1.Generative AI 개요 및 흐름
1.1 GenerativeAI:NLP
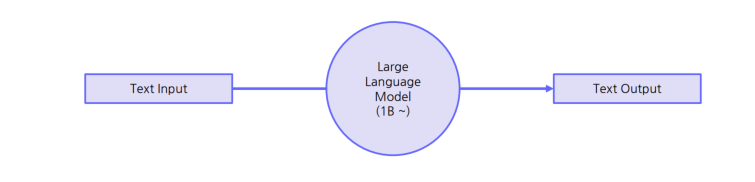
Large Language Model이란?
텍스트를 입력으로 받아 적절한 출력을 산출하는 언어모델
Large LanguageModel 발전현황
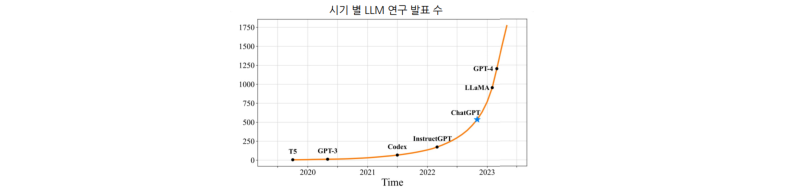
InstructGPT/ChatGPT출현 이후 활발히 연구 및 적용
NLP 모델 발전
① StatisticalLM : 통계 및 어휘 빈도 기반 방법론
ex) TF-IDF,BM25등
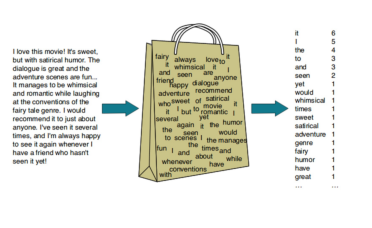
② NeuralLM: 단어의 의미를 고정된 크기의 벡터에 표현
