1.baseline이후에 실험 해봐야할 사항들 II
1.1 Ensemble
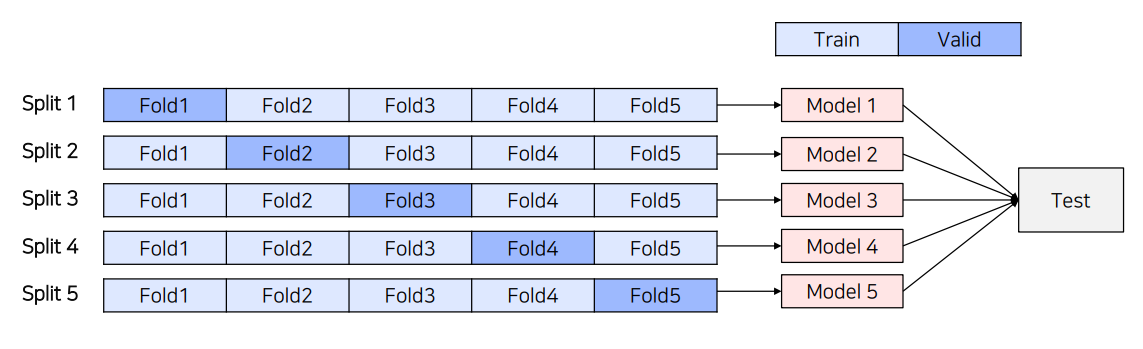
(1) 5-Fold Ensemble
5-Fold Cross validation을 통해 만들어진 5개의 모델을 Ensemble하는 방법
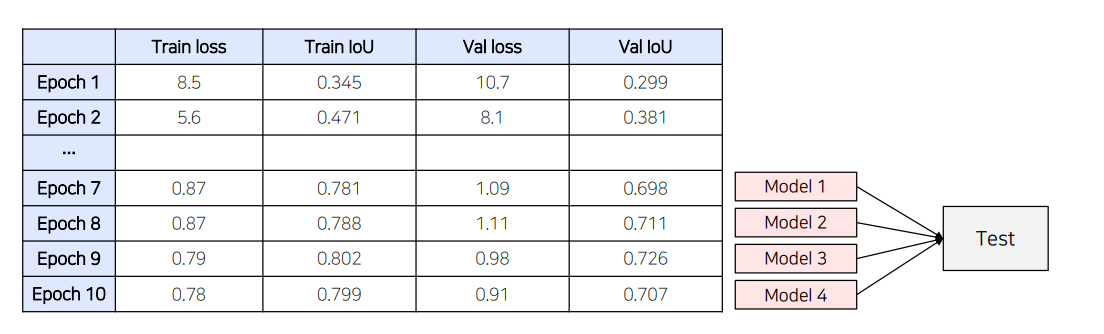
(2) Epoch Ensemble
학습을 완료한 후, 마지막부터 N개의 Weight를 이용해 예측한 후 결과를 Ensemble하는 방법
(3) SWA(StochasticWeightAveraging)
각 step마다 weight를 업데이트 시키는 SGD와 달리 일정 주기마다 weight를 평균 내는 방법
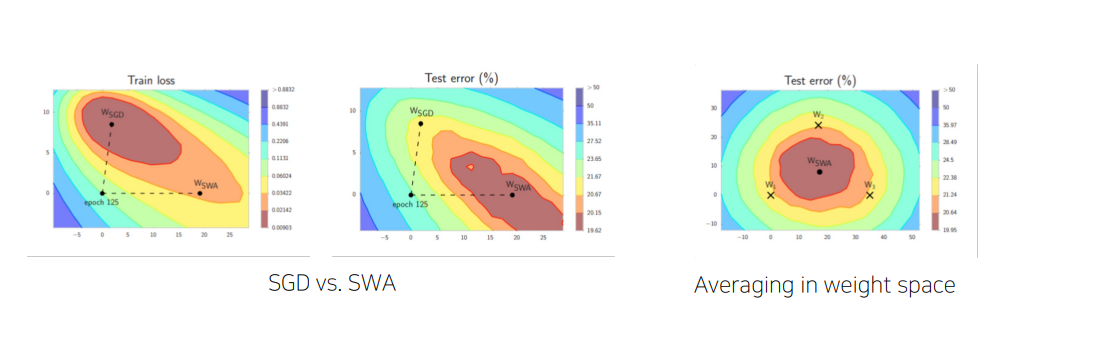
-> 일반화하는데는 SGD보다 SWA가 더 낫다.

