1. Receptive Field를 확장시킨 models
1.1 DeepLab v2
DeepLab v2는 다양한 스케일의 정보를 효과적으로 결합하여 이미지 내의 객체를 정확히 분할하는 데 특화된 구조를 가진 아키텍처
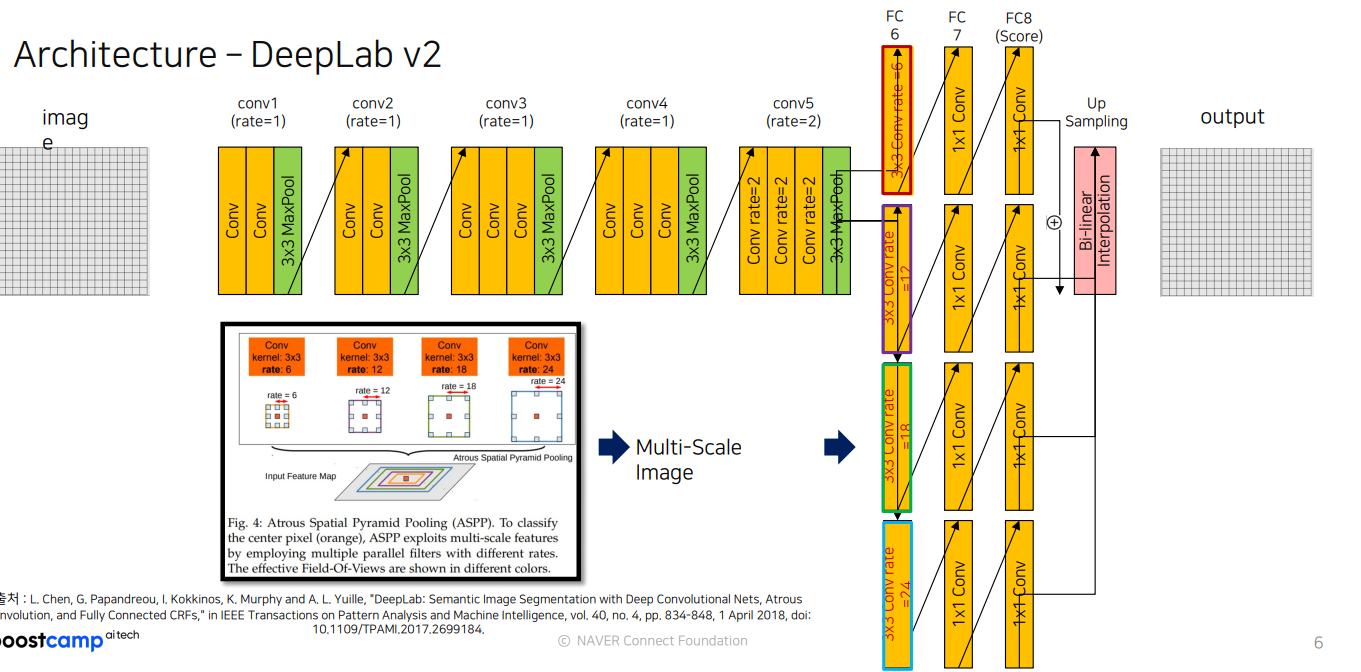
특징(feature)
- 기본 컨볼루션 레이어:
DeepLab v2는 기본적으로 여러 개의 컨볼루션 레이어와 Max Pooling 레이어를 통해 이미지를 다운샘플링하며 특징을 추출합니다.
conv1부터 conv5까지의 레이어는 다양한 크기의 특징 맵을 생성하여 이미지의 주요 정보를 포착합니다.
- Dilation Rate:
conv5 이후 레이어부터 dilation rate를 사용하여 필터 크기를 확장합니다.
dilation rate가 커지면서 더 넓은 영역의 정보를 받아들일 수 있어 이미지의 세부적인 컨텍스트를 반영할 수 있습니다. FC6와 같은 레이어에서는 rate가 6, 12, 18, 24와 같이 매우 크며, 이는 넓은 영역의 정보를 동시에 처리하여 여러 스케일의 정보를 병합할 수 있게 해줍니다.
- Atrous Spatial Pyramid Pooling (ASPP):
DeepLab v2의 핵심 기능으로, 다양한 dilation rate를 사용한 여러 개의 3x3 컨볼루션 레이어로 구성됩니다.
다양한 필드 오브 뷰에서 특징을 추출하여 이를 합치는 구조로, 여러 스케일의 정보를 효과적으로 통합합니다. ASPP는 작은 물체와 큰 물체를 모두 정확하게 분할하는 데 도움을 줍니다.
- 1x1 Conv 레이어와 Upsampling:
ASPP의 출력은 1x1 컨볼루션 레이어를 거쳐 FC6, FC7, FC8 등으로 연결됩니다.
