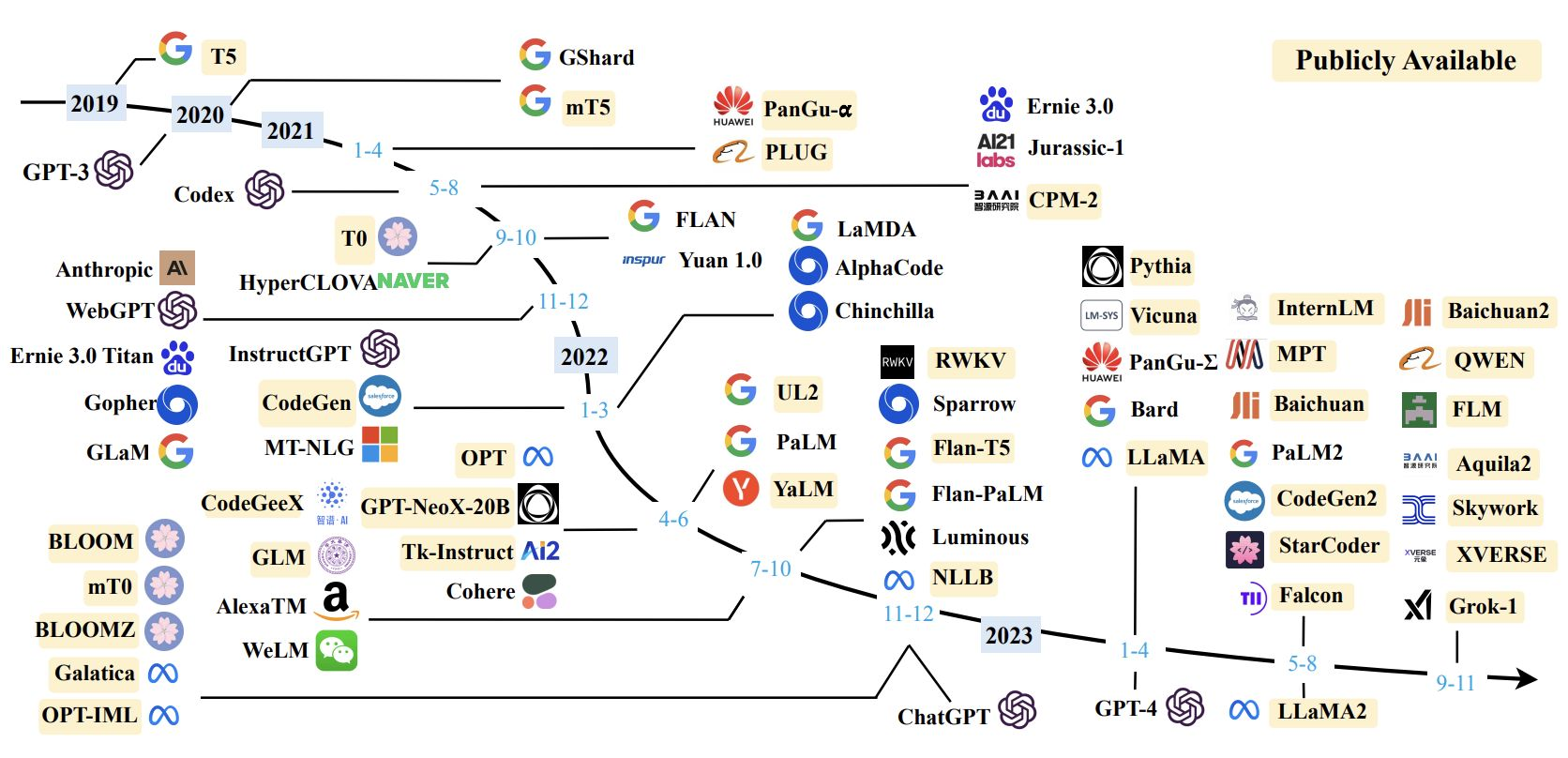
1. LLM발전과 PEFT방법론의 중요성
1.1 LLM의 발전과정
• 언어모델을 활용하기 위해서는 일반적으로 범용웹데이터를 기반으로
• 1)사전학습을수행하고 2)Downstreamtask에 맞추어fine-tuning을 진행해왔음=>이러한 학습방법은 특정 task에서 성능향상을 보장함
1.2 기존의 학습방법론
Conventional approach-1:Finetuning
task 에 맞게 파라미터 업데이트 또는 fintuning 하는 방법론들은 우수한 성능을 보였고 밑 3가지 방법으로 유형화됨.