평균 업데이트: 주기 c마다 현재 모델의 가중치를 에 포함하여 평균을 계산하고 업데이트합니다.
BatchNorm 통계 계산: 최종 SWA 가중치로 Batch Normalization 통계를 다시 계산하여 안정적인 성능을 보장합니다.
from torch.optim.swa_utils import AveragedModel, SWALR
from torch.optim.lr_scheduler import CosineAnnealingLR
# 기본 설정
loader, optimizer, model, loss_fn = ... # 데이터 로더, 옵티마이저, 모델, 손실 함수 정의
# SWA 설정
swa_model = AveragedModel(model) # SWA 모델 생성
scheduler = CosineAnnealingLR(optimizer, T_max=100) # 기본 학습률 스케줄러
swa_start = 5 # SWA 시작 에포크
swa_scheduler = SWALR(optimizer, swa_lr=0.05) # SWA 학습률 스케줄러
# 학습 루프
for epoch in range(100):
for input, target in loader:
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
# SWA 시작 에포크 이후부터 SWA 모델 업데이트 및 학습률 스케줄링
if epoch > swa_start:
swa_model.update_parameters(model)
swa_scheduler.step()
else:
scheduler.step()
# SWA 모델에서 BatchNorm 통계 업데이트
torch.optim.swa_utils.update_bn(loader, swa_model)
# 테스트 데이터에서 SWA 모델 사용
preds = swa_model(test_input)
(4) SeedEnsemble
Random한 요소를 결정짓는 Seed만 바꿔가며 여러 모델을 학습시킨 후 Ensemble하는 방법
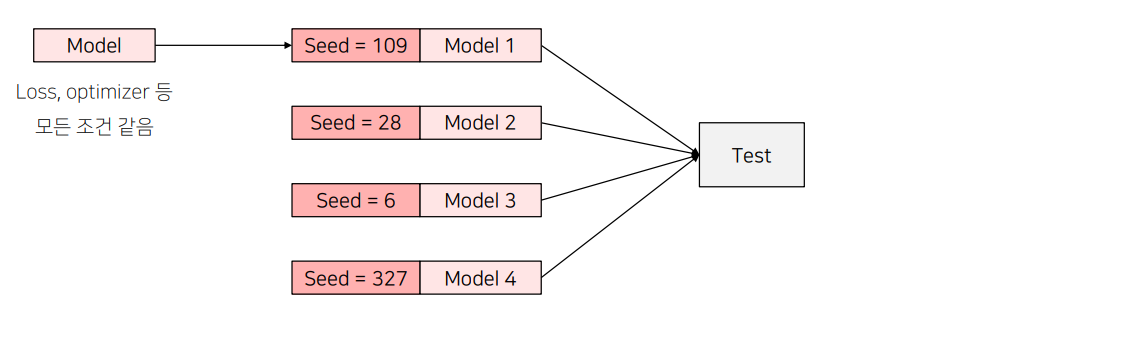
seed 만 바꿔서 앙상블 ㅋㅋㅋ
(5) Resize Ensemble
Input 이미지의 Size를 다르게 학습해 Ensemble하는 방법
객체크기에 따라서 앙상블을 하였기 때문에, 객체크기 시너지를 기대해 볼 수 있다.
