1. EfficientUnet baseline
1.1 model불러오기
- library설치
pip install git+https://github.com/qubvel/segmentation_models.pytorch - Architectures 및 Encoders
# 라이브러리 임포트
import segmentation_models_pytorch as smp
import torch
# U-Net 모델 설정
model = smp.Unet(
encoder_name="efficientnet-b0", # 인코더 설정 (e.g., mobilenet_v2, efficientnet-b7)
encoder_weights="imagenet", # 사전 학습된 가중치 사용
in_channels=3, # 입력 채널 (RGB 이미지: 3)
classes=29 # 예측할 클래스 수
)
# 입력 데이터 생성 (예: 2048x2048 크기의 랜덤 RGB 이미지)
input = torch.rand([1, 3, 2048, 2048]) #각 값은 uniform distribution
# 모델을 통한 예측
output = model(input)
# 출력 모양 확인
print(output.shape)1.2 학습시키기
2. baseline 이후에 실험 해봐야할 사항들
2.1 주의해야할 사항들
1.디버깅 모드 :실험 환경이 잘 설정되었는지 체크하기 위한 과정
(1). 샘플링을 통해서 데이터 셋의 일부분만 추출
(2). Epoch를 1~2정도 설정하여 Loss가 감소하는지 확인
(3). step에 따라 Loss가 제대로 감소했다면 CFG.debug를 False로 바꿔서 전체 실험 진행
if CFG.debug:
CFG.epochs = 2
train = train.sample(frac=0.05, random_state=CFG.seed).reset_index(drop=True)2.시드 고정
모델의 성능을 비교할 때, 실험마다 성능이 달라지는 것을 방지하고 재생산해내기 위해 시드를 고정
import random
import os
import numpy as np
import torch
def set_seeds(seed=42):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
# 시드 설정 함수 호출
set_seeds()
from sklearn.model_selection import train_test_split
df_train, df_valid = train_test_split(label, test_size=0.2, random_state=0)3.실험기록
Network 종류, Augmentation 방법, Hyperparameter 등 성능에 영향을 주는 조건을 바꿔가며 실험을 진행한 후, 그 결과를 기록

4.실험은 한 번에 하나씩
실험을 할 때에는 하나의 조건만을 변경해가며 실험
ex)이전 실험 조건에서 Network 종류와 Augmentation 방법을 모두 변경하여 실험할 경우, 두 조건 중 어떤 조건이 성능 향상/하락에 영향을 주었는지 알기 어려움
5.팀원마다의 역할 분배?
팀원들간의 역할 분배를 어떻게 해야할 지?
• 하나의 베이스라인 코드를 기반으로 가장 좋은 솔루션을 만들기?
• 같은 코드에 실험을 서로 중복되지 않게 진행 !
• 독립적으로 베이스라인 코드를 만들어서 마지막에 앙상블?
• EDA / 코드 만들기 / 솔루션 조사 / 디스커션 조사 등 역할을 분배할 지?
2.2 Validation
Validation이 중요한 이유
- 제출을 하지 않아도 모델의 성능을 평가할 수 있다.
- Public 리더보드의 성능에 오버피팅 되지 않도록 도와준다.
1.HoldOut

