GAN에서의 semi-supervised learning은 real data가 일부는 라벨을 갖고 있고, 일부는 갖지 않은 것이다. 여기서는 GAN을 사용하기에 fake data에 대한 것들도 있기에 조금 더 복잡한 구조를 갖는다.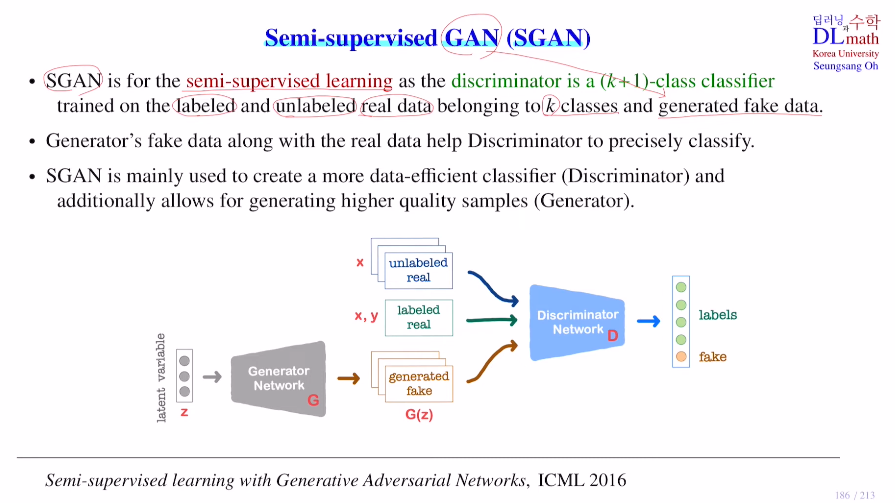
우선 semi-supervised learning에 대해 알아보자.
정답이 있는 문제를 푸는 지도학습(예를 들어 classification)과 따로 라벨이 없는 비지도 학습을(clustering) 둘 다 사용하는 방법이다. (둘의 데이터셋은 내용이 동일해야 한다.)
예를 들어 데이터가 10만개가 있을 때, 1000개의 데이터에 대해서는 라벨을 붙였을 때, 당연히 이 모든 데이터를 사용하고 싶다. 아래의 그림과 같이 라벨이 있는 있는 빨or파 데이터를 이용하여 라벨이 없는 데이터들도 빨인지 파인지 구분하고 싶은 것 이다.
우선 clustering을 통해 두 집단으로 나누고 위는 정답이 있는 데이터 중 빨간색은 위의 그룹에 있고, 파란색은 아래 그룹에 있기에 위는 전부 빨, 아래는 전부 파로 classify할 수 있는 것이다.
참고로 semi-supervised learning이 머신러닝에서 어떻게 사용되는지 알아보겠다.
몇 개의 빨, 파 데이터가 존재하고 회색 데이터들이 빨인지 파인지 구분할 수 있는 직선을 찾는 문제이다.
우선 지도학습 SVM에서 사용할 수 있는 데이터는 아래의 네 개 뿐이다. 이를 통해 margin을 구하고 최적의 선을 찾으면 아래와 같이 나온다. 하지만 이 직선은 가운데 그림을 보면 제대로 나누지 못 한다.