(6) TTA(Test time augmentation)
Test set으로 모델의 성능을 테스트할 때, augmentation을 수행하는 방법
• 원본 이미지와 함께 augmentation을 거친 N장의 이미지를 모델에 입력하고, 각각의 결과를 평균
inference 에 대한 inference를 수행.즉, 결과 평균화: 각 이미지에 대한 예측 결과를 평균하여 최종 예측으로 사용
import torch
import torchvision.transforms as transforms
from PIL import Image
# TTA를 위한 증강 설정
tta_transforms = [
transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()]), # 원본 크기
transforms.Compose([transforms.Resize((224, 224)), transforms.RandomHorizontalFlip(1.0), transforms.ToTensor()]), # 좌우 반전
transforms.Compose([transforms.Resize((224, 224)), transforms.ColorJitter(brightness=0.5), transforms.ToTensor()]), # 밝기 조절
transforms.Compose([transforms.Resize((224, 224)), transforms.RandomRotation(15), transforms.ToTensor()]) # 15도 회전
]
def tta_inference(model, image_path, tta_transforms):
image = Image.open(image_path).convert("RGB")
predictions = []
# TTA를 수행하면서 각 증강된 이미지에 대해 예측
with torch.no_grad():
for transform in tta_transforms:
augmented_image = transform(image).unsqueeze(0) # 배치 차원을 추가
output = model(augmented_image) # 모델 예측
predictions.append(output)
# 예측 결과를 평균화하여 최종 예측 도출
final_prediction = torch.mean(torch.stack(predictions), dim=0)
return final_prediction
# 예시로 모델을 정의하고 TTA 수행
model = ... # 미리 학습된 모델 불러오기
model.eval() # 모델을 평가 모드로 전환
image_path = 'test_image.jpg' # 테스트 이미지 경로
final_prediction = tta_inference(model, image_path, tta_transforms)
print(final_prediction)
import ttach as tta
# TTA를 위한 다양한 증강 설정
transforms = tta.Compose(
[
tta.HorizontalFlip(), # 좌우 반전
tta.Rotate90(angles=[0, 180]), # 0도와 180도 회전
tta.Scale(scales=[1, 2, 4]) # 스케일 변경 (1배, 2배, 4배)
]
)
# TTA Wrapper를 사용하여 모델에 TTA 적용
tta_model = tta.SegmentationTTAWrapper(model, transforms)
# 예측 수행
masks = tta_model(images) # 증강된 이미지에 대한 예측 결과
- Compose 오브젝트는 입력으로 주어진 TTA들을 조합해서여러가지 TTAcase설정( 2 x2x3=12가지 TTA case)
- SegmentationTTAWrapper object는 model과 Compose 의결과물을 입력으로 받아 한 이미지에 대해 12 가지의 TTA를 적용하고 결과물을 평균 내어 return
