1. Large Language Model 기본
1.1 Large Language Model 개념
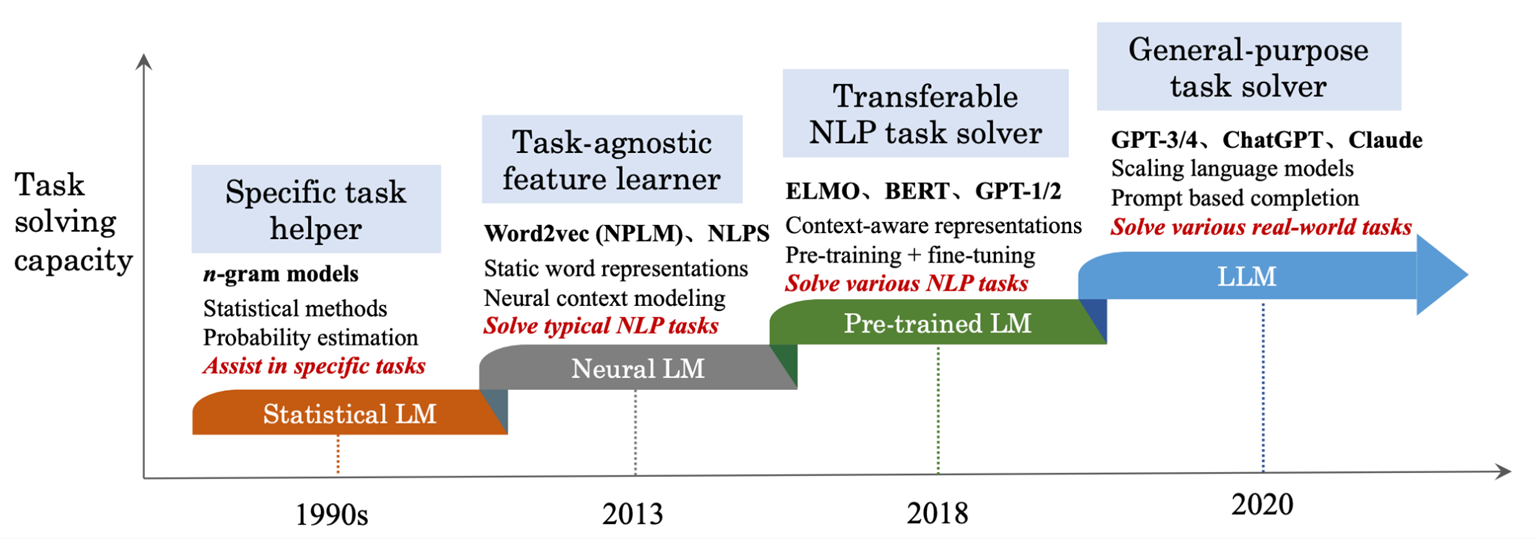
범용적인 태스크 수행이 가능한 Language Model
-> 사전학습 데이터 및 파라미터 수가 매우 큰 모델의 종합적 지칭
1.2 Model Architecture
Pretrained LM
Downstream 태스크 별 Finetune을 통해 목적 별 모델 구축
-> 하나의 모델을 사용해 하나의 태스크 해결
LLM
사전학습 및 Finetune을 통해 범용 목적 모델 구축
-> 하나의 모델을 사용해 다양한 태스크 해결
Zero/Few-Shot Learning
모델 추가 학습 X
- zero shot: 모델이 prompt만으로 태스크를 이해하여 수행
- Few shot learning: 모델이 prompt와 demonstration 를 통해 태스크를 이해하여 수행.
