1. 대표적인 딥러닝을 이용한 세그멘테이션 FCN
논문 :https://arxiv.org/abs/1411.4038
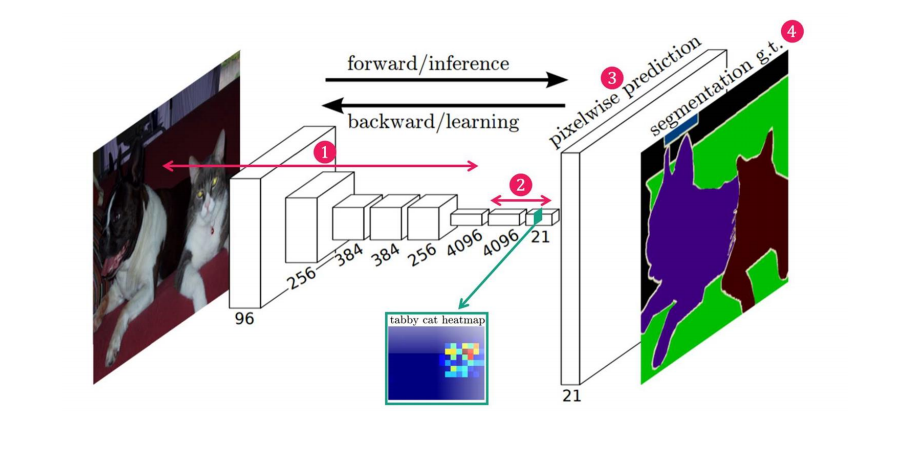
-
요약: 이 연구는 완전한 합성곱 네트워크(fully convolutional networks)를 사용하여 이미지의 임의 크기 입력에 대해 효율적으로 크기에 맞는 출력을 생성하고, 학습 및 추론 속도를 개선한 모델을 제안
-
특징
- VGG 네트워크 백본을 사용 (Backbone : feature extracting network)
- VGG 네트워크의 FC Layer (nn.Linear)를 Convolution 으로 대체
- Transposed Convolution을 이용해서 Pixel Wise prediction을 수행
1.1 VGG( Visual Geometry Group)
VGG의 핵심 특징은 작은 3x3 필터를 사용하여 깊이 있는 네트워크 구조를 구성함으로써, 복잡한 특징을 더 잘 학습할 수 있도록 한 것(3x3 필터는 작은 크기의 필터를 반복적으로 사용해 수용 영역을 넓히고, 계층적 특성 학습을 통해 더 복잡한 특징을 잘 포착할 수 있는 효과적인 선택)
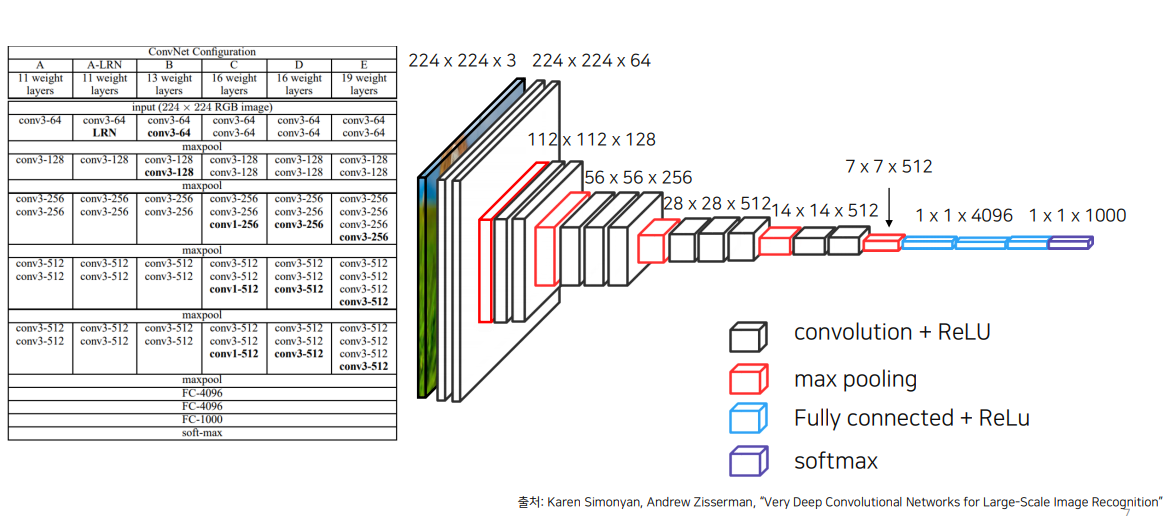
VGG를 사용하면 Backbone 이 pretrained 된 weight를 해치지 않음.
1.2 Fully Connected Layer vs Convolution Layer
FCN은 픽셀의 위치정보를 해침/
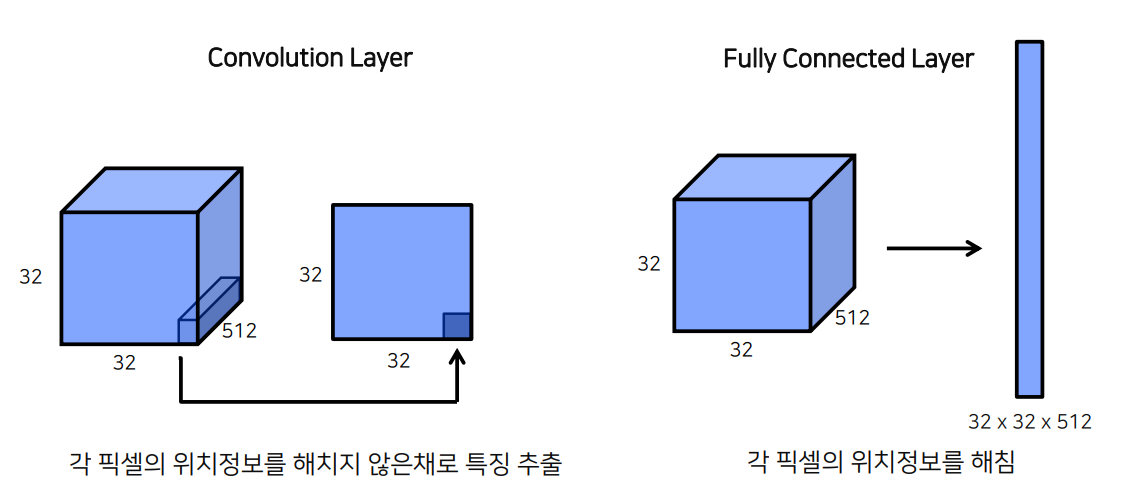
시각화

convolutional 를 사용할 경우 모델이 무엇에 집중했는지 잘 보여줌.