마지막에 Bilinear Interpolation을 통해 업샘플링을 수행하여 입력 크기로 복원합니다.
이 과정을 통해 이미지 분할 결과를 원래 이미지 크기로 확장하여 시각화할 수 있습니다.
deeplab v2 구조
import torch.nn as nn
# conv1_block 정의
conv1_block = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(num_features=64),
nn.ReLU()
)
# maxpool 정의
maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# conv2_sub_block 정의
conv2_sub_block = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=256)
)
# identity_block 정의
identity_block = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=256)
)
# conv3_sub_block_downsample 정의
conv3_sub_block_downsample = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=512, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=512)
)
# identity_block 수정 정의
identity_block_modified = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=1, stride=2, padding=0),
nn.BatchNorm2d(num_features=512)
)
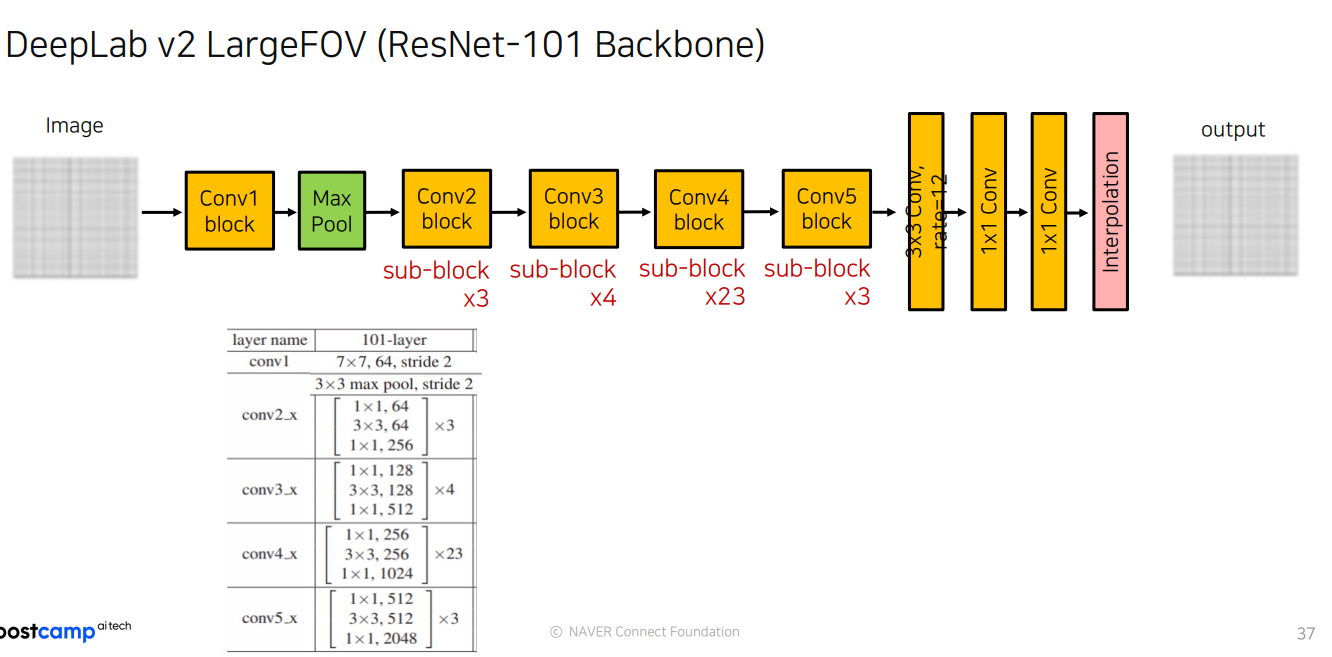
- DeepLab v2의 ResNet-101 Conv4 block은 down-sampling을 수행하지 않으며, dilated convolution을 사용