1) 전체 데이터를 8:2로 분리해 Train data / Valid data로 분리
2) 80% Train data로 학습을, 20% Valid data로 검증하며 학습
3) 해당 모델로 Inference 진행
2.K-Fold
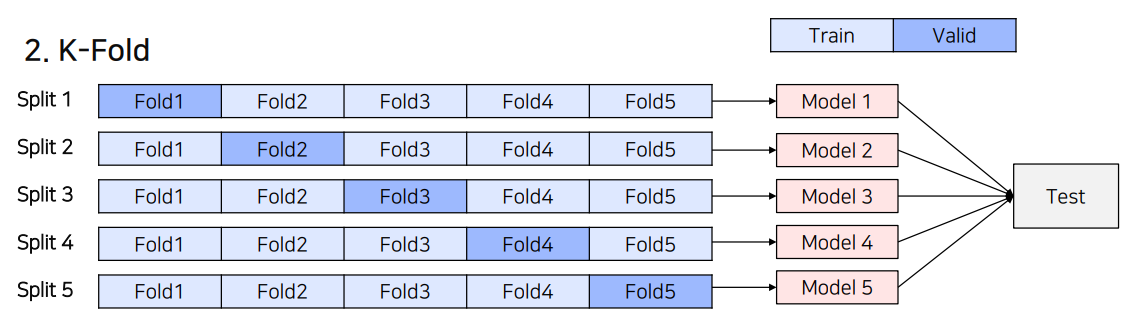
1) 전체 데이터를 8:2로 분리해 Train data / Valid data로 분리
- 단, Split 개념을 도입해 모든 데이터가 학습에 참여
2) Split 수만큼의 독립적인 모델을 학습하고 검증
3) 독립적인 모델로 Test 데이터에 대해 각각 Inference한 후, Ensemble
3.StratifiedK-Fold
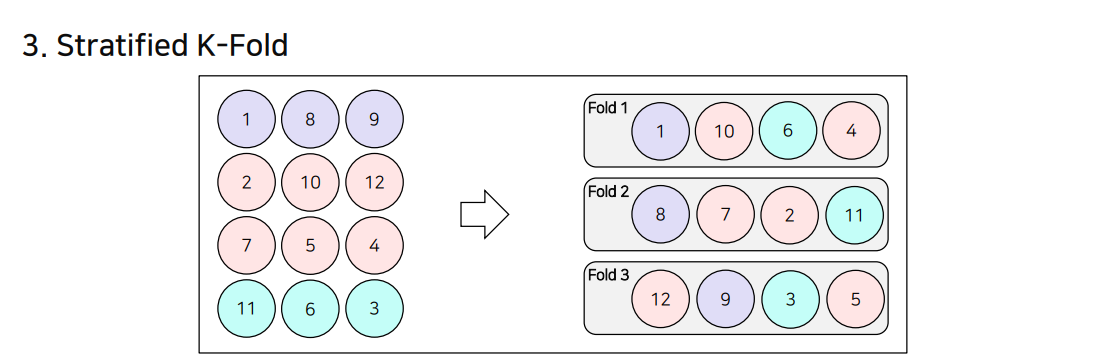
• 기존의 K Fold방식은 Class Distribution을 고려하지 못함
• 이를 고려해, Fold 마다 Class Distribution을 동일하게 Split하는 방식으로, Class가 Imbalance한 상황에서 좋음
4.GroupK-Fold

2.3 Augmentation
Augmentation을 하는 이유
• 데이터 수를 증가
• Generalization이 강화
• 성능이 향상
• Class Imbalance 문제를 해결
Rotation/Flip/Transpose

Augmentation Library- Torchvision.transforms
import torch
from torchvision import transforms
transform = transforms.Compose([
transforms.Resize((256, 256)), # 이미지 크기를 256x256으로 조정
transforms.RandomResizedCrop(224), # 랜덤으로 224x224 크기로 자르기
transforms.RandomHorizontalFlip(), # 이미지를 좌우로 랜덤 플립
transforms.ToTensor(), # 이미지를 Tensor 형태로 변환
transforms.Normalize(mean=[0.485, 0.456, 0.406], # 이미지 정규화 (평균)
std=[0.229, 0.224, 0.225]) # 이미지 정규화 (표준편차)
])
AugmentationLibrary-그 외
Fast AutoAugment
https://arxiv.org/abs/1905.00397
AutoAugment: Learning Augmentation Policies from Data
https://arxiv.org/abs/1805.09501
Albumentation 예시 - 자주 사용되는 방법
• Resize
• RandomRotate90
• Cutout
• VerticalFlip
• HorizontalFlip
• ShiftScaleRotate
• RandomResizedCrop
• Normalize
• Tensor
도메인에 맞는 Augmentation기법이 필요!
augmentation 을 했다고 하더라도 무조건 성능이 높아지는건 아니다.
ex) 자동차 번호판 인식한다고 했을때
rotation같은 것보다는 , 흐린경우-비내린경우 등등 날씨 상황에 따른 이미지블러를 train 시키는게 좋을것이다.