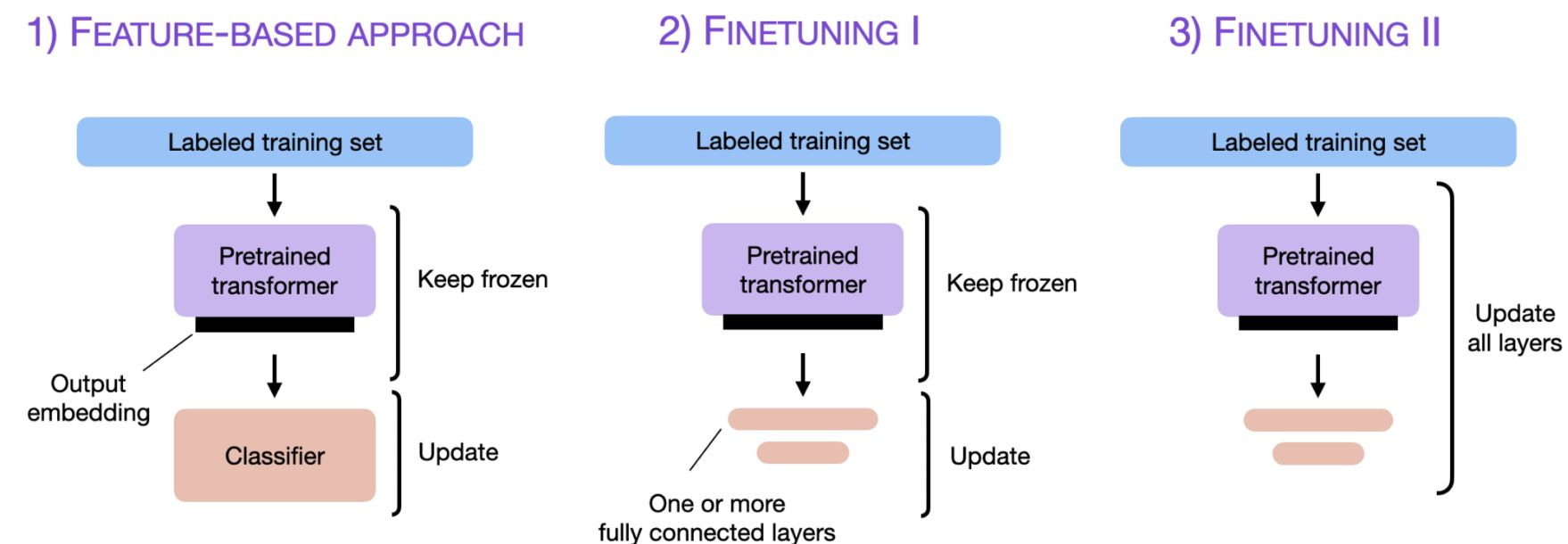
① 사전학습 모델로부터 Embedding을 추출하고 classifier를 학습하는방법
② output layer 들을 업데이트 하는 방법
③ 모든 layer 들을 업데이트 하는 방법
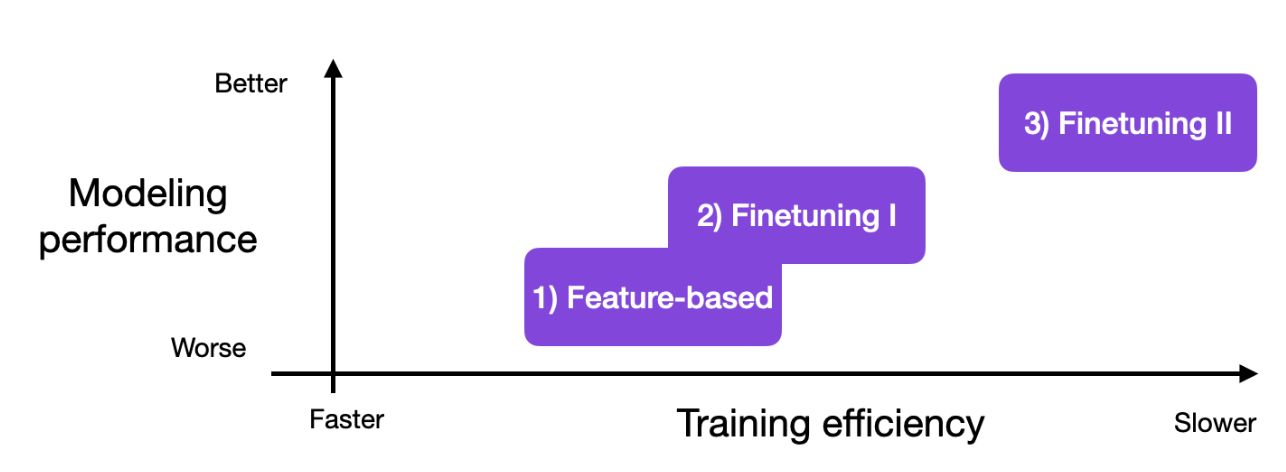
=> 모든 파라미터들을 학습하는 것이 가장 좋았음.