- DeepLab v2의 ResNet-101 Conv5 block은 down-sampling을 수행하지 않으며, dilated convolution을 사용
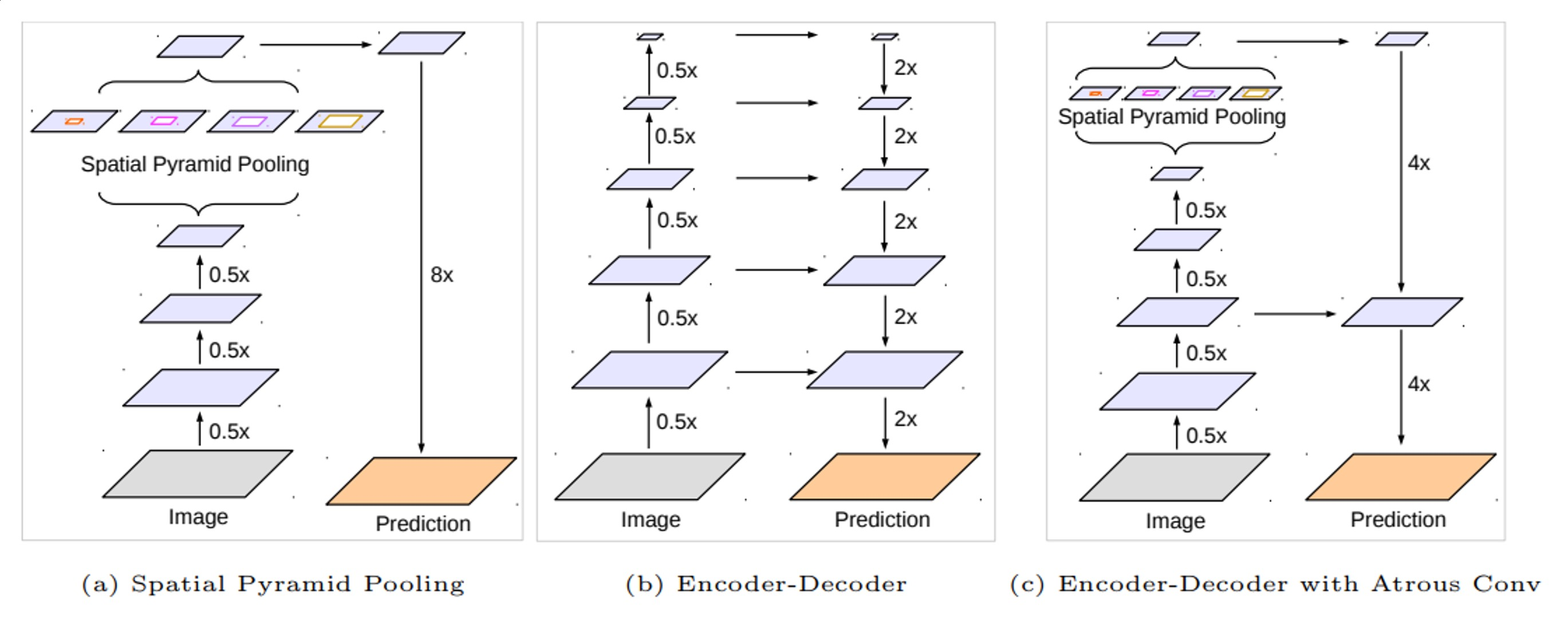
1.2 PSPNet(Pyramid Scene Parsing Network)
PSPNet 도입배경
- Mismatched Relationship
- 호수 주변에 boat가 있는데 기존 모델(FCN)은 car로 예측
- 이유 : boat의 외관이 car와 비슷하기 때문
- idea : 주변의 특징을 고려(e.g. water 위의 boat)
- Confusion Categories
- FCN은 skyscraper를 skyscraper 와 building을 혼돈하여 예측
- 원인 : ADE20K data set의 특성상 비슷한 범주인 building과 skyscraper 존재
- idea : category간의 관계를 사용하여 해결 (global contextual information 사용)
- Inconspicuous Classes
- FCN은 pillow를 bed sheet로 예측
- 원인 : pillow의 객체 사이즈가 작을 뿐만 아니라 bed sheet의 커버와 같은 무늬 예측에 한계
- idea : 작은 객체들도 global contextual information을 사용

PSPNet 도입 배경 II
FCN도 Maxpool에 의해 줄였는데, 왜 안될까?

이미지에서 보여주는 Places-CNN과 ImageNet-CNN의 receptive field 비교를 보면, 각 layer에서 수용 영역(receptive field)의 크기가 서로 다르다. FCN에서도 유사하게 각 레이어의 receptive field 크기가 달라지며, 이는 객체의 위치와 크기 인식에 영향을 미치며 FCN이 특정한 경우에 대해 성능이 떨어지는 것은 이러한 receptive field 차이에 기인!