또한
1x1 Convolution을 사용할 경우, 임의의 입력값에 대해서도 상관 없는 이유
-> Convolution은 kernel의 파라미터에 의해 영향을 받고, 이미지 혹은 레이어의 크기에 대해서는 상관 없음(이유:1x1 필터가 공간적인 정보 대신 채널 차원의 정보를 다루기 때문)
즉, 1x1 Convolution은 공간적인 패턴을 처리하지 않고, 입력 채널 간의 상호작용만 수행하기 때문에 이미지나 레이어의 크기와 독립적으로 작동

헷깔릴까봐 정리
- Width와 Height: 이미지의 공간적 해상도를 나타내며, 커널이 이동하는 기준이 됨.
- Input Channel: 이미지 또는 레이어의 입력 채널 수로, 입력되는 데이터의 특성 정보(RGB, 흑백 등)를 포함.
- Output Channel: 특정 레이어가 생성하는 출력 채널 수로, 학습한 특징 맵의 수를 의미하며, 네트워크의 성능과 연관.
1.3 Transposed Convolution
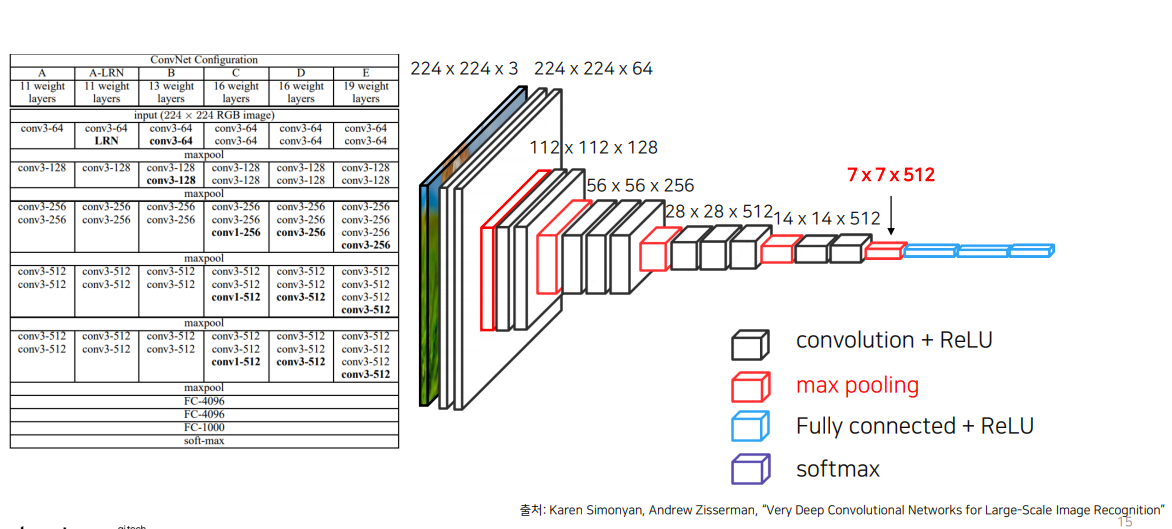
conv3-64 : 3x3 필터와 64개의 출력채널
마지막에 upsampling을 해야함.