Conventional approach-2:in-context learning(ICL)
Target task에 대해 몇가지 예시를 모델에 입력해주게 될 경우 모델을 튜닝하지 않고 쉽게 문제를 풀 수 있게되었음

Conventional approach한계
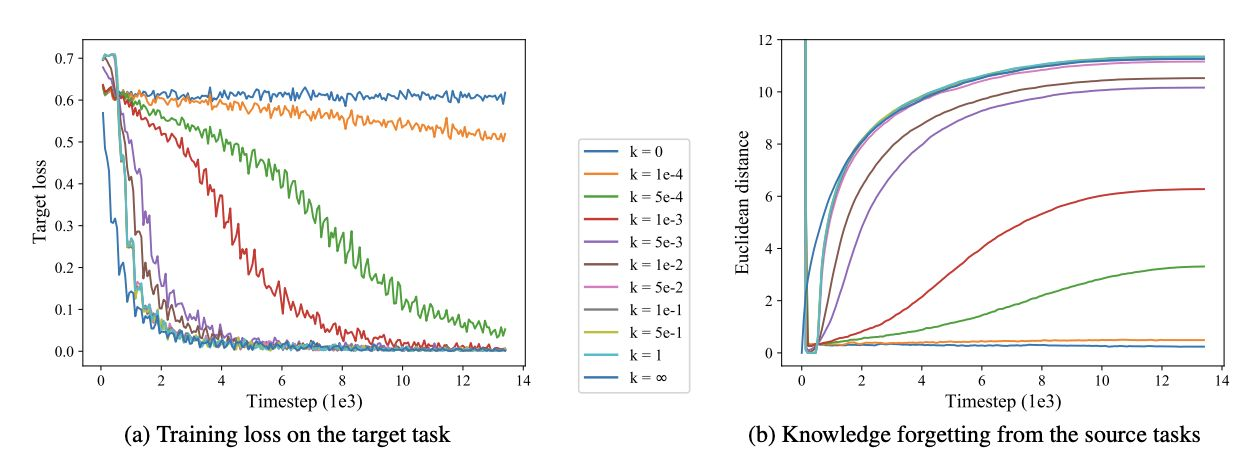
모델을 지속적으로 추가 학습하는 과정(sequential transfer learning paradigm)은 언어모델이 기존에 학습한 정보를 잊는 현상을 야기
자원측면, 신뢰성 측면에서 문제
자원측면