Architecture -PSPNet
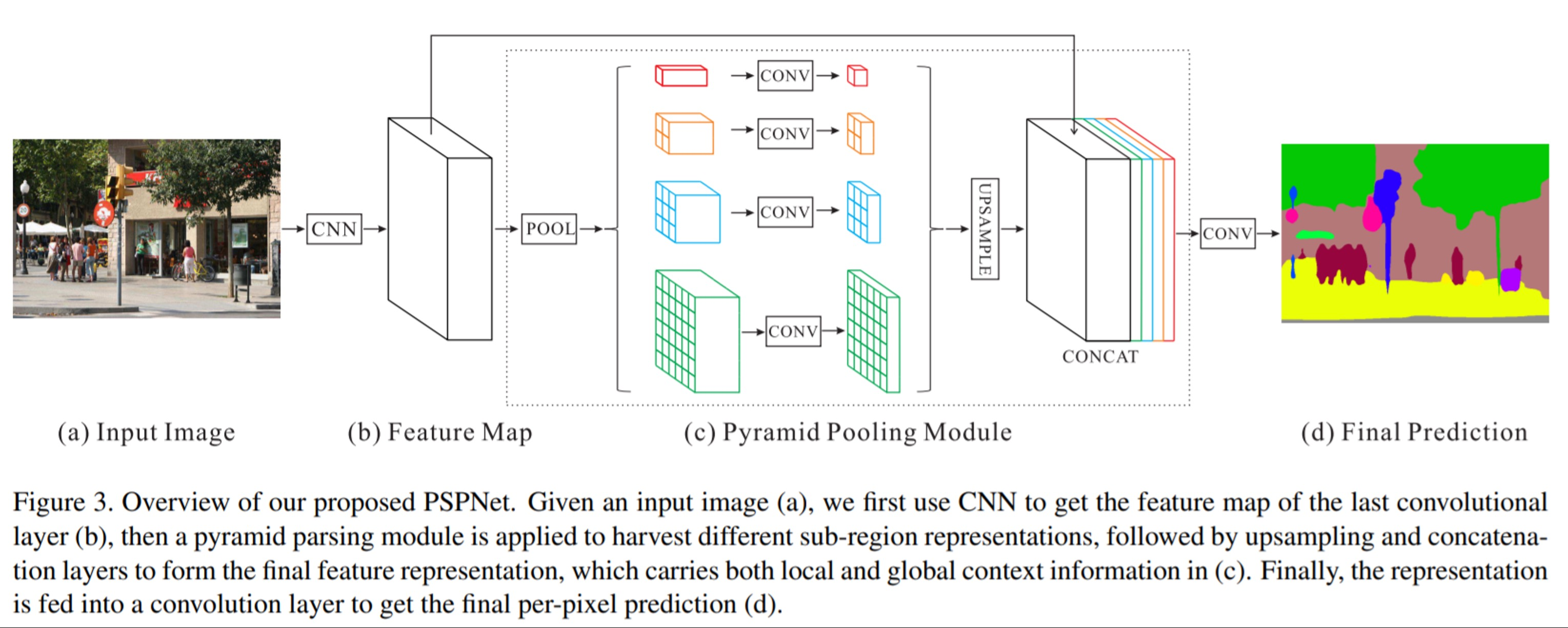
여기서 가장 중요한 부분은 (C) Pyramid Pooling Module이다.
(c) Pyramid Pooling Module
Pyramid Pooling Module을 사용하여 다양한 공간적 맥락을 얻는다. 이 모듈에서는 각기 다른 크기의 pooling 영역을 사용하여 여러 스케일에서의 정보를 추출!!
-
여러 스케일로 pooling: 작은 영역에서 큰 영역에 이르기까지 다양한 크기의 영역에서 pooling을 수행하여, 세부적인 정보와 전체적인 맥락 정보를 동시에 확보합니다.
-
Pooling 결과를 Convolution에 통과: 각 pooling 결과는 1x1 convolution을 통과하여 차원을 축소하고, 필요한 특성만 남깁니다.
-
Upsample 및 Concatenate: 각기 다른 크기에서 추출된 정보를 원래 크기로 upsampling한 후, 이를 하나로 결합(concatenate)하여 전체 feature map으로 만듭니다.((b) Feature map 과 (c) Pyramid Pooling Module을
Upsample한 output을 서로 CONCAT)
Feature Map에 Average Pooling 적용해 sub-region을 생성, 1 x 1 , 2 x 2, 3 x 3 , 6 x 6 출력의 Average Pooling 적용
Global Average Pooling(Architecture)
주변 정보(문맥)을 파악해서 객체를 예측하는데 사용
-> 전체 영역을 평균내서 대표하는 값으로 나오게 함.