1.2 PseudoLabeling
PseudoLabeling
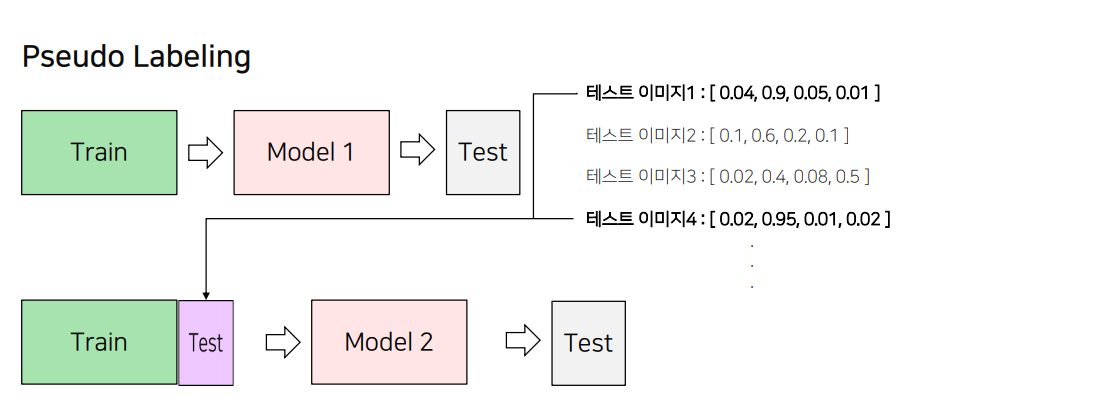
1) 모델 학습을 진행 ->
2) 성능이 가장 좋은 모델에 대해 Test 데이터셋에 대한 예측을 진행
• 이 때 Softmax를 취한 확률값이나 Softmax를 취하기 전의 값, torch.max를 취하기 전의 값을 예측
• Test 데이터셋은 Model 1의 예측값이 threshold (예 : 0.9) 보다 높은 결과물을 이용
3) 2단계에서 예측한 Test 데이터셋과 Train 데이터셋을 결합해 새롭게 학습을 진행
4) 3단계에서 학습한 모델로 Test 데이터셋을 예측
1.3 외부 데이터 활용
1.4 그외
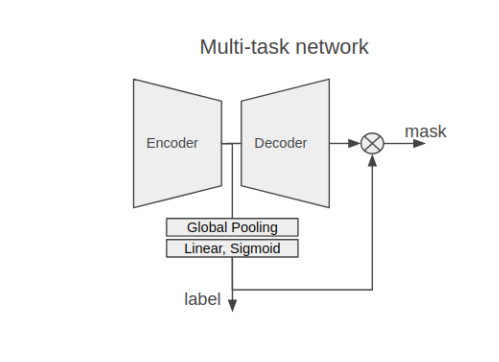
Classification결과를 활용하는 방법
EncoderHead마지막단에 ClassificationHead를 달아서 같이 활용 (Unet3+에서 활용)
한정된 시간을 효율적으로 사용
• 코드를 돌리는 시간에 다른 작업 진행
• 작은 샘플로 실험 코드가 문제 없는지 미리 확인
• 자는 시간, 쉬는 시간 등 GPU가 쉬지 않도록 미리 실험용 코드 작성
2. 대회에서 사용하는 기법들 소개
2.1 최근 딥러닝 이미지 대회의 Trend
Problem1
학습 이미지가 많고 큰 경우에는 네트워크를 한번 학습하는데 시간이 오래 걸려서 충분한 실험을 하지 못함
Solution1-1 Mixed- Precision Training of Deep Neural Networks
웨이트의 소수점 자리를 32에서 16으로 대체하여 배치를 키우는 방법
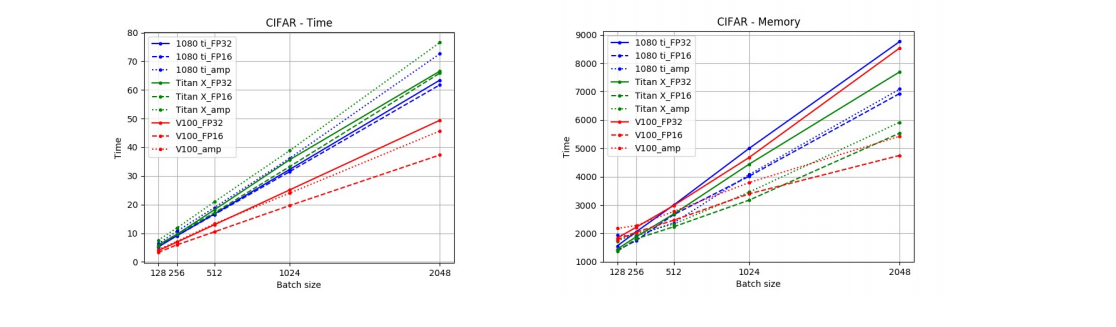
• torch.cuda.amp.autocast()를 이용하면 AMP를 간단하게 적용
use_amp = True # AMP 사용 여부 설정
# 모델, 옵티마이저, 스케일러 설정
net = make_model(in_size, out_size, num_layers)
opt = torch.optim.SGD(net.parameters(), lr=0.001)
scaler = torch.cuda.amp.GradScaler(enabled=use_amp) # AMP를 위한 GradScaler 생성(AMP 활용시 underflow 방지)
# 학습 루프
for epoch in range(epochs):
for input, target in zip(data, targets):
# AMP를 위한 autocast 사용
with torch.cuda.amp.autocast(enabled=use_amp):
output = net(input) # 모델 예측
loss = loss_fn(output, target) # 손실 계산
# 손실 스케일링 및 역전파
scaler.scale(loss).backward() # 스케일링된 손실로 역전파 수행(문제를 방지를 위해 GradScaler를 통해서 backward()와 step()을 호출)
scaler.step(opt) # 옵티마이저 업데이트
scaler.update() # 스케일러 업데이트
opt.zero_grad() # 그래디언트 초기화
Solution1-2 가벼운 상황으로 실험
• 일부 데이터 사용
• 단, LB 와 Validation Score 간의 어느 정도 상관관계가 있어야함!!
• K-Fold 보다는 단일 Fold로 검증
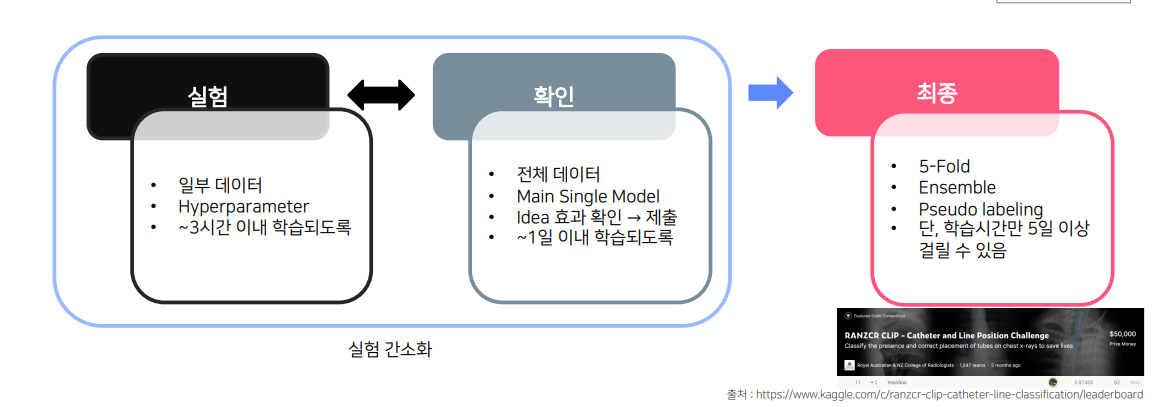
실험으로 내가 하는 것이 의미있는 것인지 보고(어떤게 의미있는 것인지 정리하는것임), 이후에 전체 데이터를 돌려서 의미가 있는 것인지 확인

팀원A는 resize해서 학습시키고 제출할때는 사이즈 올려서 제출
팀원B는 일부데이터만 확인하고 제출할때는 전체데이터 모두 학습해서 제출.