upsampling
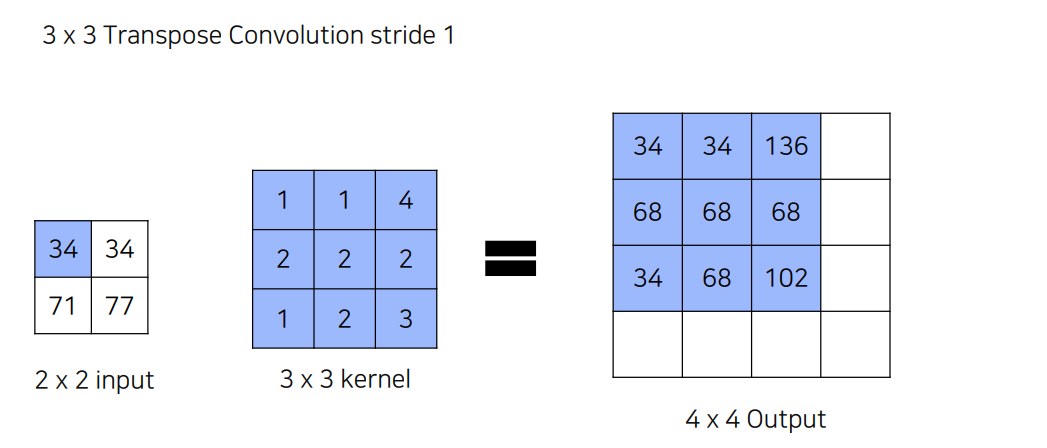
34x[1,1,4...,3]
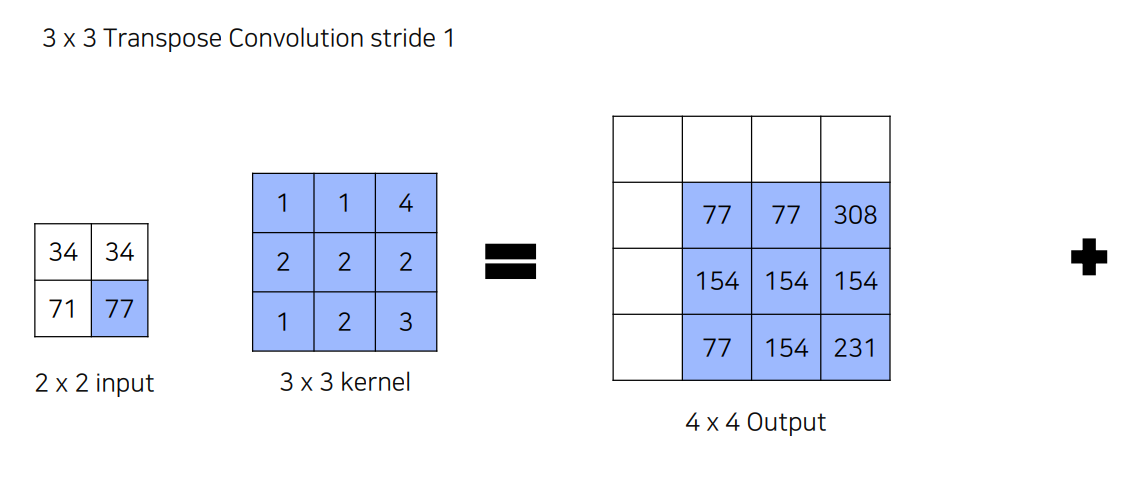
77x[1,1,4,...,3] =[77,...,231] 이렇게 됨.
요약하면
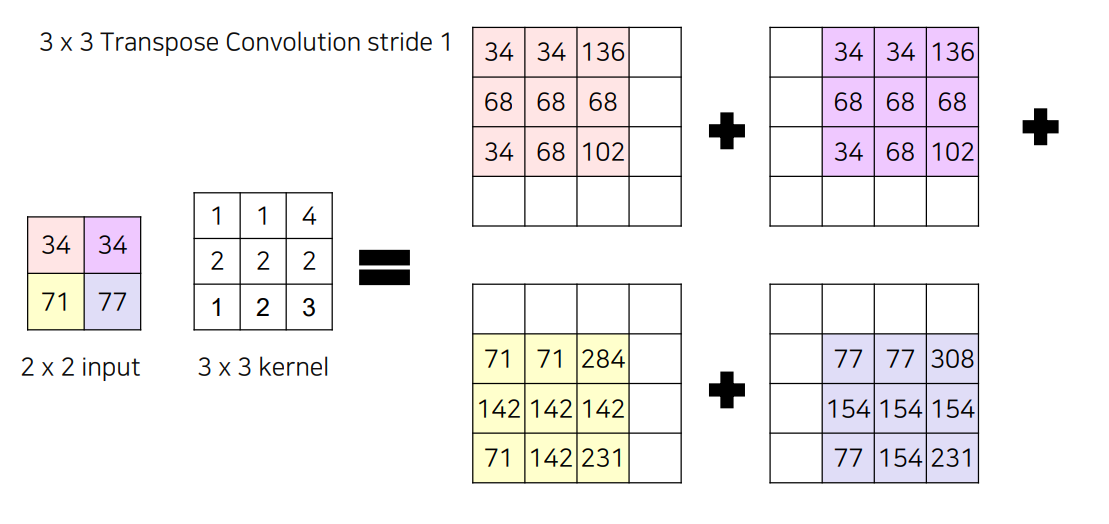
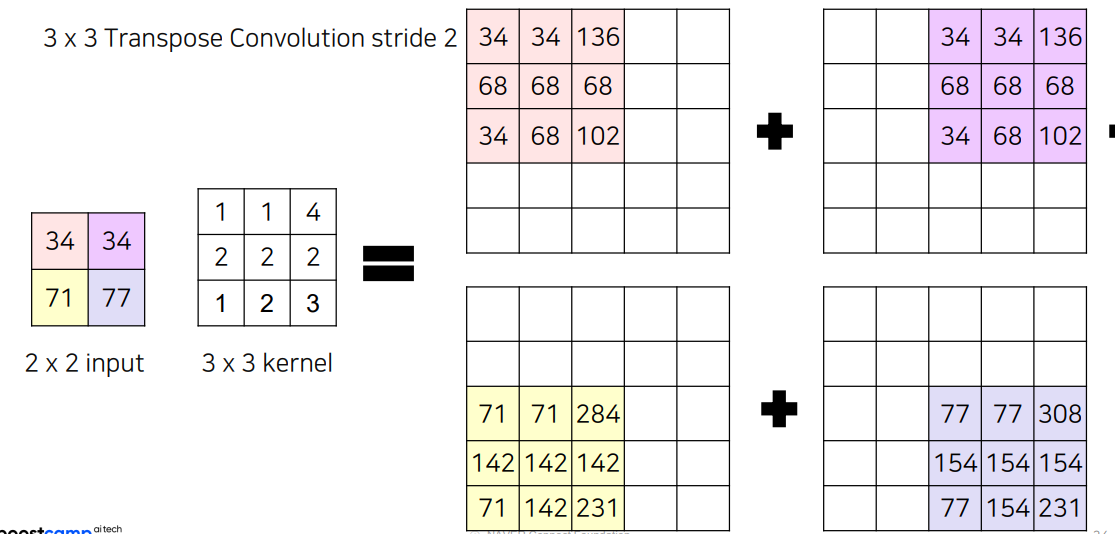
이런식으로 나오는데 중간에 겹치는건 어떻게 하나?