ex) Word2Vec
③ PretrainedLM: 대량의 코퍼스로 사전학습된 언어모델 사전 학습 및 Finetune적용
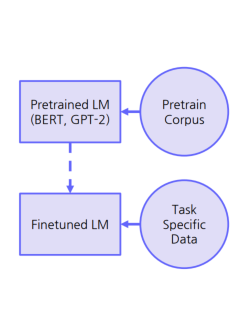
-> 사전학습을 통해 습득된 언어 정보 활용
④ LLM: 대형 언어 모델을 통한 다양한 태스크 수행
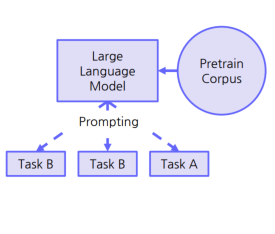
- 대량의 코퍼스를 많은 파라미터의 모델에 대해 사전학습 수행
- 일련의 Finetune과정을 통해 최종적인 모델 학습 종료
LargeLanguageModel장점
별도의 Finetune없이 다양한 태스크 수행 가능
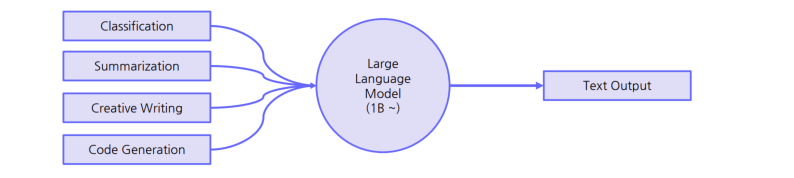