1.Cutout
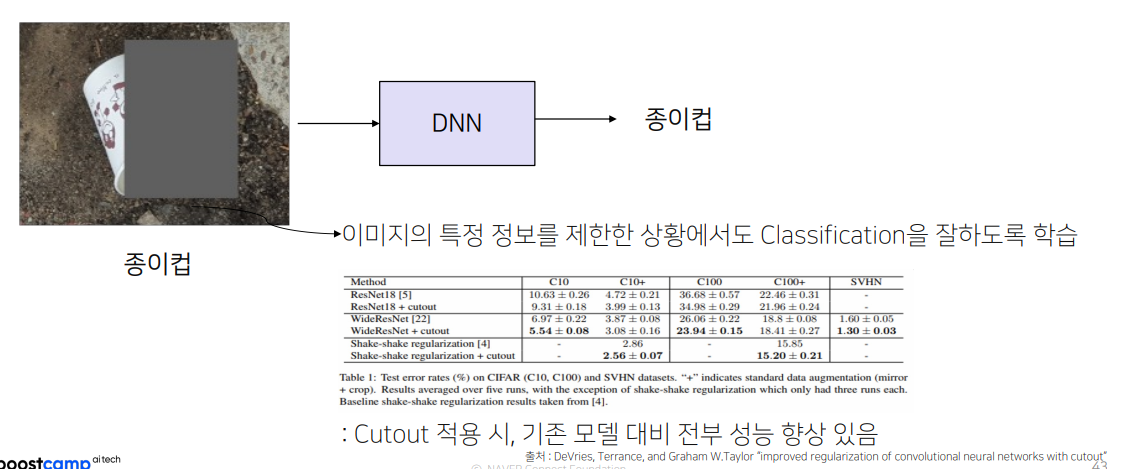
Cutout의 경우 Random하게 Box를 생성하기 때문에 사진마다 성능의 편차가 존재
• Fig 1의 경우 Object를 적절하게 가려 학습에 도움이 됨
• Fig 2의 경우 배경만 가려, 학습에 크게 도움이 되지 않음
• 심한 경우 Fig 3과 같이 Object를 전부 가리기도함

2.Gridmask
GridMask Data Augmentation
https://arxiv.org/abs/2001.04086
Cutout의 경우 객체의 중요 부분 혹은 Context information을 삭제할 수 있다는 단점을 해결하기 위해, 규칙성 있는 박스를 통해 Cutout하는 방안을 제시
import albumentations as A
transform = A.Compose([
A.Resize(224, 224), # 이미지를 224x224 크기로 조정
A.GridDropout(
ratio=0.2, # 드롭아웃 비율 (20% 드롭)
random_offset=True, # 드롭아웃 패턴 위치를 무작위로 변경
holes_number_x=4, # x축에 4개의 드롭아웃 구멍 생성
holes_number_y=4, # y축에 4개의 드롭아웃 구멍 생성
p=1.0 # 변환 적용 확률 (100%)
)
])
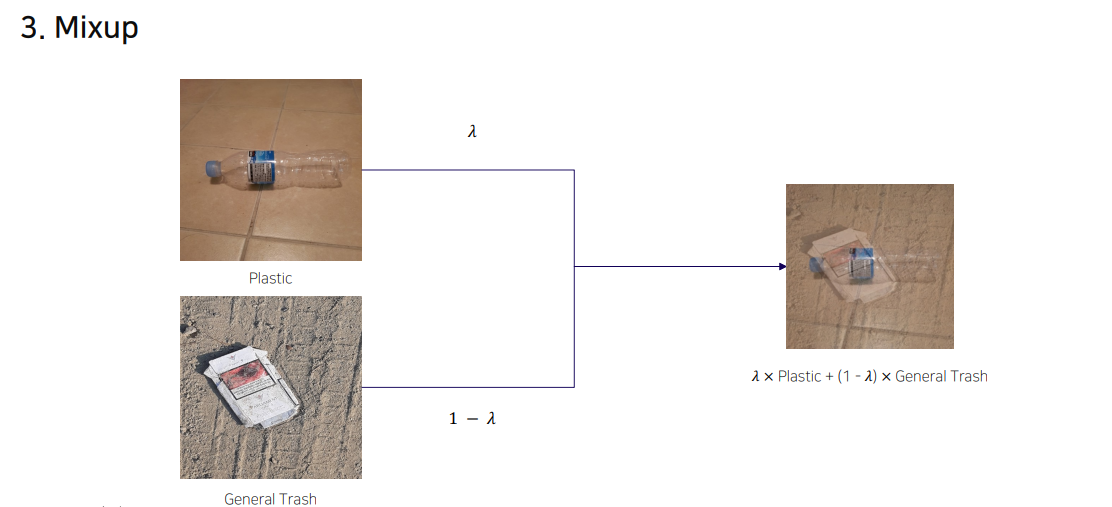
3.Mixup
두 장의 이미지를 섞는 것. 부산사람처럼(섞어 묵자~)
import numpy as np
alpha = 0.2 # Mixup의 alpha 파라미터 설정
for (img, target) in zip(dataloader):
# 두 개의 샘플을 선택하여 Mixup 수행
x1, y1 = img[0], target[0]
x2, y2 = img[1], target[1]
# Beta 분포에서 lambda 파라미터 샘플링
lambda_param = np.random.beta(alpha, alpha)
# Mixup으로 새로운 이미지와 레이블 생성
image = lambda_param * x1 + (1 - lambda_param) * x2
label = lambda_param * y1 + (1 - lambda_param) * y2
# 모델 학습 단계
optimizer.zero_grad()
out = net(image) # 모델 예측
loss = loss_fn(out, label) # 손실 계산
loss.backward() # 역전파
optimizer.step() # 최적화
4.Cutmix
두개의 이미지를 붙임.