다양한 각도의 똑같은 헤어스타일은 접어두고, 다양한 헤어스타일에 대해서 샘플링.
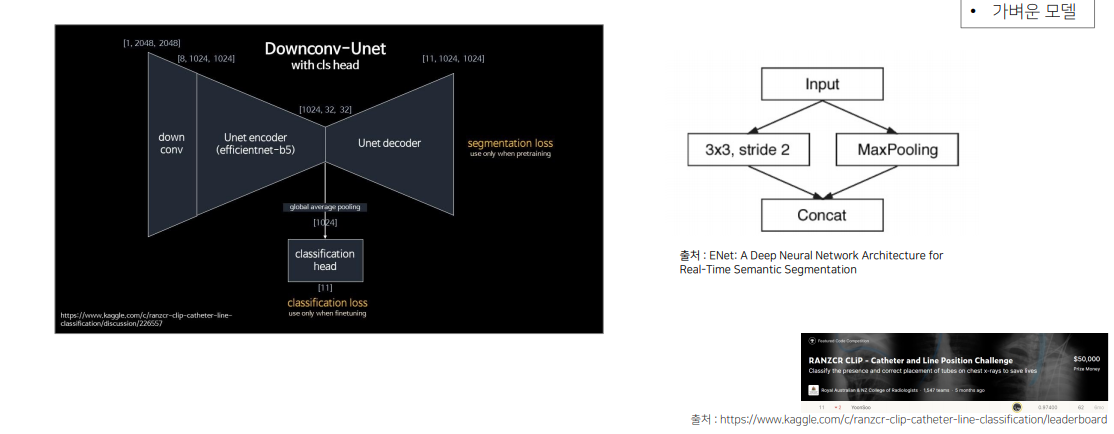
Solution1-3 가벼운 모델로 실험
Params가 적은 모델들로 실험하고 최종은 성능이 잘 나오는 모델로 확인
Problem2
아래와 같이 주어진 data인 Image의 크기가 매우 큰 경우 model이 학습하는 시간이 매우 오래 걸림
ex) 4032x3024x3 , 35000x24000x3
Solution2-1 Resize
주어진 data를 모두 resize시켜 학습 → test set에 대해 예측된 Mask를 원본 size로 복원
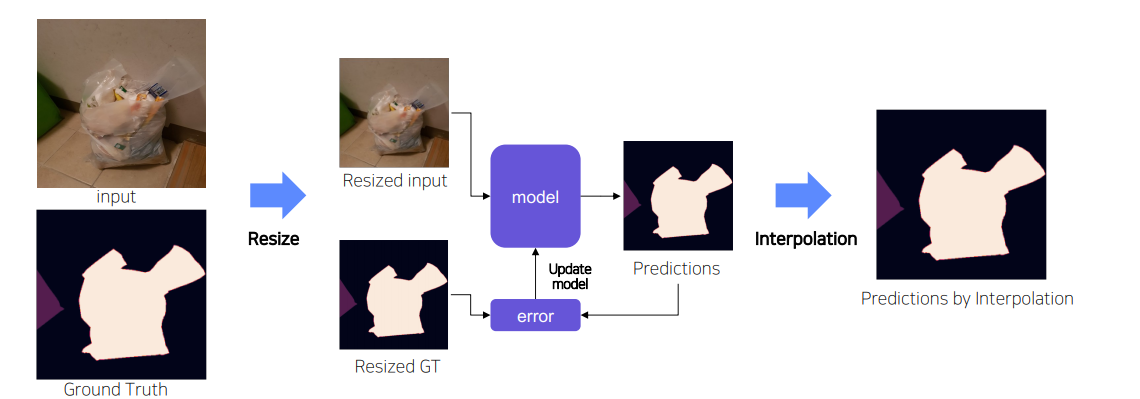
하지만 해상도가 줄어들 수 있음.