LargeLanguageModel활용 필요성
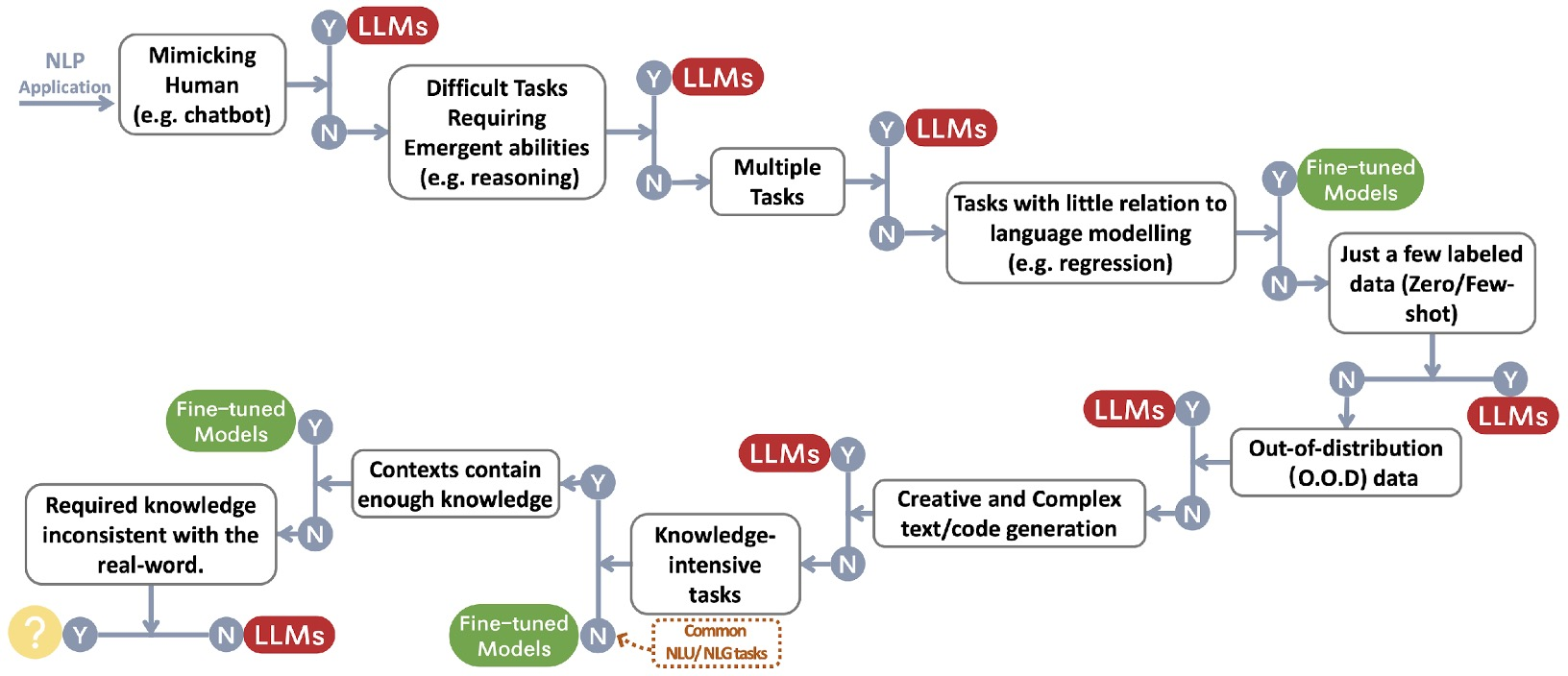
LM은 높은 비용으로 인해 특정 상황에서 사용됨
1.2 GenerativeAI : Vision
생성형 이미지 모델이란?
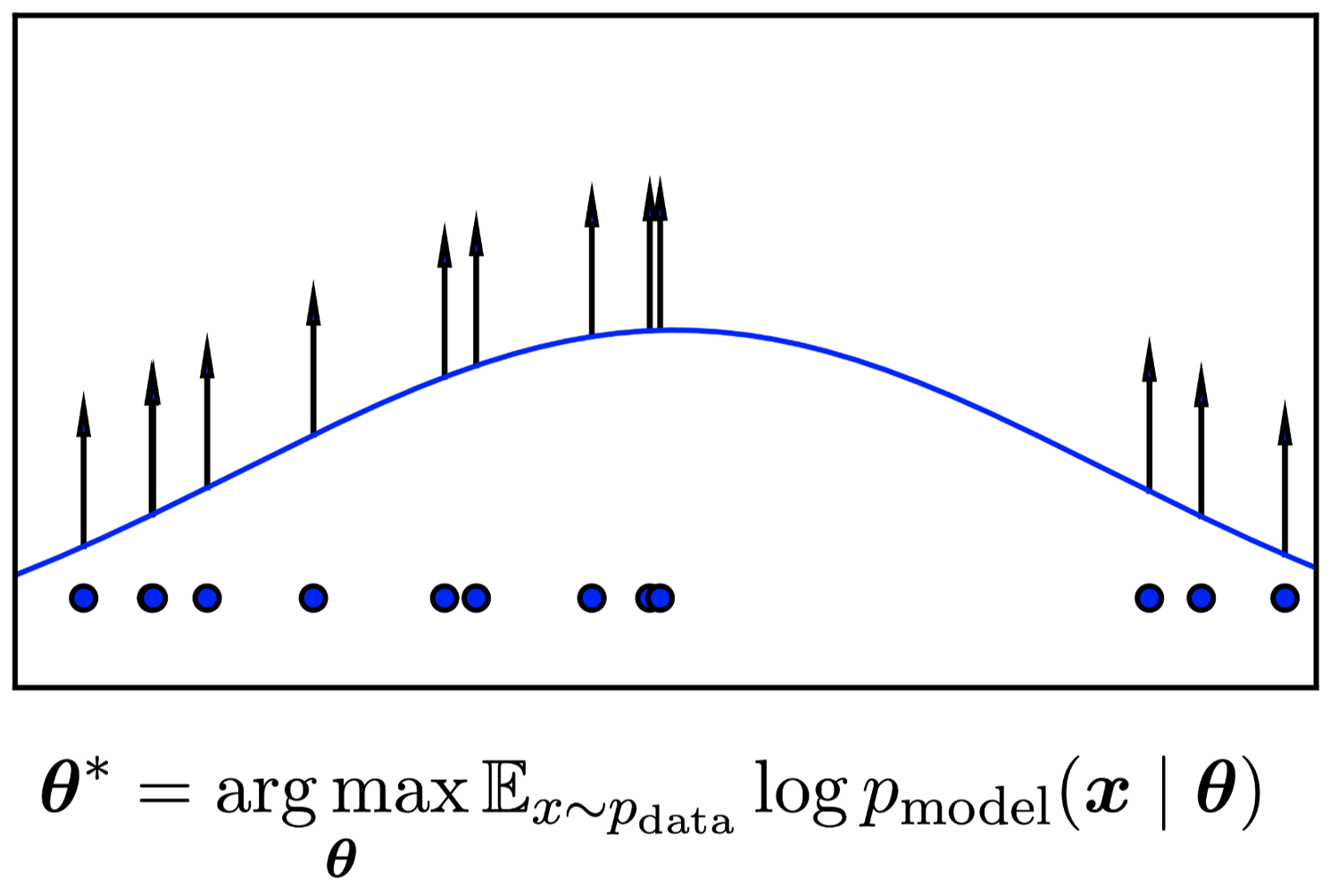
- 생성형 이미지 모델 은 특정 데이터의 분포를 기반으로 새로운 이미지를 생성하는 모델
- 생성형 이미지 모델의 학습 목표는 특정 데이터를 생성할 확률인 likelihood를 최대화하는 것
대표적인 생성형 이미지 모델 유형
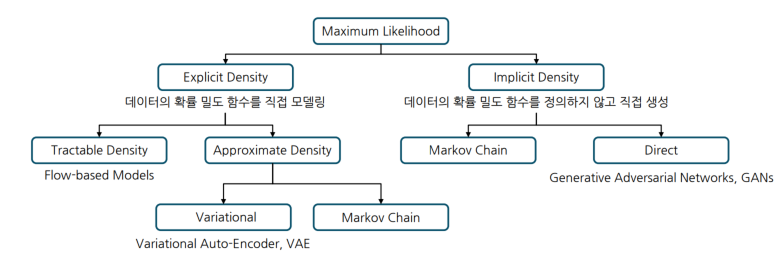