특히 각 down streamtask마다 독립적으로 학습된 모델을 저장하고,배포할때
막대한 시간과 컴퓨팅자원이 필요해짐
신뢰성측면
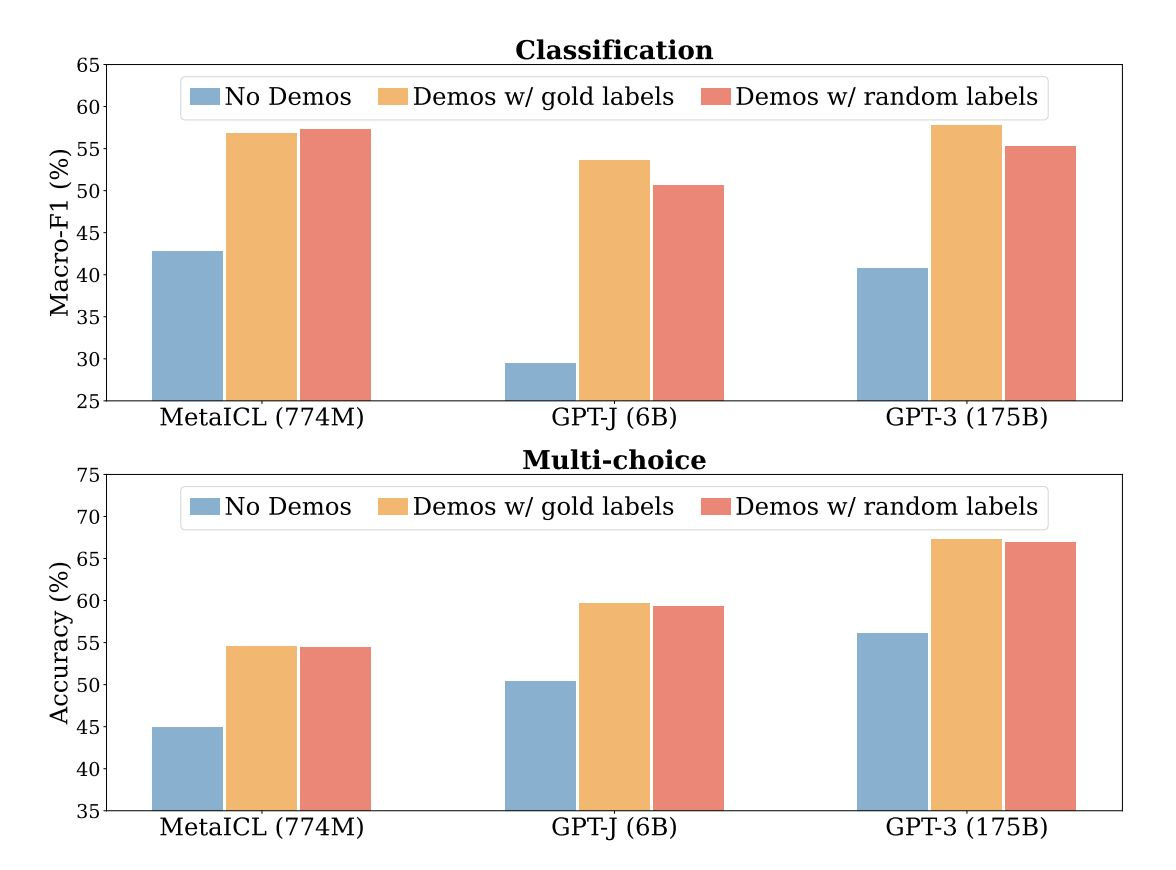
몇몇경우에random한label을 넣어주더라도 문제를 잘 해결한다는 연구결과가 존재함
1.3 Parameter-EfficientFine-Tuning이란?
-> 파라미터가 많은 LLM도 효율적으로 학습할 수 있는 방법을 찾는 것.
모델의 모든 parameter를 학습하지않고 일부 파라미터만 Fine-tuning하는 방법
4가지 방식이 있음!