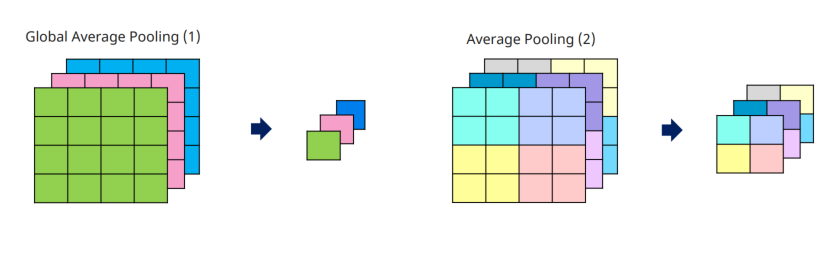
Convolution vs Average Pooling
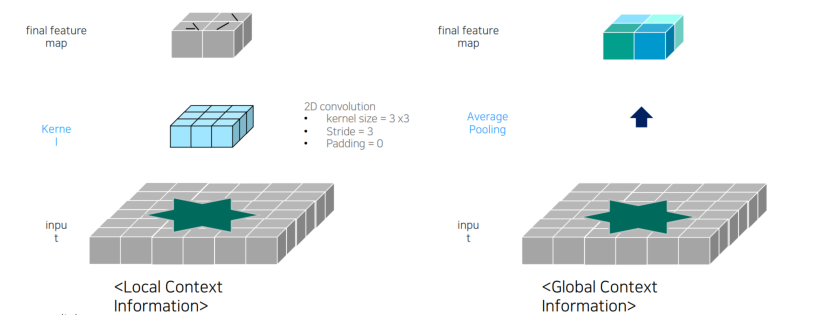
convolution은 local 한 정보를 가져왔다면, average는 global한 정보 가져옴.
1.3 DeepLab v3
Architecture – DeepLab v3
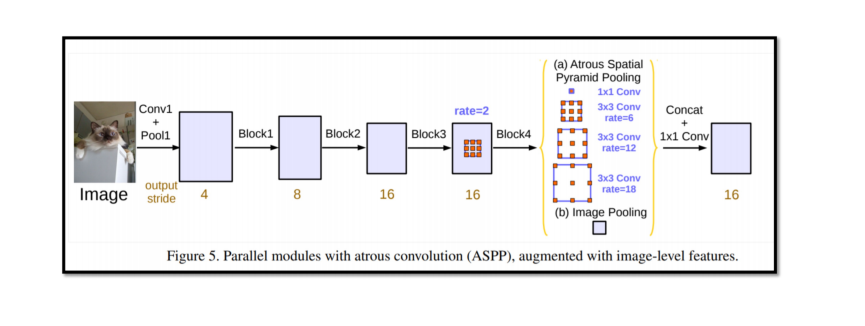
각 convolution의 rate가 다르며, 이로 인해 receptive field의 크기가 달라진다.
->Deeplabv3의 ASPP는 dilated convolution을 사용하여 여러 rate를 통해 다양한 receptive field를 가지도록 설계
1.4 DeepLab v3+
Architecture – DeepLab v3+
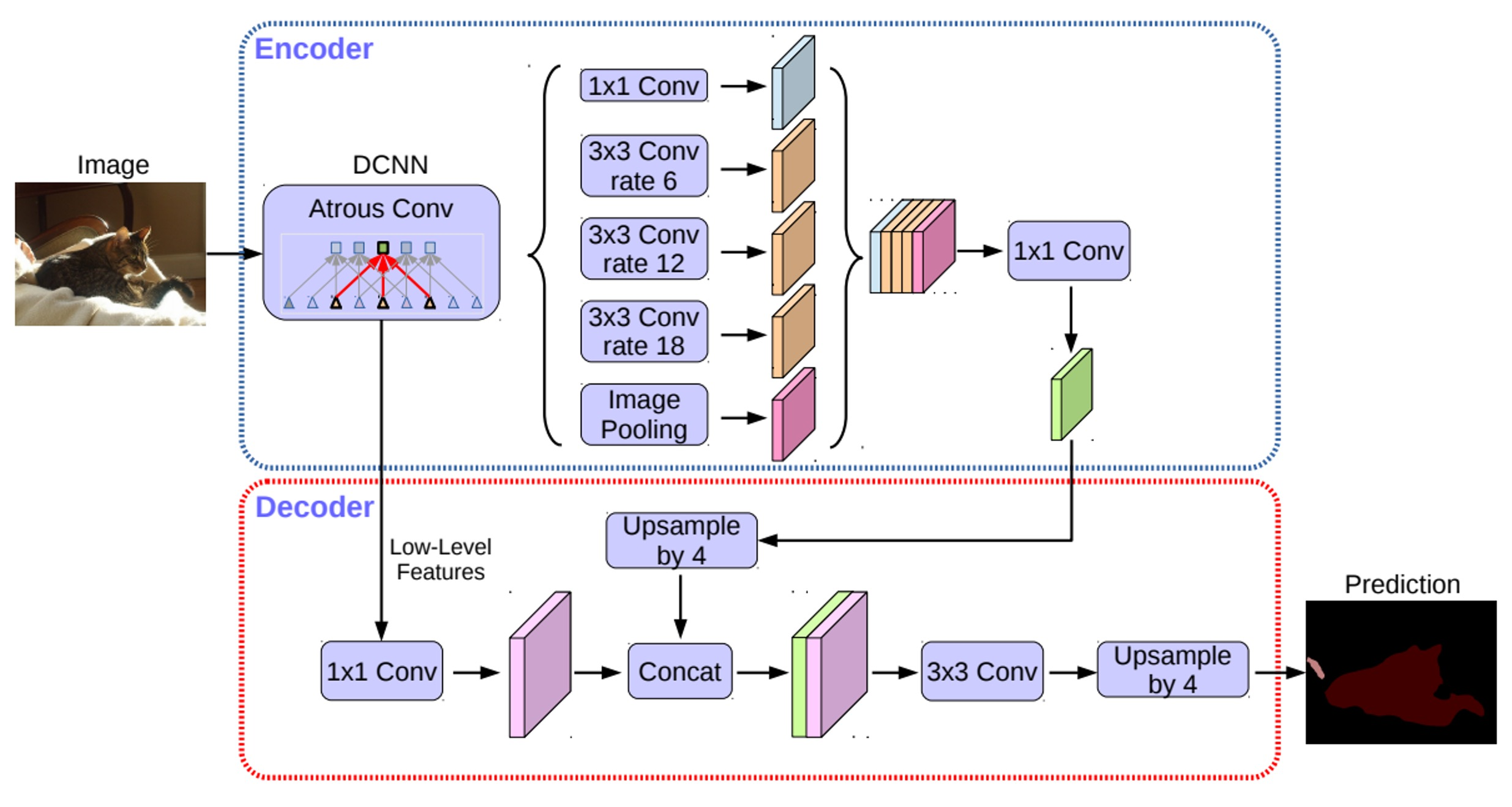
Encoder/ Decoder 의 구조를 가지는게 가장 다르다. 이를 자세하게 살펴보자
Architecture - DeepLab v3+ (Encoder-Decoder 구조)
Encoder에서 spatial dimension의 축소로 인해 손실된 정보를 Decoder에서 점진적으로 복원
Encoder
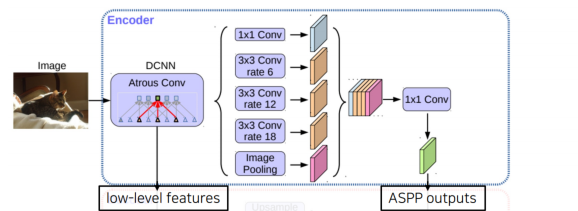
- 수정된 Xception을 backbone으로 사용
- Atrous separable convolution을 적용한 ASPP 모듈 사용
- Backbone 내 low-level feature와 ASPP 모듈 출력을 모두 decoder에 전달
Decoder
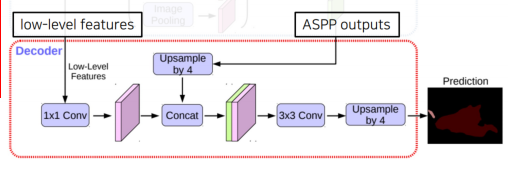
- ASPP 모듈의 출력을 (bilinear)up-sampling하여 low-level feature와 결합
- 결합된 정보는 convolution 연산 및 up-sampling 되어 최종 결과 도출
- 기존의 단순한 up-sampling 연산을 개선시켜 detail을 유지하도록 함
modified Xception Backbone
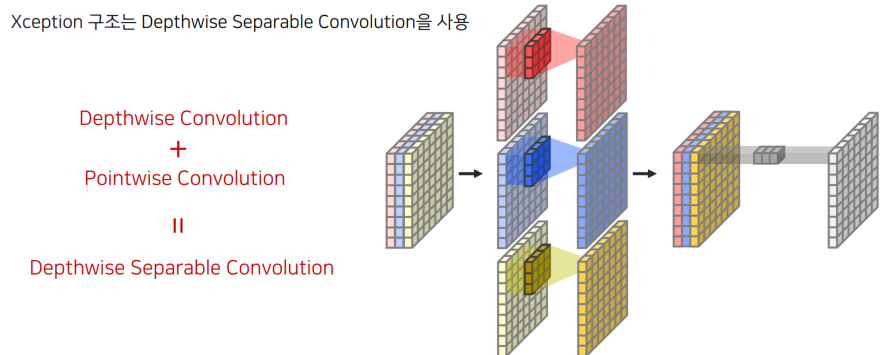
-
Depthwise Convolution :각 채널마다 다른 filter를 사용하여 convolution 연산 후 결합
-
Pointwise Convolution := 1x1 Convolution
import torch
import torch.nn as nn