GAN,VAE,Flow-based model, Diffusion_model
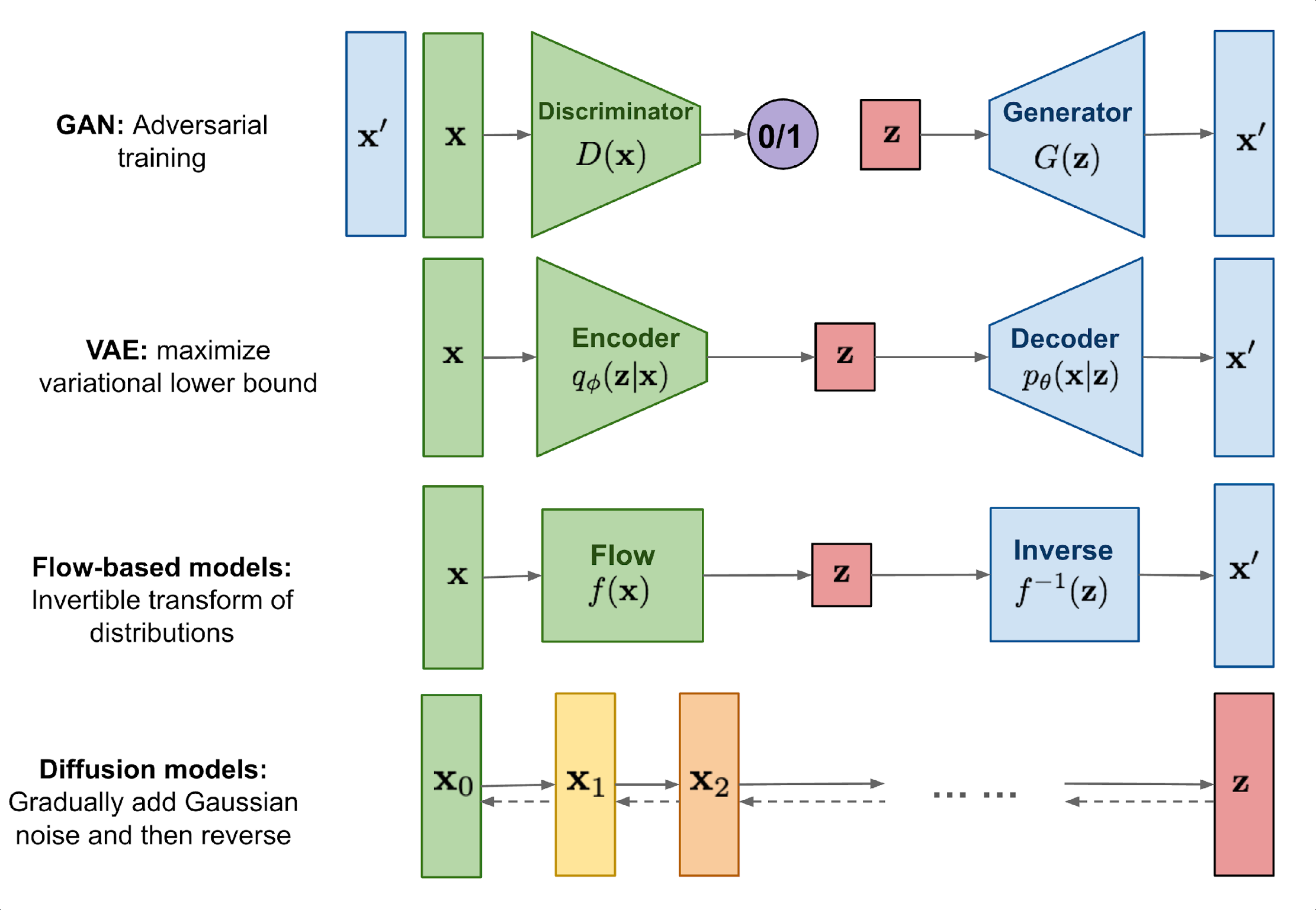
GenerativeAdversarialNetworks,GANs
판별자Discriminator와 생성자Generator를 적대적으로 학습하는 모델 구조
-> 논문리뷰 참고:https://velog.io/@leejken530/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B03-GANGenerative-Adversarial-Nets

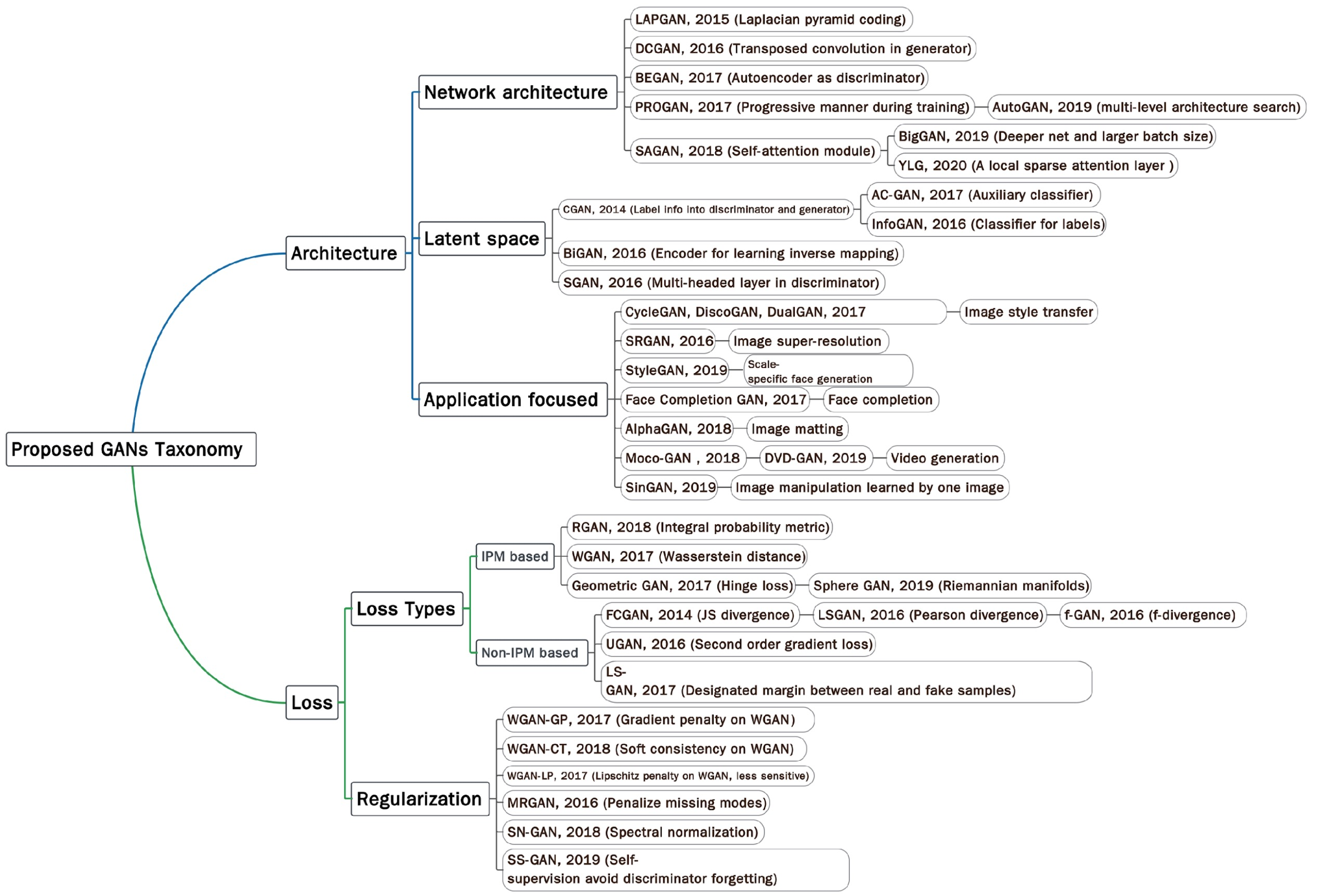
GAN연구방향
• Architecture구조적측면-> Networkarchitecture모델구조, Latentspace잠재공간, Applicationfocused활용관점
• Loss학습측면-> • LosstypesLoss유형,• Regularization정규화
Autoencoder,AE
Encoder와 Decoder로 구성되어 입력 이미지를 다시 복원하도록 학습하는 모델 구조

Encoder가 잠재변수 만들고 Decoder가 잠재변수 풀면서 원본이미지 생성하는 구조임.(잠재 변수의 분포를 정의하지 않음)
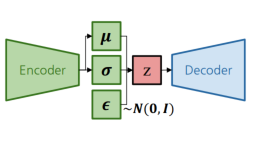
VariationalAutoencoder,VAE
AE가 잠재변수의 분포를 정의하는것에 반해서,VAE는 잠재변수의 분포를 정의하지 않음.
