
이번 시간에는 Vanishing gradient, 기울기 소실에 대해 알아보자!
우선 아래는 7개의 미분 텀이 존재하는데 input layer, 2개의 hidden layer, output layer로 구성되어 있다.
(n:input data개수, j:중간output dim, k:output dim)
∂C/∂whi 를 계산하기 위해 activation ft을 3개 미분하고, weight sum을 3번 미분한다. layer가 늘어남에 따라 sum(w(dy/dz)) 가 추가된다. w는 파라미터이기에 상관을 하지 않아도 괜찮지만, activation ft을 미분하는데는 문제가 생긴다.
why?
우선 weighted sum(zi)이 0을 기준으로 조금만 멀어져도 yi=σ(zi)바로 값이 1에 가까워지거나 0에 가까워진다.
이렇게 되면 backpropa를 실행할 때, dy/dz=y(1-y) (sigmoid미분) 인데 1에 가깝거나 0에 가까운 값을 넣으면 0과 굉장히 가까운 값이 되어버리는 것이다!
이 activation ft미분할 텀이 많다면?!
그렇게 되면 결국 기울기 소실로 0에 가까운 값을 backpropa시 많이 곱하게 되고, update를 제대로 하지 못하게 된다.
이러한 기울기 소실 문제를 해결하기 위해 나온 것이 RelU이다.
Relu는 zi값이 0보다 크면 기울기 1, 작으면 기울기 0을 보낸다.
또한 이 외에도 leaky relu, tanh, ELU 등 많은 activation ft들이 존재하며, 미분값의 곱셈으로 인해 발생하는 문제이기에 ResNet과 LSTM의 경우에는 합을 사용하여 0으로 가는 것을 방지하고 layer를 깊게 쌓을 수 있게 된다.

뒷부분 layer들은 output값이 크지 않아 큰 gradient값을 갖기에 학습 속도가 빠르다. 하지만 앞 부분은 gradient들이 작은 값이기에 학습이 느리고 update를 제대로 하지 못해 대부분 weight들이 초기 random값 그대로 자리잡게 된다.
하지만 중요한 점은 실제로 앞 부분이 빠르게 학습되어야 한다. 왜냐하면 초기 엉망인 데이터를 넘겨주면 당연히 뒷부분도 엉망일 것이기 때문이다. 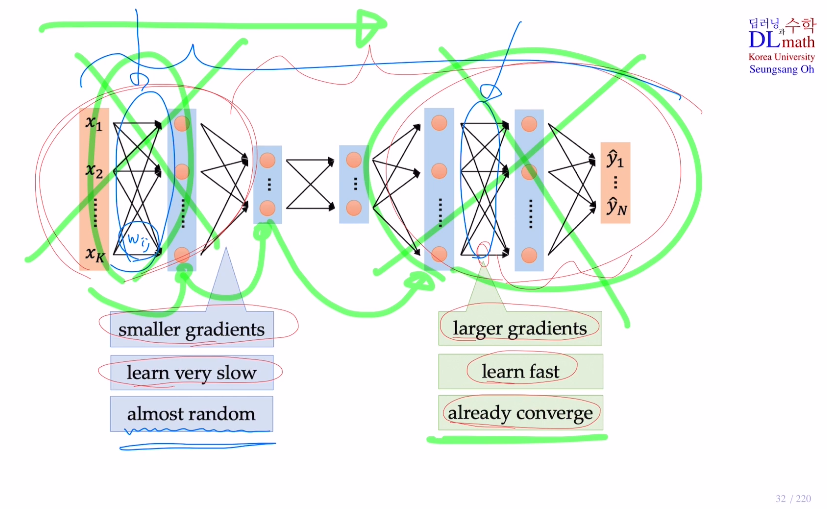
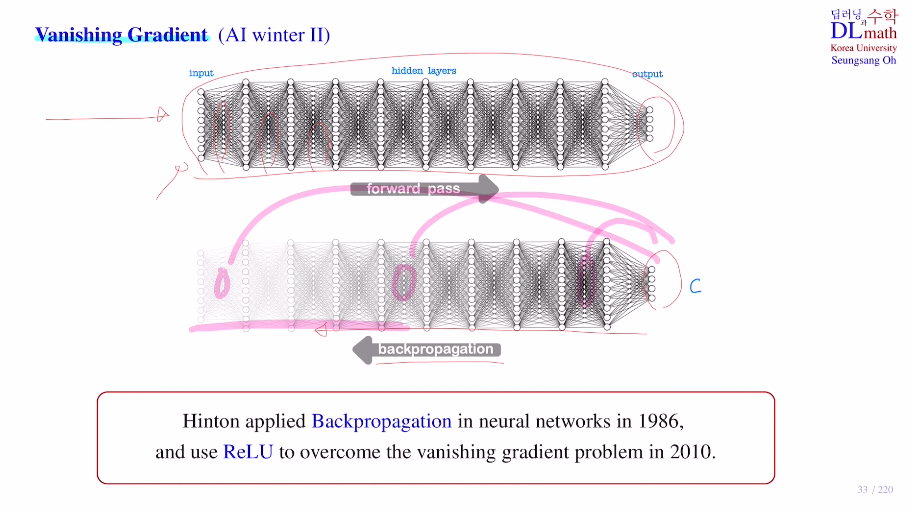
이러한 layer가 깊어짐에 따라 앞부분의 기울기 소실 문제로 인해 AI winter 2 가 다가왔다. Hinton교수가 편미분을 수월하게 하기 위한 Backpropagation을 고안해내어 2차 AI붐이 왔지만, layer가 깊어질수록 쉽지 않았다. 1986
하지만 역시 Hinton교수. 2010년에 새로운 activation ft ReLU를 만들어 문제를 해결했다. AI 3차 붐
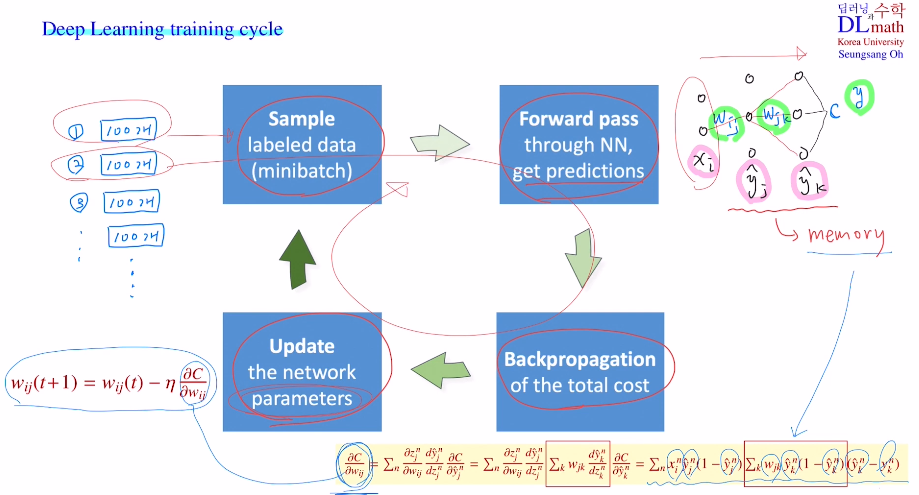
딥러닝의 training cycle 정리
mini batch를 취하여 random sampling으로 batch만들기
-> forward pass
-> backpropagation
-> parameter update 반복
고려대학교 오승상 교수님 딥러닝 : https://www.youtube.com/watch?v=6pEBMa7Xilo&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=7