# 입력 및 출력 채널 수 설정
in_ch, out_ch = 128, 128
# 입력 텐서 예시
inputs = torch.randn(1, in_ch, 64, 64) # 배치 크기 1, 채널 수 in_ch, 64x64 크기
# 첫 번째 Depthwise Convolution
outputs = nn.Conv2d(in_channels=in_ch, out_channels=in_ch, kernel_size=3, groups=in_ch)(inputs)
# Batch Normalization
outputs = nn.BatchNorm2d(num_features=in_ch)(outputs)
# Pointwise Convolution
outputs = nn.Conv2d(in_channels=in_ch, out_channels=out_ch, kernel_size=1)(outputs)
print(outputs.shape) # 결과 텐서의 크기 출력
Xception 구조
Xception 구조는 3개의 flow(entry, middle, exit) 로 구성됨
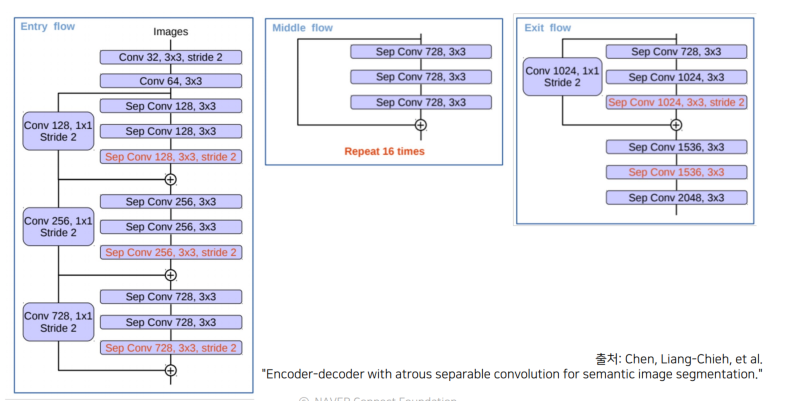
Entry 구현
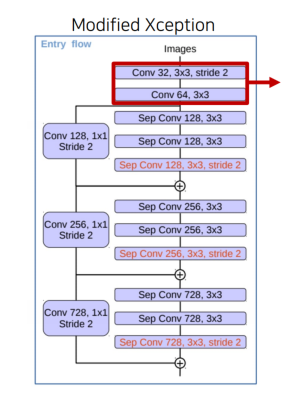
import torch
import torch.nn as nn
# Sequential 모델 생성
model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
# 예시 입력 텐서 (배치 크기 1, 채널 3, 64x64 이미지 크기)
inputs = torch.randn(1, 3, 64, 64)
# 모델 실행
outputs = model(inputs)
print(outputs.shape) # 결과 텐서의 크기 출력
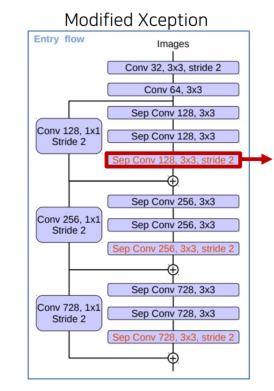
import torch
import torch.nn as nn
# Depthwise Separable Convolution 정의
class DepthwiseSeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, dilation=1):
super(DepthwiseSeparableConv2d, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size, stride=stride,
padding=dilation, dilation=dilation, groups=in_channels)
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x
