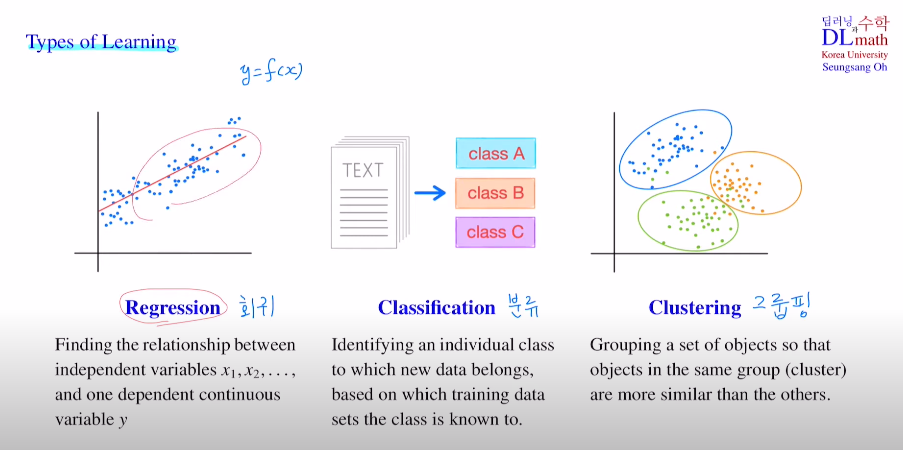
Linear regression : 데이터들을 잘 설명할 수 있는 선형 함수
회귀에서 사용되며 이 모형을 만들고 새로운 데이터가 들어왔을 때, 이를 이용하여 예측값을 도출해낸다.
Q. 그렇다면 이 모형은 어떻게 최적화시킬까?
MSE를 이용한 Cost을 통해 각 편미분으로 파라미터 기울기와 편향값을 최적화 시켜 나간다.

multi variables인 경우?
편향도 그냥 weight로 두고 본다면, 위와 비슷하게 아래로 표현하여 학습을 진행한다.
한 가지 살펴볼 점은 수학적 수식에서는 wTx로 쓰지만, 코딩에서는 xTw로 계산하게 된다는 점이다.

위의 회귀에서 사용되는 linear regression과 달리 logistic regression(Binary Classification)은 이진 분류 문제에서 사용된다. output 자체가 회귀는 실수, 분류는 하나의 class값을 도출한다.
Logistic Regression은 linear regression을 분류에 사용하기 위해 효율적으로 변형한 모델이다. 전체 실수 값을 가지는 모형을 0과1사이의 값을 가질 수 있게 변형시킨 것이다. 이를 통해 argmax를 진행함으로 0or1로 직관적인 분류가 가능하다.
(sigmoid ft = logistic ft)
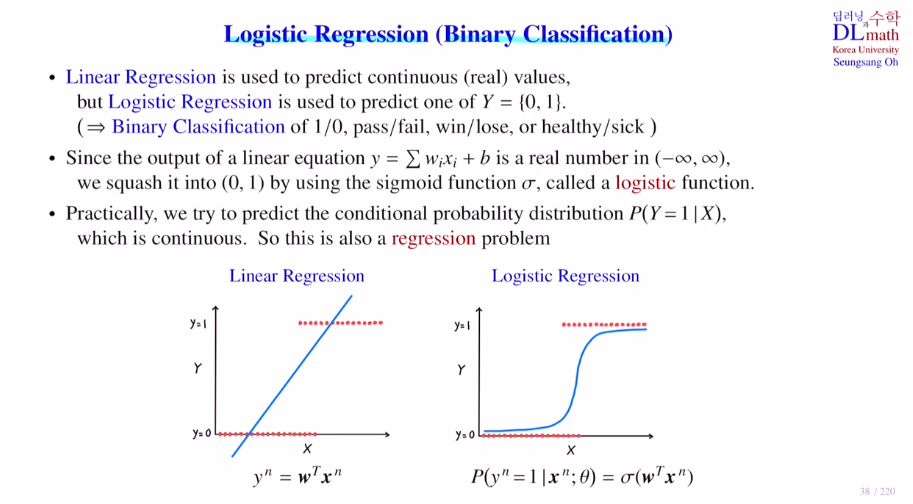
로지스틱 회귀의 Cost ft : CrossEntropyLoss
회귀문제에서 MSE를 사용하는 것과 달리 분류문제에서는 이 Cross Entropy를 사용하는 것이 효율적이다. 마지막 줄을 비교하면 계산의 용이성 뿐 아니라 h(1-h)처럼 기울기 소실 문제도 있기 때문이다.(물론 마지막 layer에서만 한 번 사용되지만)
정답이 1인 경우와 0인 경우를 나누어 계산한다. 이를 종합하면 아래와 같이 하나의 식으로 정의할 수 있다. 모든 데이터에 대해 계산한 값을 평균낸 것이 최종적인 Cross-Entropy Loss가 되는 것이다. 이 식은 미분할 때도 값이 기존의 알고 있는 값으로 도출되기에 굉장히 유용하다.