Solution2-2 SlidingWindow (Overlapping /Non-overlapping)
Imagesize가 크기 때문에 window단위로 잘라서 input으로 넣는 기법
Non-Overlapping
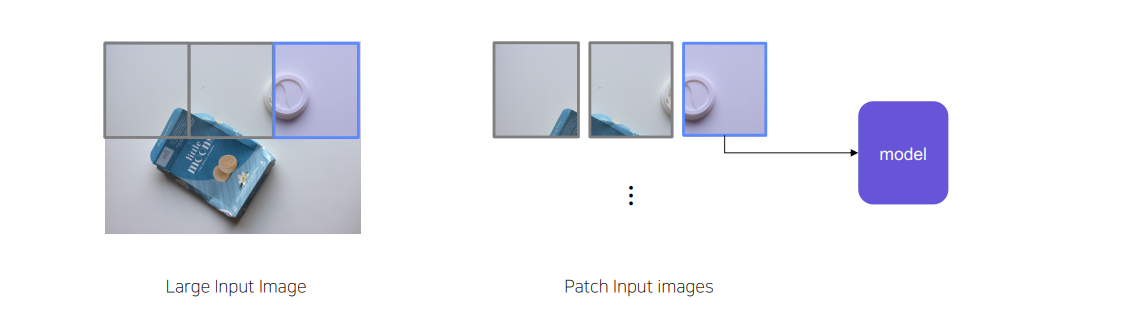
overlapping
단,Sliding Window 적용시 얼마의 window size 및 stride를 어떻게 설정하는지가 중요
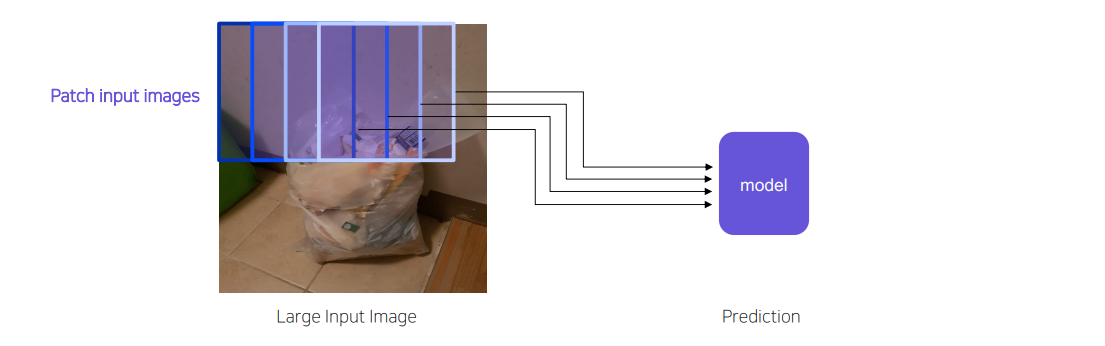
만약, :stride↓ → inputimage수 ↑,겹치는영역 ↑,다양한정보 ↑
하지만 stride가 작아지면, 학습데이터의 양이 많아지므로 학습데이터가 늘어나는 양에 비해서 성능의 차이는 적고 학습속도가 오래 걸린다.
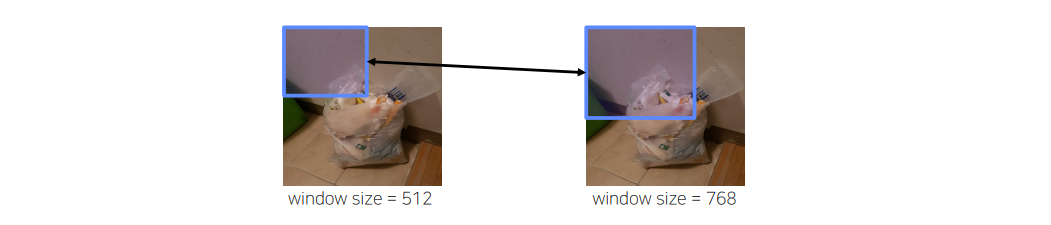
Solution2-3 그 외의 Tips1
일반적으로 train에 사용된 slidingwindow의 크기 (e.g.512)와 Inference에 사용되는 slidingwindow의 크기가 동일해야 한다고 생각하는 경우가 많음.