# EntryFlowBlock01 정의
class EntryFlowBlock01(nn.Module):
def __init__(self):
super(EntryFlowBlock01, self).__init__()
self.block = nn.Sequential(
nn.ReLU(),
DepthwiseSeparableConv2d(128, 128, kernel_size=3, stride=1, dilation=1),
nn.BatchNorm2d(128),
nn.ReLU(),
DepthwiseSeparableConv2d(128, 128, kernel_size=3, stride=1, dilation=1),
nn.BatchNorm2d(128),
nn.ReLU(),
DepthwiseSeparableConv2d(128, 128, kernel_size=3, stride=2, dilation=1),
nn.BatchNorm2d(128),
)
self.skip = nn.Sequential(
nn.Conv2d(128, 128, kernel_size=1, stride=2),
nn.BatchNorm2d(128),
)
def forward(self, inputs):
outputs = self.block(inputs)
skip_outputs = self.skip(inputs)
return outputs + skip_outputs
# 예시 입력
inputs = torch.randn(1, 128, 64, 64) # 배치 크기 1, 채널 128, 64x64 크기
# 모델 초기화 및 실행
model = EntryFlowBlock01()
outputs = model(inputs)
print(outputs.shape) # 결과 텐서의 크기 출력
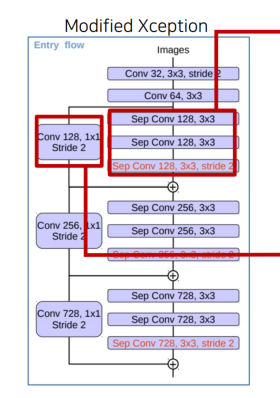
# EntryFlowBlock01 정의
class EntryFlowBlock01(nn.Module):
def __init__(self):
super(EntryFlowBlock01, self).__init__()
self.block = nn.Sequential(
nn.ReLU(),
DepthwiseSeparableConv2d(128, 128, kernel_size=3, stride=1, dilation=1),
nn.BatchNorm2d(128),
nn.ReLU(),
DepthwiseSeparableConv2d(128, 128, kernel_size=3, stride=1, dilation=1),
nn.BatchNorm2d(128),
nn.ReLU(),