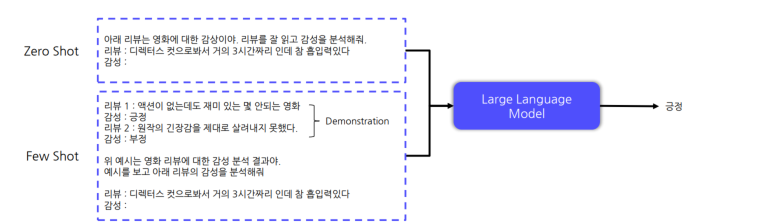
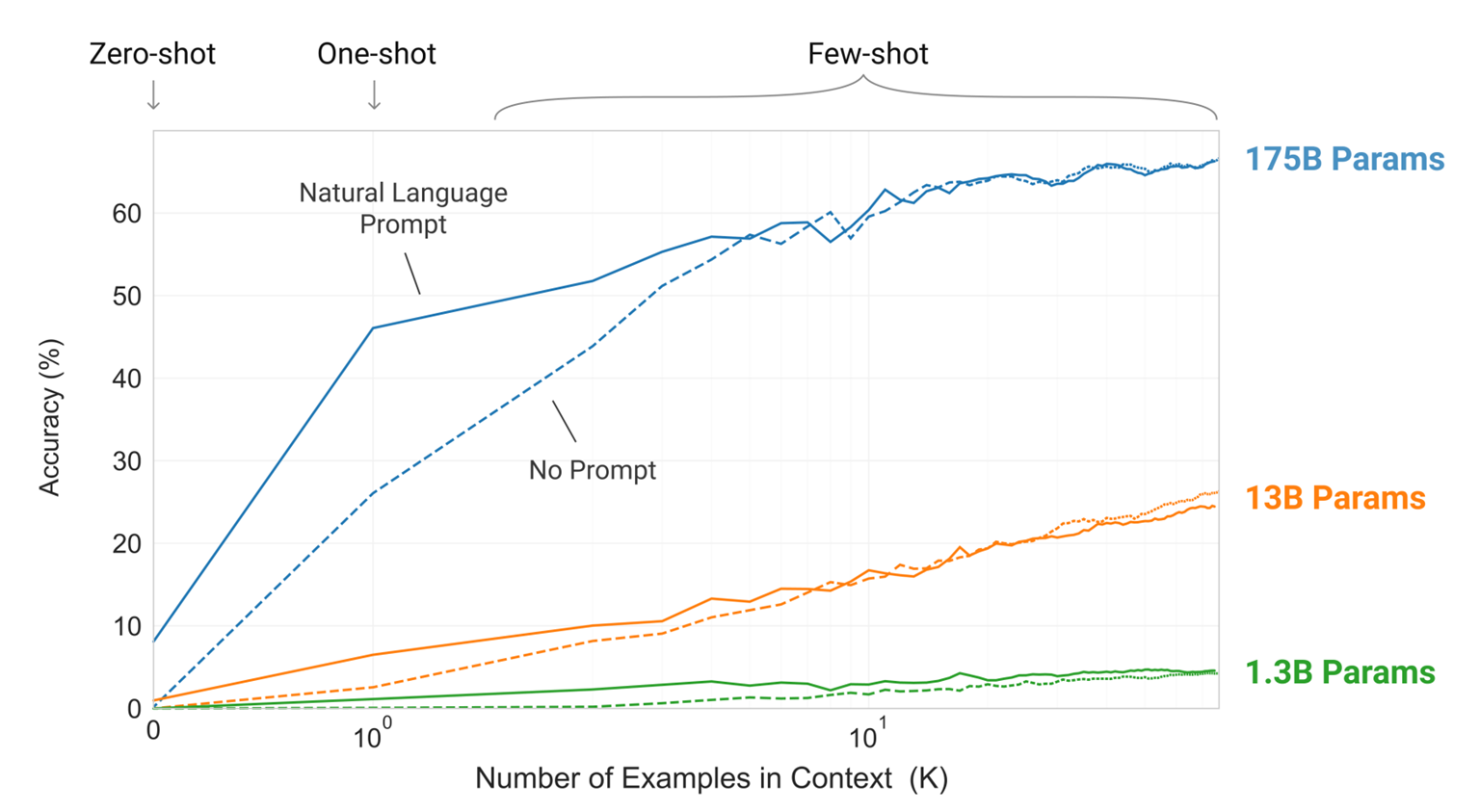
모델의 능력이 충분한 경우, Demonstraion 을 통해 성능 향상 가능!!