-> 다 더해줌 ㅎㅇ?
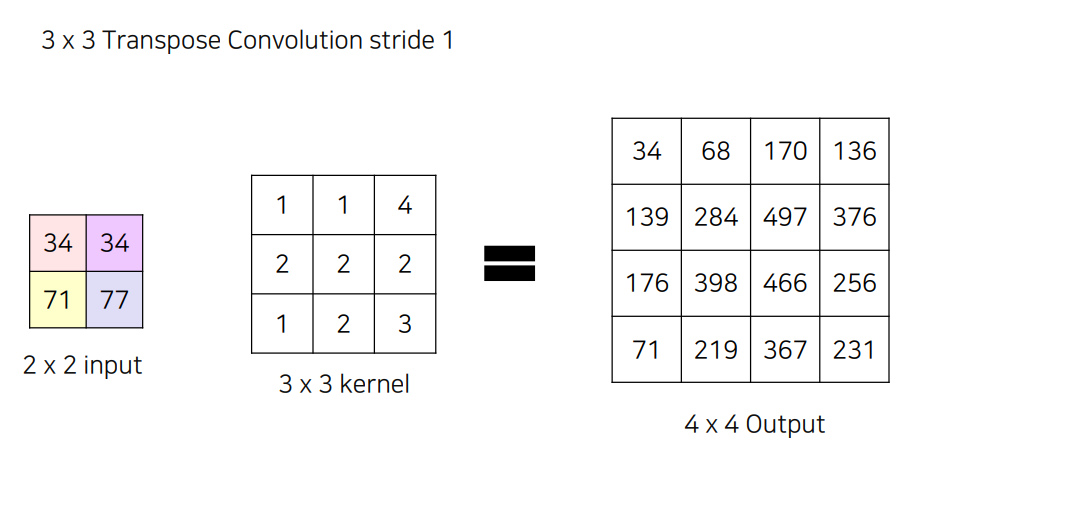
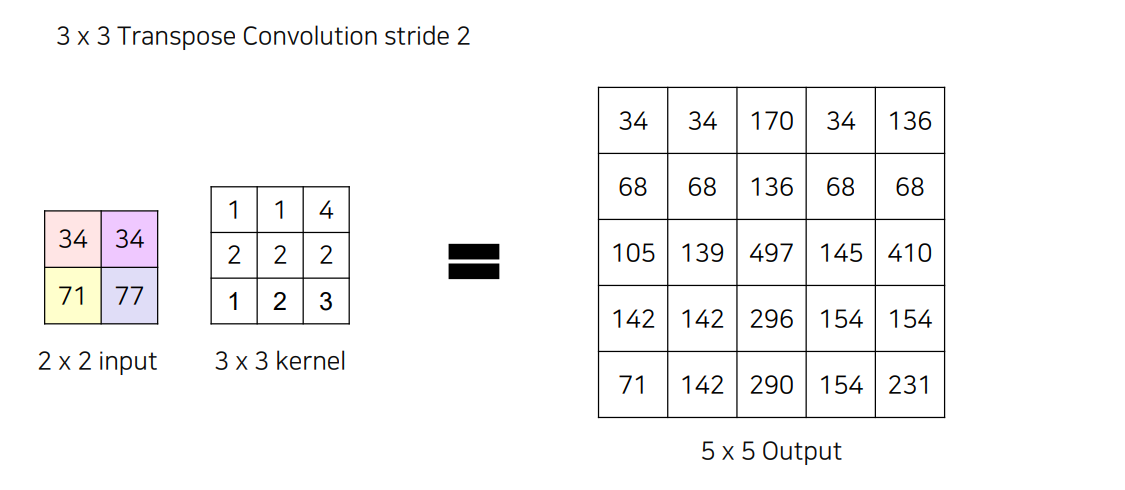
만일 5x5의 Output을 만들고 싶으면 어떻게 해야 할까요?
Stride를 주어서 해주면 됨
ex)
용어

왜 Transposed Convolution 이라고 불리는가?
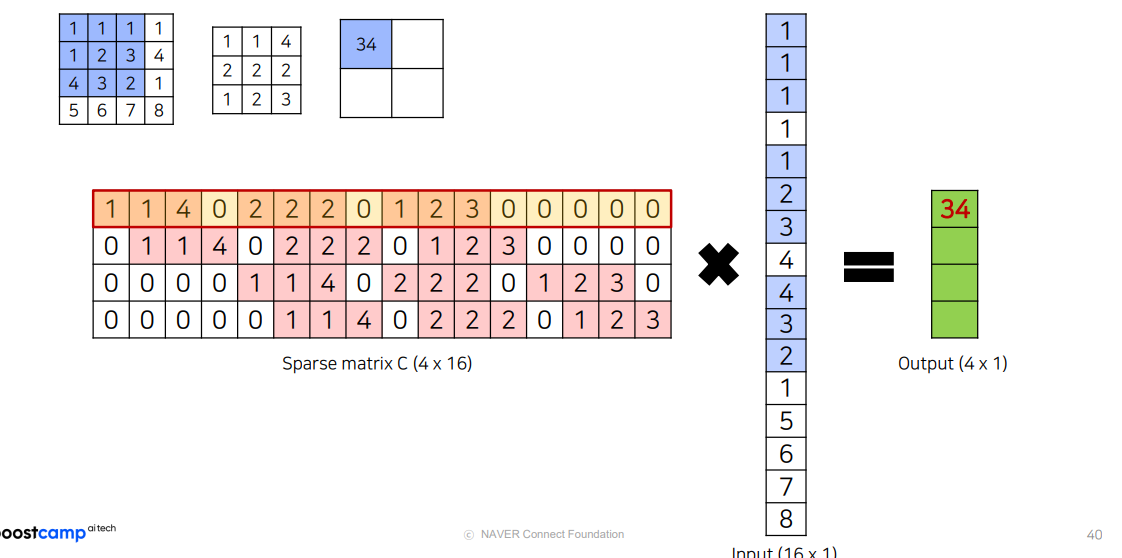
행렬곱을 해보면 똑같음.