Flow-basedmodels
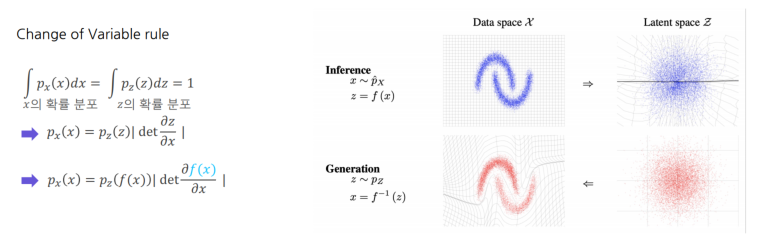
입력 이미지를 함수를 통해 잠재 공간으로 변환하고 역함수.를 통해 이미지를 복원하는 구조

즉, 변수변환을 기반으로 구성되어 있는 구조임

Diffusionmodels
입력 이미지를 forwardprocess를 통해 잠재 공간으로 변환하고 reverseprocess로 복원하는 구조
• Forwardprocess:점진적으로 가우시안 노이즈를 추가하여 잠재공간으로 매핑하는 과정
• Reverseprocess:forwardprocess에서 추가된 노이즈를 추정하여 제거하는 과정

생성형 이미지 모델 분야
Styletransfer
이미지의 스타일StyleImage을 다른 이미지ContentImage에 적용하는 방법
Inpainting
이미지의 손상된 부분이나 누락된 부분을 복원하거나 채우는 방법
Image editing
이미지를 변경하거나 개선하는 방법
Super-resolution
저해상도 이미지를 고해상도 이미지로 변환하는 방법
Multi-modal생성형 이미지 모델
Text-to-Image
• 텍스트를 입력으로 사용하여 이미지를 생성
Text-to-Video
텍스트를 입력으로 사용하여 비디오 생성
Image-to-Video
이미지와 prompt를 사용하여 비디오 생성
2.생성 모델 활용 사례
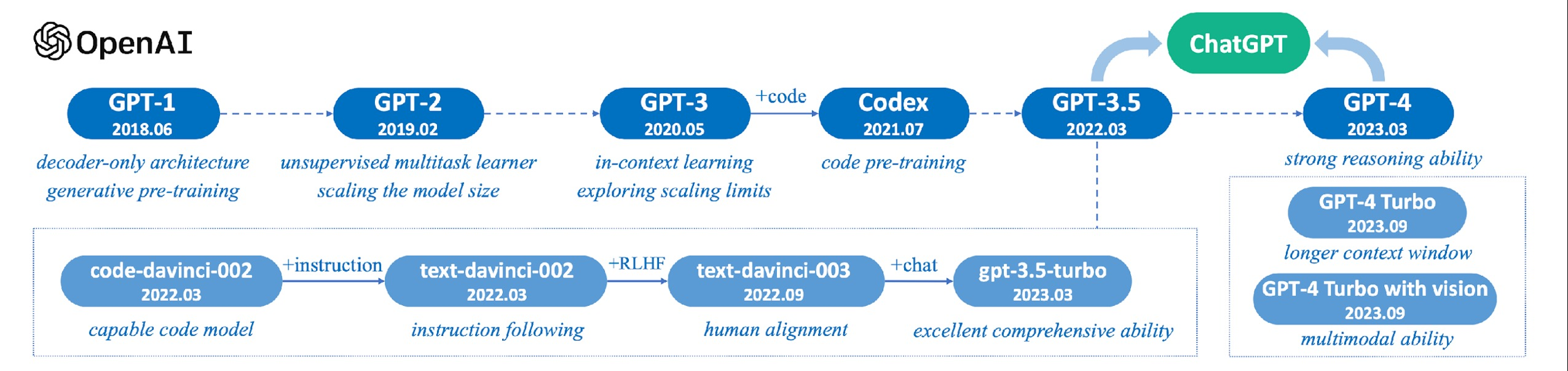
2.1 ChatGPT and GPT
2.2 DALL-E3 and StableDiffusion
3. 참고
- A Survey of Large Language Models
https://arxiv.org/abs/2303.18223 - Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy
https://arxiv.org/abs/1906.01529 - Diffusion Models: A Comprehensive Survey of Methods and Applications
https://arxiv.org/abs/2209.00796