import numpy as np
def rand_bbox(size, lam):
H = size[2] # 이미지 높이
W = size[3] # 이미지 너비
# 바운딩 박스의 크기 계산
cut_rat = np.sqrt(1. - lam) # lambda 값으로 비율 결정
cut_w = np.int(W * cut_rat) # 바운딩 박스 너비
cut_h = np.int(H * cut_rat) # 바운딩 박스 높이
# 바운딩 박스 중심 좌표 계산 (uniform하게 무작위 선택)
cx = np.random.randint(W)
cy = np.random.randint(H)
# 바운딩 박스의 좌상단(x1, y1)과 우하단(x2, y2) 좌표 계산
bbx1 = np.clip(cx - cut_w // 2, 0, W) # x1 좌표 (0 ~ W 범위)
bby1 = np.clip(cy - cut_h // 2, 0, H) # y1 좌표 (0 ~ H 범위)
bbx2 = np.clip(cx + cut_w // 2, 0, W) # x2 좌표 (0 ~ W 범위)
bby2 = np.clip(cy + cut_h // 2, 0, H) # y2 좌표 (0 ~ H 범위)
return bbx1, bby1, bbx2, bby2
import numpy as np
import torch
# CutMix 파라미터
beta = 1.0 # beta 파라미터 설정
lam = np.random.beta(beta, beta) # beta 분포에서 lambda 샘플링
# 데이터셋에서 무작위로 샘플 섞기
rand_index = torch.randperm(input.size()[0]).cuda()
target_a = target # 원래 타겟
target_b = target[rand_index] # 무작위로 섞인 타겟
# 무작위 바운딩 박스 생성
bbx1, bby1, bbx2, bby2 = rand_bbox(input.size(), lam)
input[:, :, bbx1:bbx2, bby1:bby2] = input[rand_index, :, bbx1:bbx2, bby1:bby2]
# lambda 값 조정하여 정확한 픽셀 비율 계산
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (input.size()[-1] * input.size()[-2]))
# 모델 출력 및 손실 계산
output = model(input)
loss = criterion(output, target_a) * lam + criterion(output, target_b) * (1. - lam)
CutMix 라이브러리를 사용해서 할 수도 있다.
from cutmix.cutmix import CutMix
from cutmix.utils import CutMixCrossEntropyLoss
from torch.utils.data import DataLoader
# CIFAR 데이터셋을 불러오는 사용자 정의 클래스
dataset = CifarDataset(data=df_train, train=True, transform=train_transform)
# CutMix 적용
dataset = CutMix(dataset, num_class=10, beta=1.0, prob=0.5, num_mix=2)
# 데이터 로더 설정
loader = DataLoader(dataset, batch_size=32, shuffle=True,
num_workers=8, pin_memory=True, drop_last=True)
# CutMix용 손실 함수 설정
criterion = CutMixCrossEntropyLoss(True)
# 학습 루프
for _ in range(num_epoch):
for input, target in loader:
output = model(input) # 모델에 입력
loss = criterion(output, target) # 손실 계산
# 역전파와 최적화 단계
loss.backward()
optimizer.step()
optimizer.zero_grad()
5.SnapMix
https://arxiv.org/abs/2012.04846
CAM(Class Activation Map)을 이용해 이미지 및 라벨을 mixing하는 방법
• 영역 크기만을 고려해 라벨을 생성했던 CutMix와 달리 영역의 의미적 중요도를 고려해 라벨을 생성
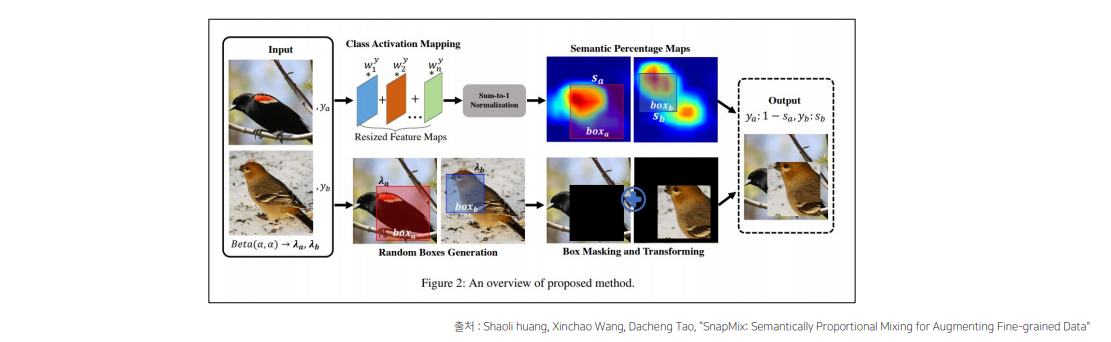
6.CropNonEmptyMaskIfExists
• object가 존재하는 부분을 중심으로 crop 할 수 있다면 model의 학습을 효율적으로 할 수 있음