이번에는 unlabeled data까지 사용하는 semi-supervised인 Transductive SVM을 보자. 이번에는 라벨이 없는 데이터도 사용하기에 초록 최적선이 나타나고 이는 당연히 이전보다 좋은 classify를 진행할 수 있게 해준다.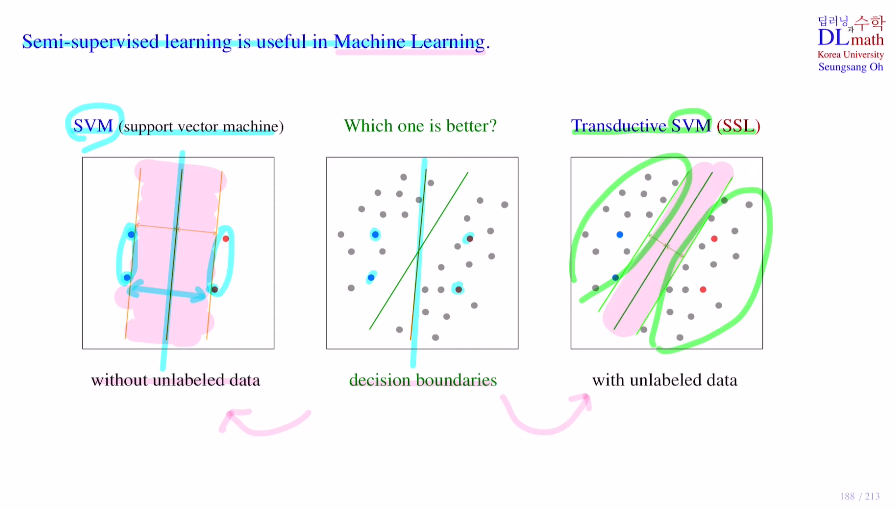
이제는 Semi-supervised GAN을 알아보자!
이제는 판별자가 기존의 GAN 판별자와는 다르다. 여기서 사용된 것은 labeled data를 가지고 classify하는 것이다. 어떻게 하냐면 real data에 포함되어 있는 k개의 클래스로 분류하고 추가로 fake data라는 클래스를 추가하여 총 k+1개의 클래스로 분류한다. 이 classifier가 판별자가 된다.
생성자는 latent vector가 들어오면 G(z)라는 fake data를 만들어 낸다. 여기서 달라지는 점은 real data인데 real data가 unlabeled data 와 labeled data가 있다.
그렇기에 판별자에 들어오는 input이 unlabeled data, labeled data, fake data 세 종류가 되는 것이다. 이 중에서 어떤 임의의 input하나가 들어왔을 때, 이것을 k+1개 클래스 중 어디에 속하는 지 classify하는 것이다!
Q. 그렇다면 unlabeled, labeled data만 사용하면 되는 것이지 왜 굳이 생성자를 통해 fake data까지 구분할까?
fake data를 추가하는 것에서 오는 장점을 알아보자.
예를 들어 개<->고양이 classify일 때, 판별자는 전반적으로 이것은 개이다. 이것은 고양이이다. 라고 판단하는 것이 아니라 이 둘의 차이를 비교하며 구분을 하는 것이다. 그렇기에 매우 제한적인 feature를 사용하여 분류한다.
생성자로 fake image를 생성해서 이 fake image도 들어온다고 해보자.
기존에는 단순히 개 고양이 두 클래스 차이를 통해 개 고양이를 분류했지만, 이제는 fake image도 들어왔기에 고양이인지 정확히 알 수 없으면 fake인지 구분하지 못 하게 되는 것이다. 이제는 판별자가 고양이 사진이 들어오면 단순히 강아지사진과 다르기에 고양이라고 분류하는 것이 아닌, 전체적으로 고양이인지를 판별하고 고양이라고 classify하게 되는 것이다!
=> 따라서 생성자의 도움을 받아 판별자는 특징을 정확히 구분할 수 있게 되는 것이다.
GAN에서는 생성자를 위한 학습이었지만, SGAN은 좋은 판별자를 만드는 것이 목표이다!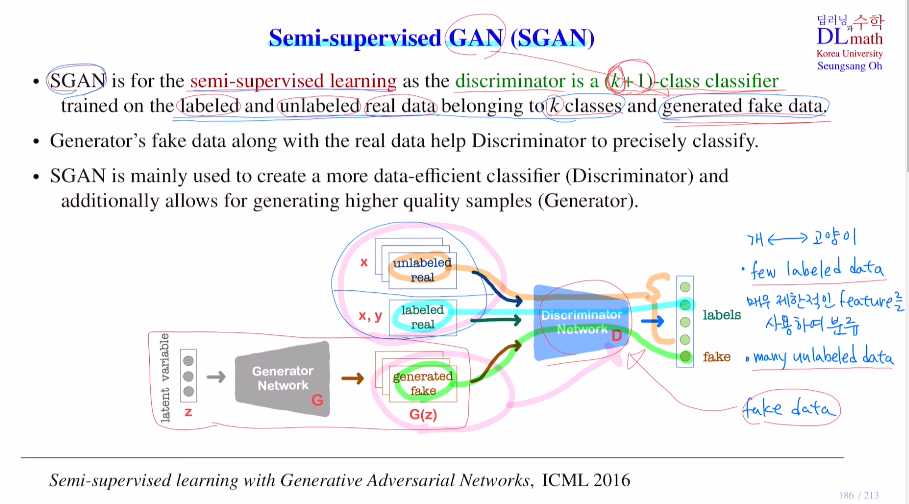
SGAN의 구조에 대해 자세히 살펴보자.