DepthwiseSeparableConv2d(128, 128, kernel_size=3, stride=2, dilation=1),
nn.BatchNorm2d(128),
)
self.skip = nn.Sequential(
nn.Conv2d(128, 128, kernel_size=1, stride=2),
nn.BatchNorm2d(128),
)
def forward(self, inputs):
outputs = self.block(inputs)
skip_outputs = self.skip(inputs)
return outputs + skip_outputsmiddle 구현
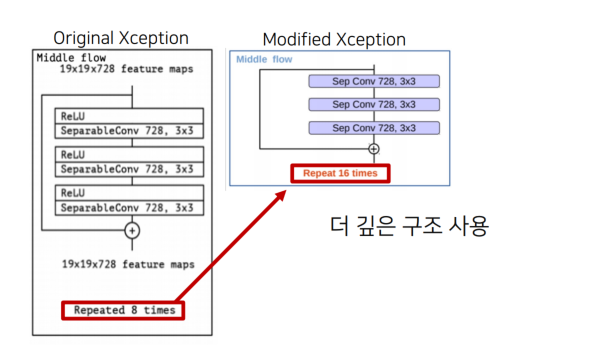
기존보다 더 깊은 구조 사용했다 정도
Exit 구현
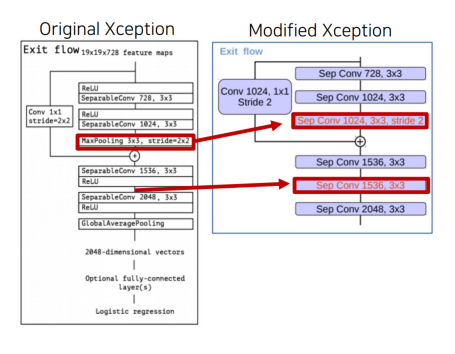
MaxPooling 연산을 Depthwise Separable convolution+ batchnorm+ ReLU 로 변경(Depthwise Separable Convolution 연산 추가)
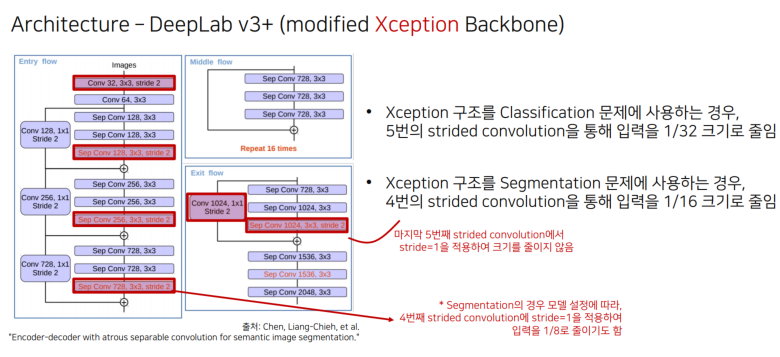
1.5 DeepLab v1부터 DeepLab v3+까지 정리
FCN -> DeepLabv1 -> Dilated Conv -> DeepLabv2 -> PSPNet -> DeepLabev3 -> Deeplabv3+
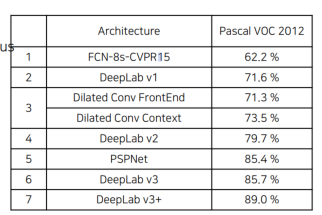
2. 결론
2.1 정리
- Encoder에서 spatial dimension의 축소로 인해 손실된 정보를 Decoder에서 점진적으로 복원한다.
- Depthwise Convolution은 채널마다 각기 다른 filter를 사용하여 convolution 연산 후 결합하는 것을 의미한다.
- Depthwise Separable Convolution은 Depthwise Convolution과 Pointwise Convolution을 합친 방법이다.
- PSPNet에서는 Inconspicuous Classes 현상을 해결하기 위해 작은 객체들도 global contextual information을 사용했습니다.
- PSPNET_FCN의 Confusion Categories 현상을 개선하기 위해 도입되었고, 카테고리간의 관계를 사용한다.
- PSPNET_Feature Map에 Average Pooling 적용해 sub-region을 생성한다.
- DeepLab v2는 성능 향상을 위해 더 깊은 ResNet-101 구조 사용하였습니다.