하지만,inputimage와 inference(test)image의 크기가 꼭 같을 필요 없음
Example:Inferenceimage의 slidingwindow의 크기 (e.g.768)가 커지면 더 많은 주변 정보를 통해서 prediction할 수 있으므로 성능의 정확도가 올라가는 경우가 경험적으로 많았음
Solution2-3 그 외의 Tips2
SlidingWindow를 적용하면 아래와 같이 유의미하지 않은 영역들이 잡히는 경우가 많음
-> “background”만 수집된 부분은 조금만 샘플링
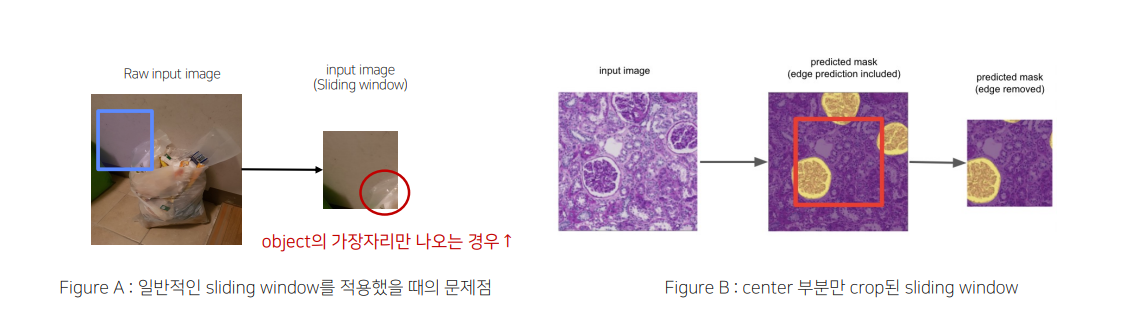
Solution2-3 그 외의 Tips3
SlidingWindow를 적용하면 [FigureA] 처럼 유의미하지 않은 영역들이 잡히는 경우가 많음
\해결 방안 :Prediction후에 object가 제대로 나온 center 부분만 Crop[FigureB]
Solution2-3그 외의 Tips4
전체 이미지에서의 유의미하지 않은 영역들이 잡히는 경우가 많음
-> 해결 방안 :segmentation/objectdetection을 통해서 object부분을 먼저 찾은 후 Crop
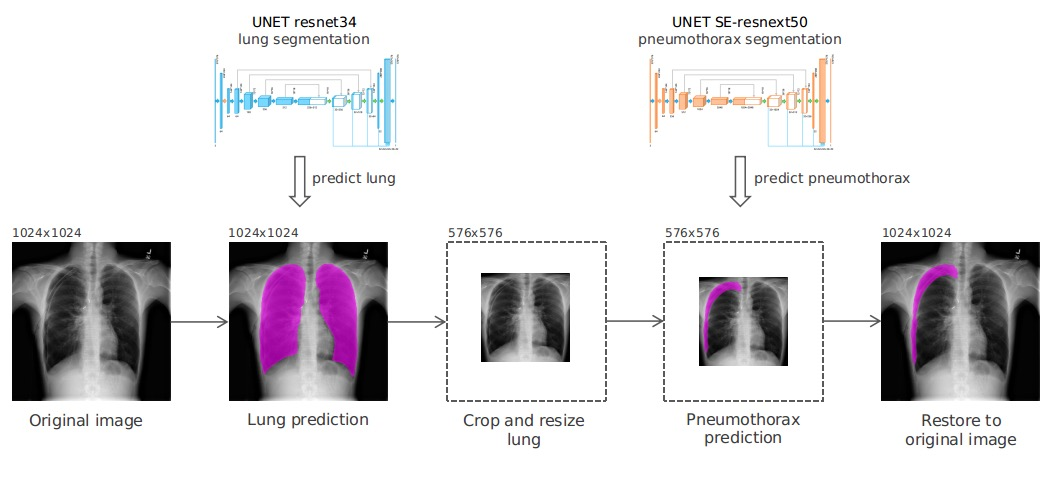
Task가 BinaryClassification인 경우
추가로 구분해야 할 class가 오직 2개인 BinaryCase와 같은 경우 threshold인
Probability를 0.5로 끊는게 굳이 정답은 아닐 수도 있음.

-> • Threshold(hyper-parameter)를 잘 search 하면서 실험 진행
2.2 model의 개선하기 위한 Tips
Output Image 확인
• 큰 object를 잘 예측할 수 있는지?

작은 object를 잘 예측할 수 있는지?

특정 class에 대해 잘 맞추는지?