기존 GAN은 서로 고정시키며 반복적 학습을 진행했다. 또한 D는 0~1값으로 real의 여부를 판단했다. 또한 학습이 끝나면 판별자는 생성자를 위한 도구로 활용되었기에 버린다.
하지만 SGAN에서는 판별자가 multi-class classifier가 되는 것이다.
labeled data가 적기에 unlabeled data와 fake data를 활용하여 학습한다. 또한 학습이 끝난 후는 생성자는 버리고 판별자만 활용한다.
이제는 목적함수에 대해 알아보자.
학습할 때 판별자는 k+1개로 분류를 진행한다. 그렇기에 마지막에는 softmax를 통해 확률을 output으로 출력한다.
여기서도 판별자의 loss ft, 생성자의 loss ft이 있다.
1) Discriminator loss
판별자는 -를 붙였기에 gradient descent 방법을 사용한다.
당연히 지도학습과 관련된 term, 비지도학습과 관련된 term이 존재한다.
지도학습과 관련한 것은 정답에 가까우면 1 다르면 0에 가깝게 출력한다.
비지도 학습과 관련한 term은 unlabeled data, fake data 따로 존재하여 이를 더한다.
unlabeled data와 관련해서는 fake data라고 인식하지만 않으면 된다. 그렇기에 pmodel(y=k+1|x)(:fake일 확률)가 0으로 가게끔 학습을 진행한다.
fake data에 대해서는 fake data를 잘 판별하게 pmodel(y=k+1|x)를 1로 보내도록 학습하면 되는 것이다.
이 세 가지를 합하여 loss ft을 정의한다.
2) Generator loss
여기서 앞부분은 기존 GAN에서 사용하는 loss를 그대로 가져왔다.
판별자가 pmodel(y=k+1|G(z))를 0이라고 생각하게 만들어 log(1-pmodel(y=k+1|G(z))) 를 줄이는 방향으로 학습을 진행하게 된다.
추가적으로 feature matching이 있는데, semi-supervised learning의 성능을 올려주는데 기여한다. 기존의 GAN과 관련없는 loss ft으로 아래와 같은 공식을 사용한다. L2 norm을 사용하며, 쉽게 말해 두 벡터가 작아질 수록 유사해진다 라고 생각하면 된다. 실제 real data의 통계량(여기서는 평균)과 비슷하게 만들고 싶어하는 것이다.
feature matching에 대해 더 설명해보자면, 이를 통해 mode collapse(다양한 output을 만들지 못하고 몇 개만 생성한다.)를 막아주고자 하는 것이다. 아래와 같이 집중되어 있는 분포를 real data의 평균으로 오게 하여 데이터의 분포를 늘리고 위와 같은 그림으로 만들고자 하는 것이다.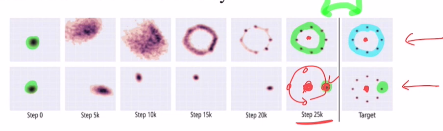
faeture matching을 통해 f(x)의 평균과 f(G(z))의 평균이 L2 norm으로 유사하게 만들어주며 다양한 종류의 데이터를 만들 수 있게 해준다.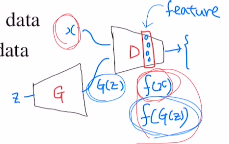
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=yPeXccuwfVs&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=42