Prompt
- Task Description : 수행할 태스크에 대한 묘사
- Demonstration : 수행할 태스크 예시(입력-출력 쌍)
- Input : 실제 태스크를 수행할 입력 데이터

-> Prompt 구성 방식에 따라, 모델 성능 변화
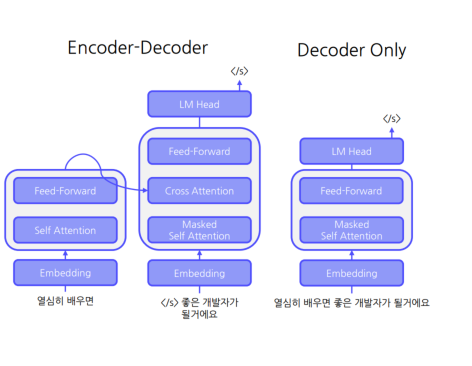
Model Architecture
• Encoder – Decoder 구조
입력 이해와 문장 생성 모델 분리
입력 이해 : Encoder를 통해 처리
문장 생성 : Decoder를 통해 처리
• Decoder Only 구조
단일 모델을 통해 이해 및 생성
1.3 Pretrain Task
① Encoder-Decoder 구조
Span Corruption 과정
1. 입력 문장 중 임의의 Span을 Masking
2. Masking 시 각 Masking Id 부여
3. Span Corruption된 문장을 Encoder 입력
4. Masking Id와 복원 문장을 Decoder 입력
5. Decoder는 복원된 문장 생성
• 입력 문장 이해 및 문장 생성 능력 학습
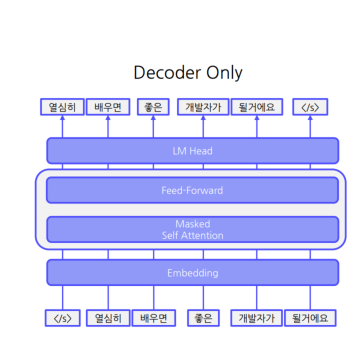
② Decoder Only 구조
• Language Modeling
• GPT-1에서 제안된 Pretrain Task
-> 입력된 토큰을 기반으로 다음 토큰 예측 수행
Language Modeling 과정
1. 문장 토큰 단위로 입력
2. 매 토큰마다 다음 토큰을 예측하도록 학습
• 이전 입력을 바탕으로 다음 토큰 생성 능력 학습
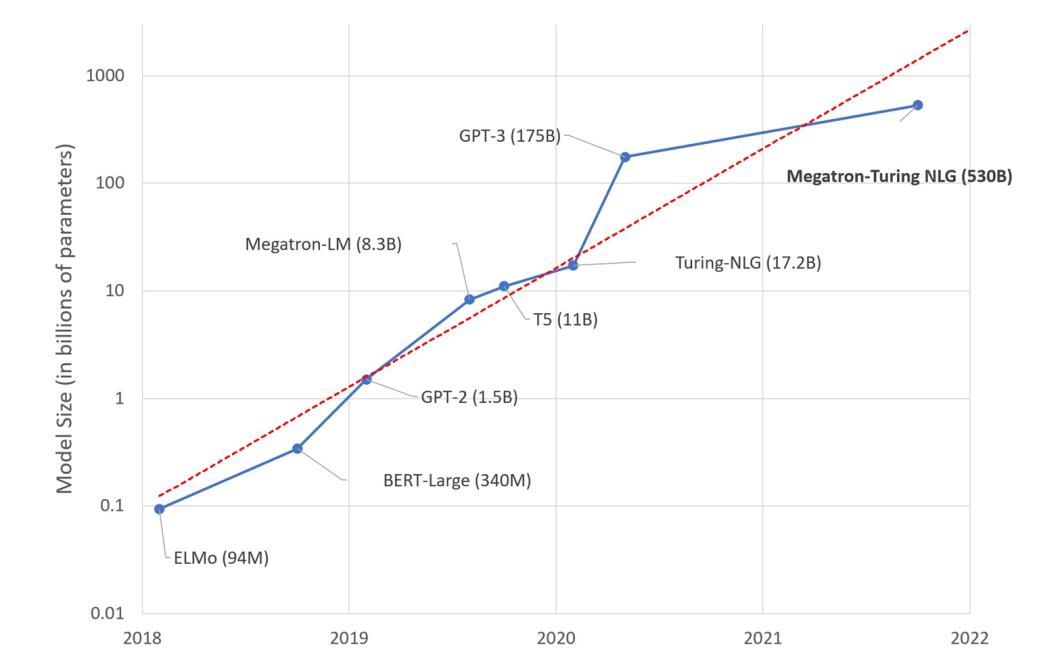
1.4 Pretrain Corpus
성능 향상 시간순서대로 비교
코퍼스 구축 절차

원시 데이터 내 학습 불필요 데이터 존재하면, 필터링.