2.4 SOTA Model
PaperwithCodes
https://paperswithcode.com/task/semantic-segmentation
2.5 Scheduler
Constant Learning Rate의 단점
Learning rate가 너무 작으면?
-> 학습 시간이 오래 소요되고, Local minima에 빠질 위험이 있음
Learning rate가 너무 크면?
-> loss가 발산하는 문제가 있음
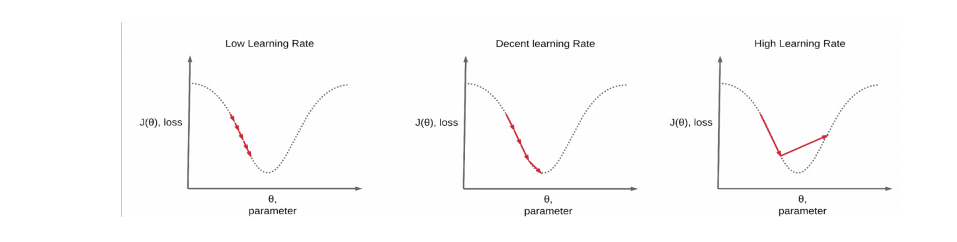
Learning Rate Schedules의 필요성
빠른 속도로 수렴 가능,높은 정확도를 가짐
1.CosineAnnealingLR
Learning rate의 최대값과 최소값을 정해, 그 범위의 학습율을 Cosine 함수를 이용해 스케줄링하는 방법-> 최대값과 최소값 사이에서 learning rate를 급격히 증가시켰다가, 감소시키기 때문에 saddle point, 정체 구간을 빠르게 벗어나게 함

2.ReduceLROnPlateau
metric의 성능이 향상되지 않을 때 learning rate를 조절하는 방법
ex) IoU가 감소한 경우 lr 조절.
3.GradualWarmup
학습을 시작할 때 매우 작은 learning rate로 출발해서 특정 값에 도달할 때까지 learning rate를 서서히 증가시키는 방법
• 이 방식을 사용하면 weight가 불안정한 초반에도 비교적 안정적으로 학습을 수행할 수 있음
• backbone 네트워크 사용시에 weight가 망가지는 것을
방지
2.6 HyperparameterTuning - Batch size
1.Gradient Accumulation
모델의 weight를 매 step 마다 업데이트하지 않고, 일정 step 동안 gradient를 누적한 다음 누적된gradient를 사용해 weight를 업데이트하는 방법
2.7 Optimizer/Loss
Adam,AdamW, AdamP, Radam
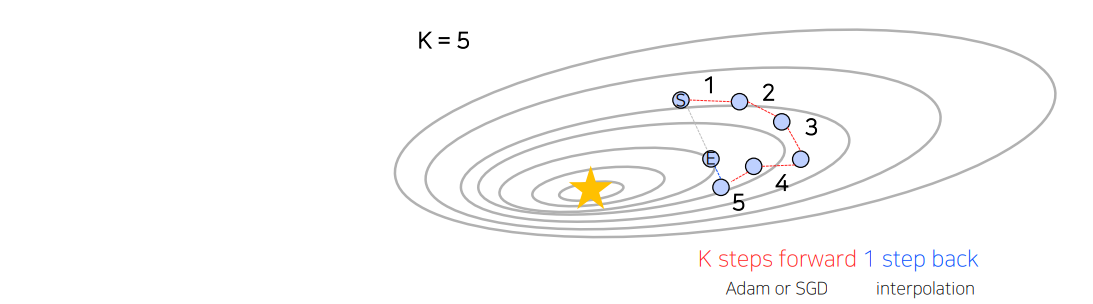
5.Lookahead optimizer
Adam이나 SGD를 통해 k번 업데이트 후, 처음 시작했던 point 방향으로 1 step back 후, 그 지점에서 다시 k번 업데이트를 시작하는 방법
• Adam이나 SGD로는 빠져나오기 힘든 Local minima를 빠져나올 수 있게 한다는 장점
6.Other Losses