하지만
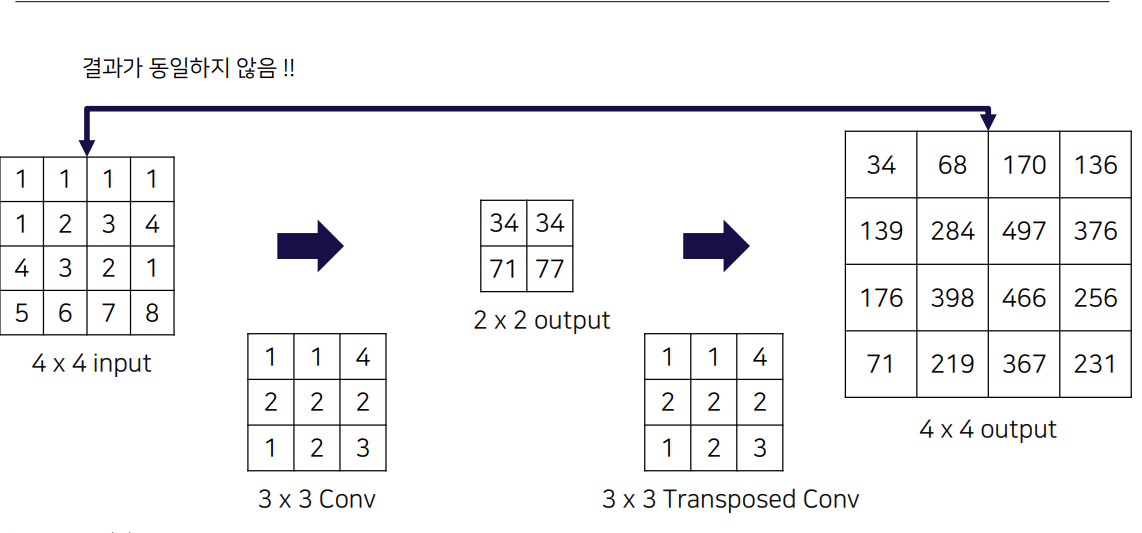
위 예제에서와 같이 동일하지 않은 경우도 있을 수 있음.
Transposed Convolution 정리
-
중요한 점은 Convolution과 마찬가지로 학습이 가능한 파라미터를 통해서
줄어든 이미지를 다시 키우는 Convolution이라는 점 -
엄밀한 명칭은 Transposed Convolution이라고 부르는게 정확 하지만 많이들
Deconvolution이라는 용어와 같이 사용하니 참고
Transposed Convolution의 값은 이전 Convolution의 값과 동일한 값이 아니라 Convolution 처럼 학습이 가능한 파라미터.렇기에 Backpropagation 과정에서 Update 되는 값
1.4 FCN에서 성능을 향상시키기 위한 방법

import torch.nn as nn
# CBR 함수 정의
def CBR(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding),
nn.ReLU(inplace=True)
)
# 네트워크 정의
class Network(nn.Module):
def __init__(self, num_classes):
super(Network, self).__init__()
# conv1
self.conv1_1 = CBR(3, 64, 3, 1, 1)
self.conv1_2 = CBR(64, 64, 3, 1, 1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# conv2
self.conv2_1 = CBR(64, 128, 3, 1, 1)
self.conv2_2 = CBR(128, 128, 3, 1, 1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# conv3
self.conv3_1 = CBR(128, 256, 3, 1, 1)
self.conv3_2 = CBR(256, 256, 3, 1, 1)
self.conv3_3 = CBR(256, 256, 3, 1, 1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# conv4
self.conv4_1 = CBR(256, 512, 3, 1, 1)
self.conv4_2 = CBR(512, 512, 3, 1, 1)
self.conv4_3 = CBR(512, 512, 3, 1, 1)
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# conv5
self.conv5_1 = CBR(512, 512, 3, 1, 1)
self.conv5_2 = CBR(512, 512, 3, 1, 1)
self.conv5_3 = CBR(512, 512, 3, 1, 1)
self.pool5 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# fc6
self.fc6 = CBR(512, 4096, 1, 1, 0)
self.drop6 = nn.Dropout2d()
# fc7
self.fc7 = CBR(4096, 4096, 1, 1, 0)
self.drop7 = nn.Dropout2d()
# score
self.score_fr = nn.Conv2d(4096, num_classes, 1, 1, 0)
# upscore using deconv
self.upscore32 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=64, stride=32, padding=16)
def forward(self, x):
x = self.pool1(self.conv1_2(self.conv1_1(x)))
x = self.pool2(self.conv2_2(self.conv2_1(x)))
x = self.pool3(self.conv3_3(self.conv3_2(self.conv3_1(x))))
x = self.pool4(self.conv4_3(self.conv4_2(self.conv4_1(x))))
x = self.pool5(self.conv5_3(self.conv5_2(self.conv5_1(x))))
x = self.drop6(self.fc6(x))
x = self.drop7(self.fc7(x))
x = self.score_fr(x)
x = self.upscore32(x)
return xupsampling 할때 한번에 너무 한번에 upsampling 하는 것은 아닌가? 하는 의문이 들 수 있다.