->class가 많은 경우 각각의 class를 찾아서 확인하기 어렵기 때문에 validationset에서의 IoU 값 확인

2.3 LabelNoise가 있는 경우 Tips
실제 Segmentationtask를 진행하다 보면 label에 noise가 있는 경우 빈번함
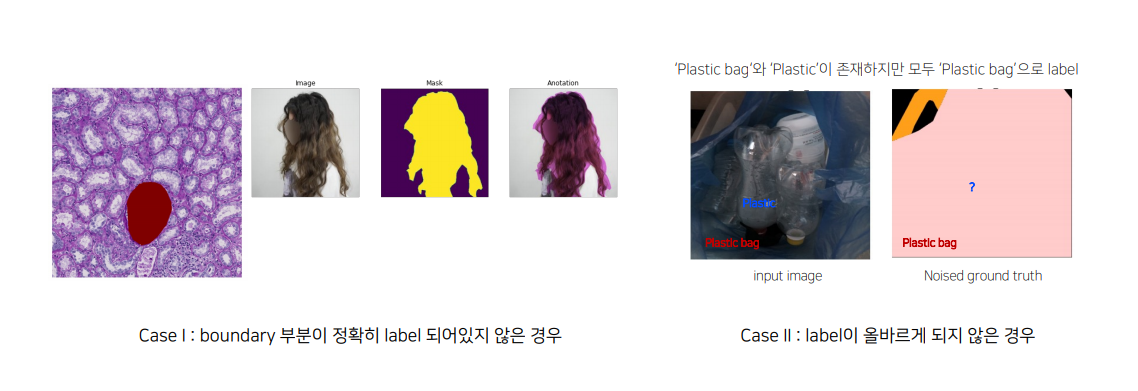
[LabelNoise가 발생하는 원인]
• 일반적으로 segmentation에서의 annotationtask는 픽셀 단위로 이루어지기 때문에 어려움이 존재
• annotationGuide가 주어지더라도 사람마다 기준이 다를 수 있음
• 사람이기 때문에 annotation실수도 존재
Label Noise를 해결하기 위한 관련 연구도 많이 진행
https://arxiv.org/abs/2007.15963
https://link.springer.com/chapter/10.1007/978-3-030-59710-8_70
https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/2062_ECCV_2020_paper.php
Solution1 Label Smoothing
where
- ): class
- : ground truth (hard target)
- : hyper-parameter
- : total classes
Solution2 Pseudo-labeling을 활용한 LabelPreprocessing
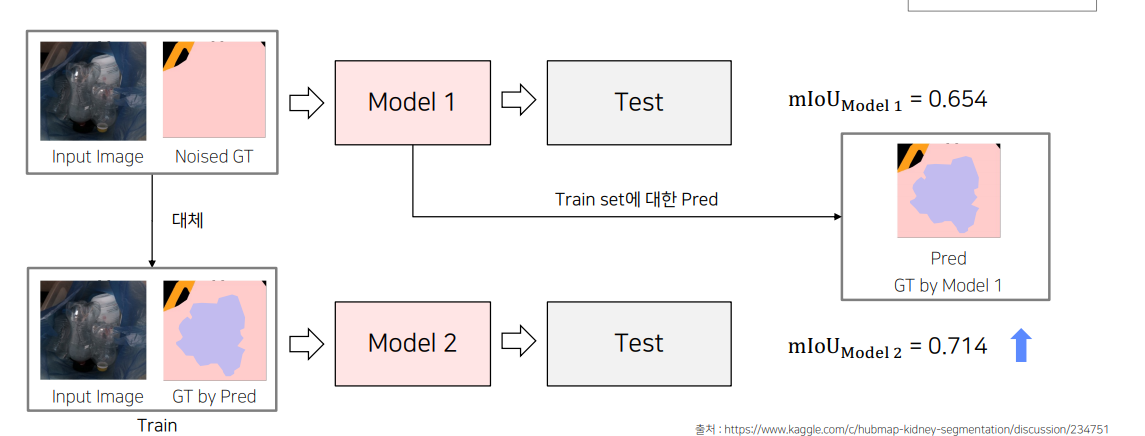
만약 dataset의 대부분의 GT가 제대로 된거라면, 위 이미지처럼 잘못된 GT에대해서 올바르게 예측할 확률이 더 높을 것이다.
그러면 이 예측한 이미지를 다시 train 에 넣어서 predict해서 성능을 높일 수 있다.
2.4 최근 딥러닝 이미지 대회의 평가 Trend
기존 평가 방식인 Accuracy,mIoU 이외에 다양한 평가 방식을 추가
• 학습 시간의 제한이 있는 경우
• 추론 시간의 제한이 있는 경우
• 속도 평가를 하는 경우
3. MonitoringTool
3.1 Weights & Biases
3.2 Visualization
학습된 model로부터 Inference결과를 web에서 확인할 수 있음