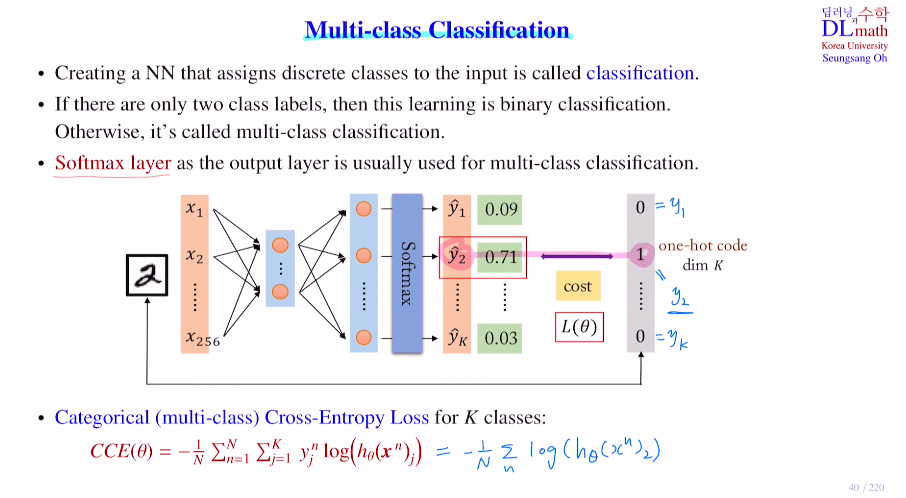
output이 두개로 이진분류가 아닌 다중분류라면?!
Categorical Cross-Entropy
binary가 아닌 multi-class classification이다.
마지막에 softmax layer를 사용하는데, 나온 값을 이용하여 정답이 1인 값만을 이용하여 아래와 같이 sumation을 하나 없애고 1에 가까울 수록 작은 값이 되어 쉽게 계산할 수 있게 된다.
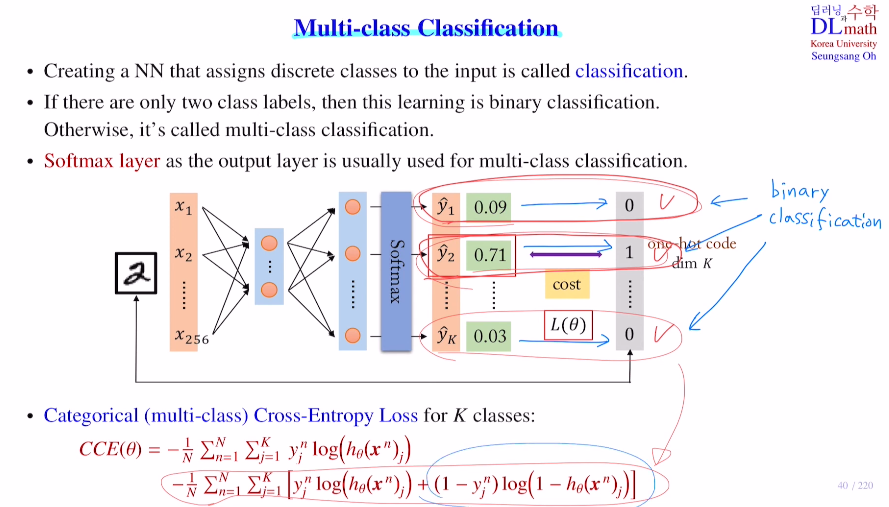
새롭게 모든 term에 대해 binary cross entropy를 사용한다고 생각해도 된다. 그렇게 되면 CCE식이 아래와 같이 추가적인 항과 함께 변한다.
참고로 keras의 CCE는 위의 방식을 사용한다.
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=JmNuhmkqY5g&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=9