실제로 결과를 살펴보면
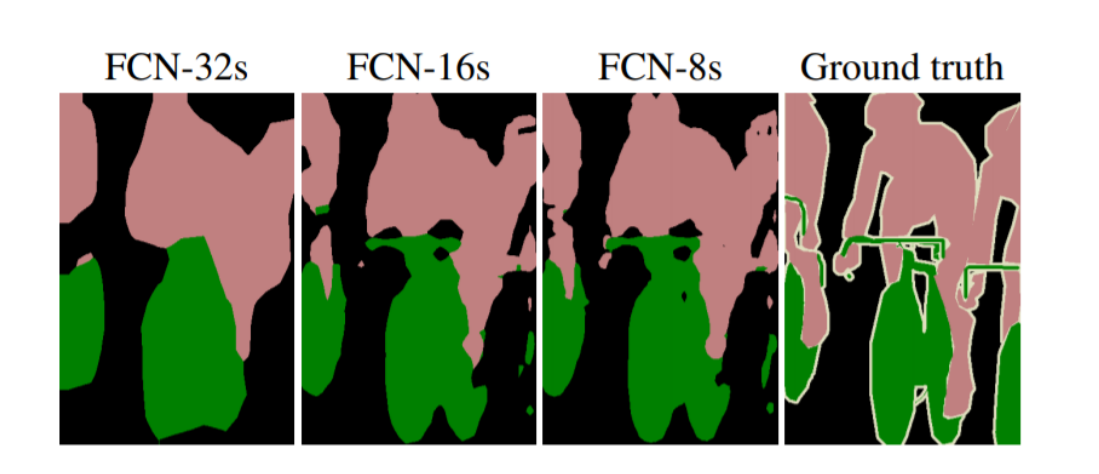
32, 16, 8은 네트워크가 원본 이미지에 비해 몇 배로 다운샘플링된 출력을 제공하는지를 나타내며,32배 다운샘플링한거 < 16<8 로 다운샘플링이 적을수록 upsampling이 잘 됬음을 알 수 있다.
Predicted 를 더해서 성능 향상
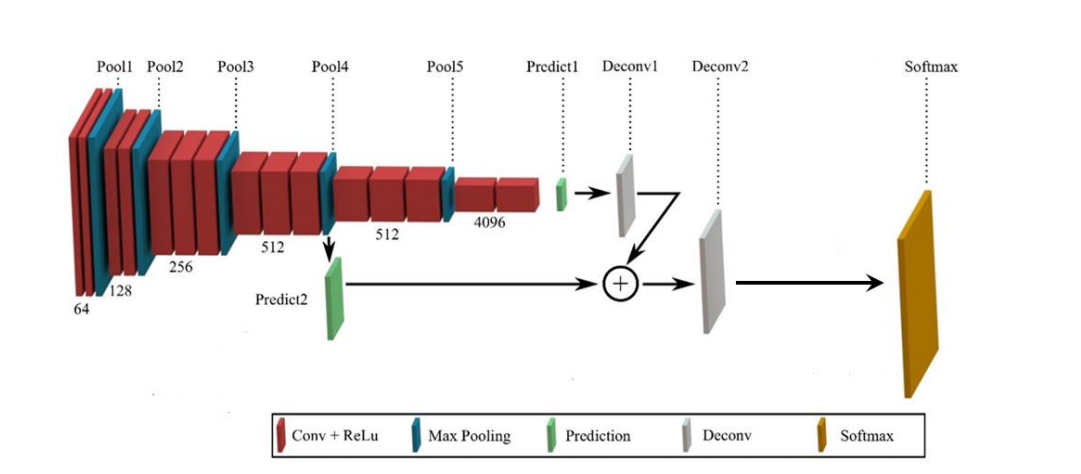
- MaxPooling에 의해서 잃어버린 정보를 복원해주는 작업을 진행
- Upsampled Size를 줄여주기에 좀 더 효율적인 이미지 복원이 가능
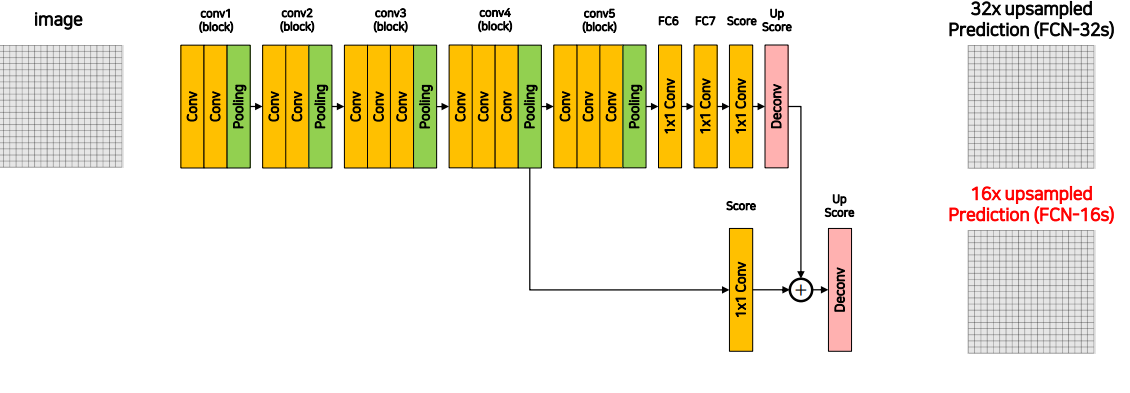
import torch.nn as nn
# CBR 함수 정의
def CBR(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding),
nn.ReLU(inplace=True)
)
# 네트워크 정의
class Network(nn.Module):
def __init__(self, num_classes):
super(Network, self).__init__()
# conv1
self.conv1_1 = CBR(3, 64, 3, 1, 1)
self.conv1_2 = CBR(64, 64, 3, 1, 1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# conv2
self.conv2_1 = CBR(64, 128, 3, 1, 1)
self.conv2_2 = CBR(128, 128, 3, 1, 1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# conv3
self.conv3_1 = CBR(128, 256, 3, 1, 1)
self.conv3_2 = CBR(256, 256, 3, 1, 1)
self.conv3_3 = CBR(256, 256, 3, 1, 1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# conv4
self.conv4_1 = CBR(256, 512, 3, 1, 1)
self.conv4_2 = CBR(512, 512, 3, 1, 1)
self.conv4_3 = CBR(512, 512, 3, 1, 1)
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# conv5
self.conv5_1 = CBR(512, 512, 3, 1, 1)
self.conv5_2 = CBR(512, 512, 3, 1, 1)
self.conv5_3 = CBR(512, 512, 3, 1, 1)
