 condition이 이미지가 되어 건물에 대한 스케치를 넣어주면 실제와 같은 이미지를 만들어 내는 것이다. 주로 low resolution에서 high로 바꿀 때 사용한다.
input 그림 x를 받고(이것이 condition) 실제 latent vector z를 통해 G(x,z)로 생성하게 된다. y가 real data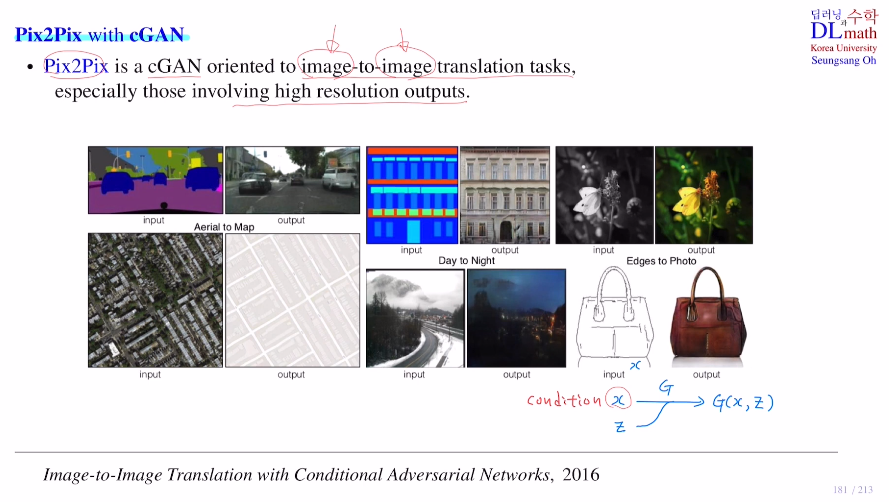
이 모델을 구체적으로 살펴보자.
목적함수는 아래와 같으며, ipnut x와 latent vector z를 통해 생성자가 G(x,z)로 fake 를 만들어 내고, D는 (x, G(x,z)) 인지 (x, y)인지 판별한다. 기존의 GAN에서 달리진 점은 기존에는 z, G / y 만 있었지만, fake real 두 군데에 x가 포함되어 있다.
따라서 목적함수에서도 x라는 condition들이 따라 다닌다는 차이점이 있다.
스케치 x를 참고하여 G에서 만든 부츠가 real data인 y부츠와 pixel by pixel로 최대한 일치하는 것이 좋다. 따라서 L1 distance term을 추가한다. 픽셀별로 절댓값 거리를 통해 이를 최소화하는 것이다.(따라서 G에서의 목적함수에만 포함된다.)
생성자는 스케치 x를 줄인 후 다시 만들어 내는 U-net을 사용한다.
판별자는 PatchGAN을 사용한다. 전체적인 윤곽보다는 디테일한 부분에 초점을 맞춰야 하기에 전체적으로 비교하는 것이 아닌 patch별로 비교를 진행하여 훨씬 디테일한 부분을 확인한다. 이렇게 되면 patch별로 비교를 하기에 훨씬 적은 파라미터로도 학습이 가능하다.
아래를 보면 Input을 통해 Gound truth를 만들고 싶은 것이다.
목적함수에서 L1 term만 사용했을 때와 cGAN만 사용했을 경우가 있으며 합친경우가 있다.
L1 term만 사용했을 때는 주로 흐리다. cGAN은 선명하지만 부분적으로 다른 부분이 있다.
패치 사이즈가 너무 커지면 이미지의 퀄리티가 떨어지기도 한다.
마지막으로 Cycle GAN 에 대해 알아보자.
이것은 Pix2Pix과 마찬가지로 image-to-image translation이다.
input으로 image가 들어오고 output으로 image를 보낸다.
하지만 차이점은 흑백 vs 컬러와 같은 경우는 많이 있지만, 같은 장소 같이 위치에서 여름과 겨울에 찍는 사진은 잘 없다. 이런 pair가 되어 있지 않은 데이터에 대해서 어떻게 하면 바꿀 수 있을지를 해결한다.
Cycle GAN은 여름사진을 겨울사진으로 generate하고 다시 이 겨울사진을 여름사진으로 generate하며 얼마나 원본과 유사한지를 따져가며 학습을 진행한다.
따라서 pix2pix은 x와y로 pair가 있지만 cycleGAN은 unpaired data를 가지고 진행한다. 두 개의 GAN 구조를 합쳐서 만든다. 따라서 목적함수에서 두 개의 GAN에 관한 식이 있다. fake인지 real인지 판단함과 동시에 동일한 그림을 만들어야 하기에 L1 distance term을 추가해준다.
문제는 각각 pair가 없기에, 다시 회복시킨 후 원본과 비교하는 것이다. 반대도 생성한 것을 복원시키고 다시 생성했을 때 비교한다.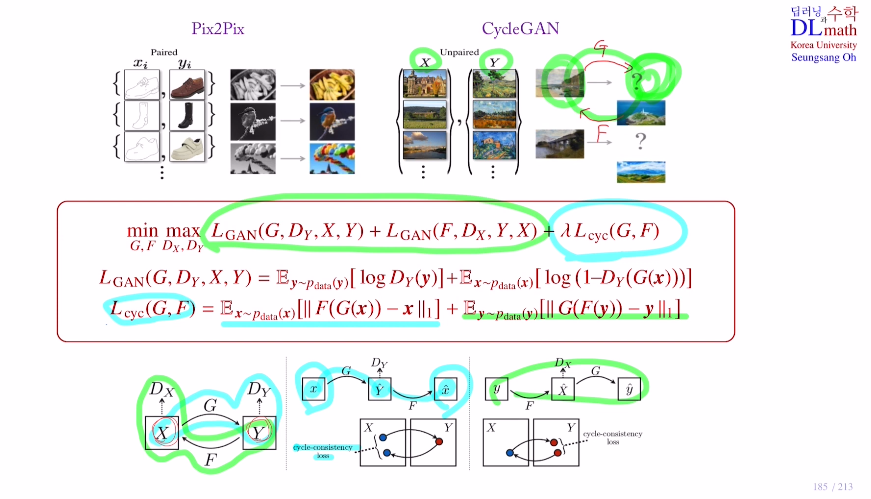
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=iwdX6ccPlsk&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=41