Memorization in LLM
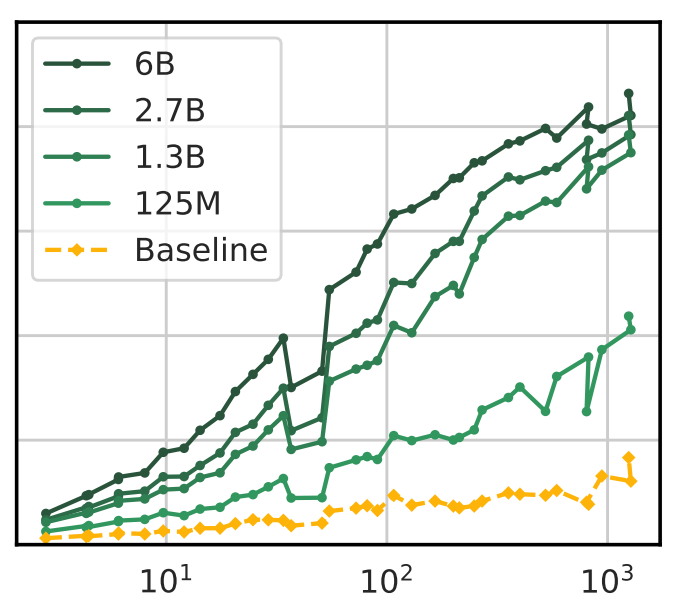
Memorization : LLM이 코퍼스 내 존재하는 데이터를 암기하는 현상
->정제 작업을 통해 학습 효율 극대화할 필요있음
-> 개인정보 같은 것도 정제작업을 통해 학습 방지할 필요 있음.
2. Instruction Tuning
2.1 Helpfulness & Safety
다양한 문장 생성 능력 보유
대형 코퍼스 : 온라인 상 존재하는 혐오/차별/위험 표현 포함
• LLM 학습에 반영
• 혐오/차별/위험 표현 생성 가능
• LLM의 활용 및 서비스화 걸림돌
=> 따라서 Safety 적용( LLM이 생성한 표현이 사회 통념상 혐오/위험/차별적 표현이 아니어야 함)
- Helpfulness적용( LLM은 사용자의 다양한 입력에 적절한 답변을 생성할 수 있어야 함_->사용자가 원하는 광범위한 입력에 적절한 출력을 생성해야 함)
이러한 과정을 Instruction Tuning 이라고 함
Instruction : 사용자의 광범위한 입력에 대해
• Safety : 안전하면서
• Helpfulness : 도움이 되는
• 적절한 답변을 하도록 Fine-Tune하는 과정
Instrucion Tuning 은 3단계로 구성
SFT -> Reward Modeling -> RLHF
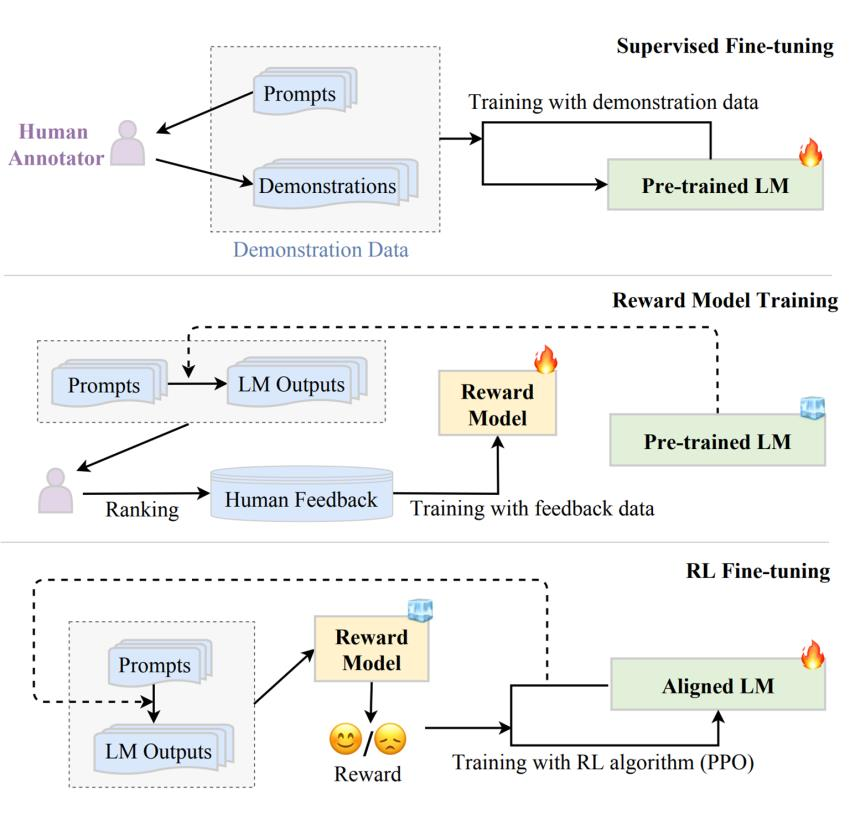
2.2 Supervised Fine-Tuning(SFT)
LLM에게 사용자 입력에 적절히 답변하도록 지도학습

2.3 Reinforcement Learning by Human Feedback(RLHF)
Step 2 : Reward Modeling
LLM의 답변에 대한 사람의 선호도 모델링
-> Prompt와 Demonstration을 입력으로 Rating을 산출하도록 학습

Step 3 : RLHF
LLM이 사람의 선호도가 높은 답변을 생성하도록 학습