self.pool5 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# fc6
self.fc6 = CBR(512, 4096, 1, 1, 0)
self.drop6 = nn.Dropout2d()
# fc7
self.fc7 = CBR(4096, 4096, 1, 1, 0)
self.drop7 = nn.Dropout2d()
# score
self.score_fr = nn.Conv2d(4096, num_classes, 1, 1, 0)
# 1x1 conv layers for skip connections
self.score_pool4 = nn.Conv2d(512, num_classes, 1, 1, 0)
# upsampling layers
self.upscore2 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1)
self.upscore16 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=32, stride=16, padding=8)
def forward(self, x):
# Encoder
x = self.pool1(self.conv1_2(self.conv1_1(x)))
x = self.pool2(self.conv2_2(self.conv2_1(x)))
x = self.pool3(self.conv3_3(self.conv3_2(self.conv3_1(x))))
pool4 = self.pool4(self.conv4_3(self.conv4_2(self.conv4_1(x)))) # Save for skip connection
x = self.pool5(self.conv5_3(self.conv5_2(self.conv5_1(pool4))))
# Fully connected layers
x = self.drop6(self.fc6(x))
x = self.drop7(self.fc7(x))
x = self.score_fr(x)
# FCN-16s: upsample x by 2 and add score from pool4
x = self.upscore2(x)
score_pool4 = self.score_pool4(pool4)
# Crop and add skip connection
x = x[:, :, :score_pool4.size(2), :score_pool4.size(3)] + score_pool4
# FCN-16s: upsample final result by 16 to match input size
x = self.upscore16(x)
return x
논문에서는
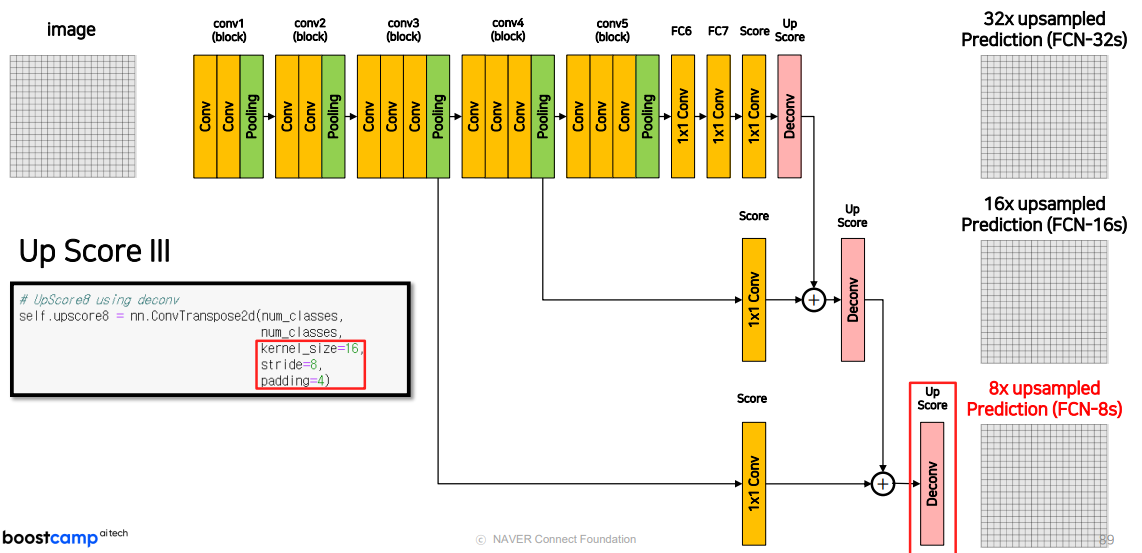
2번 predicted 를 잔차학습 시킴.
1.5 평가지표
Pixel Accuracy
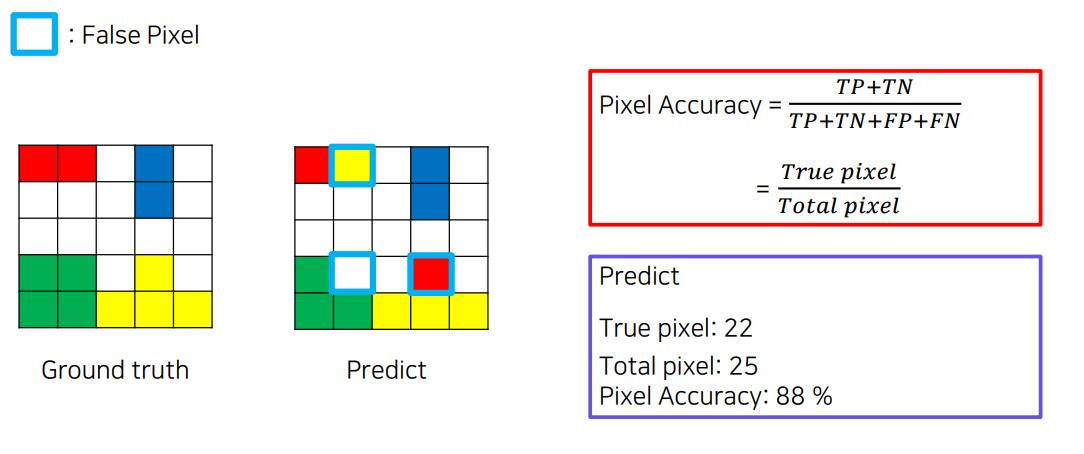
mean IOU
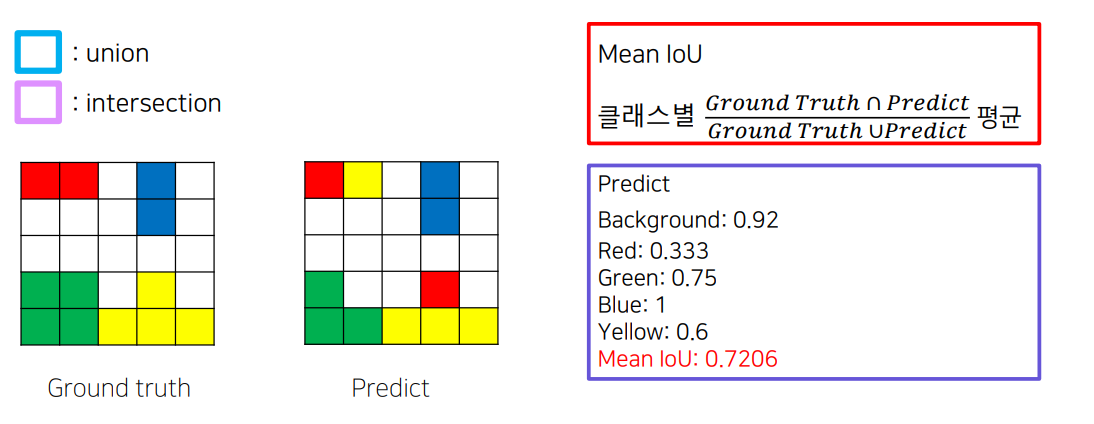
2. 결론
2.1 Further Reading
7x7 convolution 으로 바꿀 때 발생하는 문제
• FC6 Layer의 Convolution을 지나면, 이미지의 크기가 변동되는 문제가 발생
• 저자의 코드에서는 위의 문제를 해결하기 위해서 conv1의 첫번째 conv에 zero padding을 100을 넣어줌
• 하지만, Output Size와 달라지는 문제가 발생
7x7 Convolution으로 바꿀 때 발생하는 문제를 설명하자면, 주로 다음과 같은 이유와 해결 방법이 논의되고 있습니다.
1. 문제의 발생 원인: FC6 Layer에서 이미지 크기 변동
기존의 1x1 또는 3x3 Convolution을 사용하는 네트워크에서 7x7 Convolution으로 변경하면, 필터 크기가 커짐에 따라 입력 이미지에 대한 출력 크기가 줄어드는 문제가 발생합니다.
Convolution 연산의 특성상 필터 크기가 커지면, 패딩을 하지 않는 한 출력의 크기가 줄어들게 됩니다.
특히 FCN에서 FC6 레이어는 큰 필터(7x7)가 사용되며, 그 결과로 입력 이미지의 공간 해상도가 줄어드는 문제가 발생할 수 있습니다.
2. 문제 해결을 위한 패딩 조정
원래 저자의 코드에서는 이 문제를 완화하기 위해, 첫 번째 Convolution 레이어(conv1)의 첫 번째 conv에 Zero Padding을 100으로 설정해줍니다.
패딩을 늘리면 입력 이미지의 경계에 가상의 픽셀을 추가하여 출력 크기가 지나치게 줄어드는 것을 방지할 수 있습니다.
이를 통해 큰 필터를 적용하면서도 일정한 크기의 출력을 얻으려는 의도입니다.
3. 하지만 발생하는 문제: Output Size 불일치
패딩을 적용해도 출력 크기가 완전히 일정하게 유지되지 않을 수 있습니다.
특히, Zero Padding을 100으로 설정하면 입력 이미지의 경계에 100 픽셀씩 추가하게 되는데, 이는 최종 출력 크기를 원본 이미지 크기와 정확히 일치시키지는 못할 수 있습니다.
따라서, 패딩 조정만으로는 출력 크기를 정확히 보정하는 데 한계가 있습니다.
요약
7x7 Convolution을 사용하면 필터 크기 때문에 이미지의 크기가 줄어드는 문제가 생깁니다.
이를 Zero Padding 100으로 보완하려고 했지만, 이 방식으로도 출력 크기가 완벽하게 맞춰지지 않는 문제가 남아 있습니다.
결과적으로, 패딩만으로 해결할 수 없는 출력 크기 불일치 문제가 발생하며, 이로 인해 추가적인 보정이 필요할 수 있습니다.
이 문제는 Convolution을 할 때 발생하는 공간 해상도 손실을 고려해야 하는 이유 중 하나로, 정확한 출력 크기를 얻기 위해 더 복잡한 조정이 필요할 수도 있습니다
summation 할때마다 crop를 해줘서 해결하였다고 저자들은 말함.
2.2 정리
3. 참조논문
Fully Convolutional Networks for Semantic Segmentation
https://arxiv.org/abs/1411.4038