->사람의 선호도 : Reward Model이 높은 점수를 부여하는 답변(PPO 알고리즘 이용)
overall

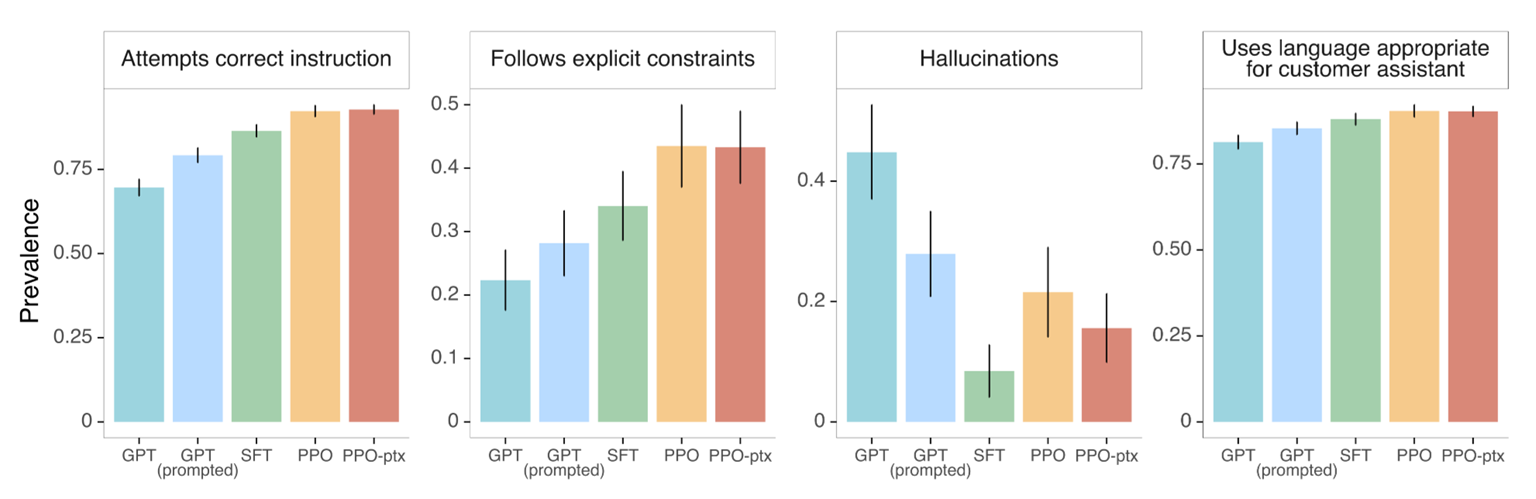
SFT 및 RLHF 효과
사용자 지시(Instruction) 호응도 상승
거짓 정보(Hallucination 생성 빈도 감소
Conclusion
LLM & Instruction Tuning
- LLM : 대량의 코퍼스로 학습된 파라미터가 매우 많은 언어모델
- Zero/Few-shot Learning : 입력 데이터 내 주어진 정보로 새로운 태스크를 해결하는 능력
• 기존 Finetuning 기반 방식 모델 패러다임과 다른 LLM 활용 방식
• LLM의 광범위한 활용 배경 - LLM은 학습 데이터 암기(Memorization) 능력 매우 탁월
• 욕설/사회적 편향/개인 정보 등 사전학습 코퍼스 전처리 필수적 - Instruction Following : 사용자 입력에 적절한 출력을 생성하는 능력
• LLM은 사용자 입력에 맞추어 유용하고(Helpfulness) 안전한(Safety) 답변을 생성해야 함 - Instruction Tuning : Instruction Following 능력 향상을 위한 Finetune 방법론
• SFT 및 RLHF를 통해 Instruction Following 능력 향상 가능
• SFT 및 RLHF 학습 데이터 구축 시 매우 큰 비용 발생 및 섬세한 설계 필요
3. 참고자료
- Training language models to follow instructions with human feedback
https://arxiv.org/abs/2203.02155 - A Survey of Large Language Models
https://arxiv.org/abs/2303.18223 - Language Models are Few-Shot Learners
https://arxiv.org/abs/2005.14165