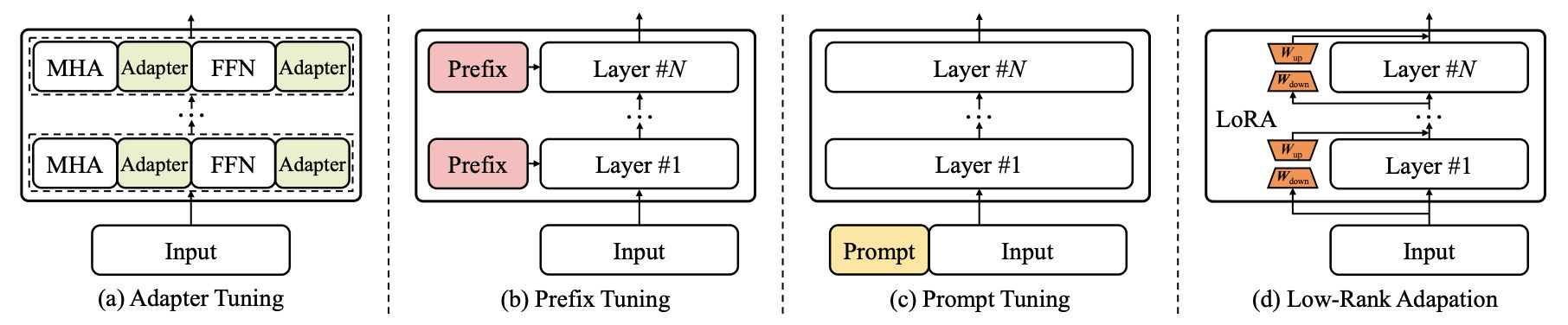
Transformer 모델의 모든 파라미터를 업데이트 하지 않고,각 방법론 별로 소량의 파라미터를 효과적으로 업데이트함
(MHA는 multi-head attention,FFN은 feed-forward network를의미함)
2.PEFT Methods
2.1 Adapter
기존에 이미 학습이 완료된 모델의 각 레이어에 학습가능한 FFN을 삽입하는 구조
->Adapter layer는 transformer의 vector를 1)더 작은 차원으로 압축한후 2) 비선형 변환을 거쳐 3)원래 차원으로 복원하는 병목구조(bottleneckarchitecture)로 이루어짐
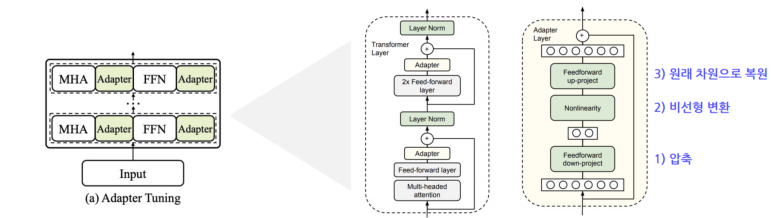
->Adapter모듈은 finetuning단계에서 특정 targettask에 대해 최적화됨
Adapter는 기학습된 모델의 각 레이어에 학습 가능한 Feedforward network를 삽입하는 구조입니다. Adapter layer는 vector를 압축 - 비선형 변환 - 원래 차원으로 복원 하는 과정을 거치며, 특정 task의 성능 향상을 목표로 제안
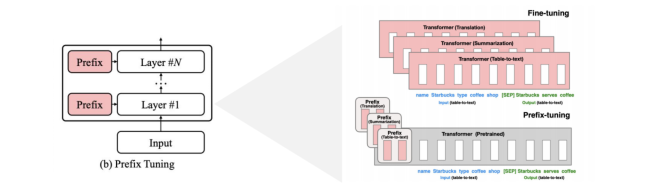
2.2 Prefix Tuning
Transformer의 각 레이어에 prefix라는 훈련가능한 vector를추가하는 방법으로, prefix는 가상의embedding으로 간주될수있음
2.3 Prompt Tuning
모델의 입력 레이어에 훈련가능한 prompt vector를 통합하는 방법론
=> 이는 input 문장에 직접적인 자연어prompt를 덧붙이는 prompting과는 다른개념이며 embedding layer를 최적화하는 방법론

2.4 Low-Rank Adaptation(LoRA)
사전 학습된 모델의 파라미터를 고정하고,학습가능한 rank decomposition행렬을 삽입하는 방법(행렬의 차원을 ‘rank’만큼 줄이는 행렬과,다시 원래의 차원 크기로 바꿔주는 행렬으로 구성)
- 레이어마다 hiddenstates에 lora parameter를 더하여 tuning함
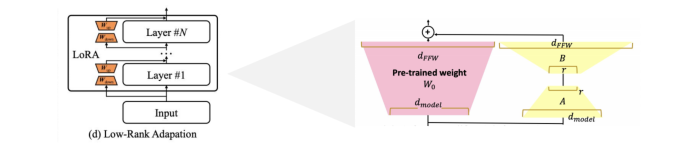

->LoRA를 이용하면 새롭게 학습한 파라미터를 기존모델에 합쳐줌으로서 추가연산이 필요하지 않음
2.5 Code example
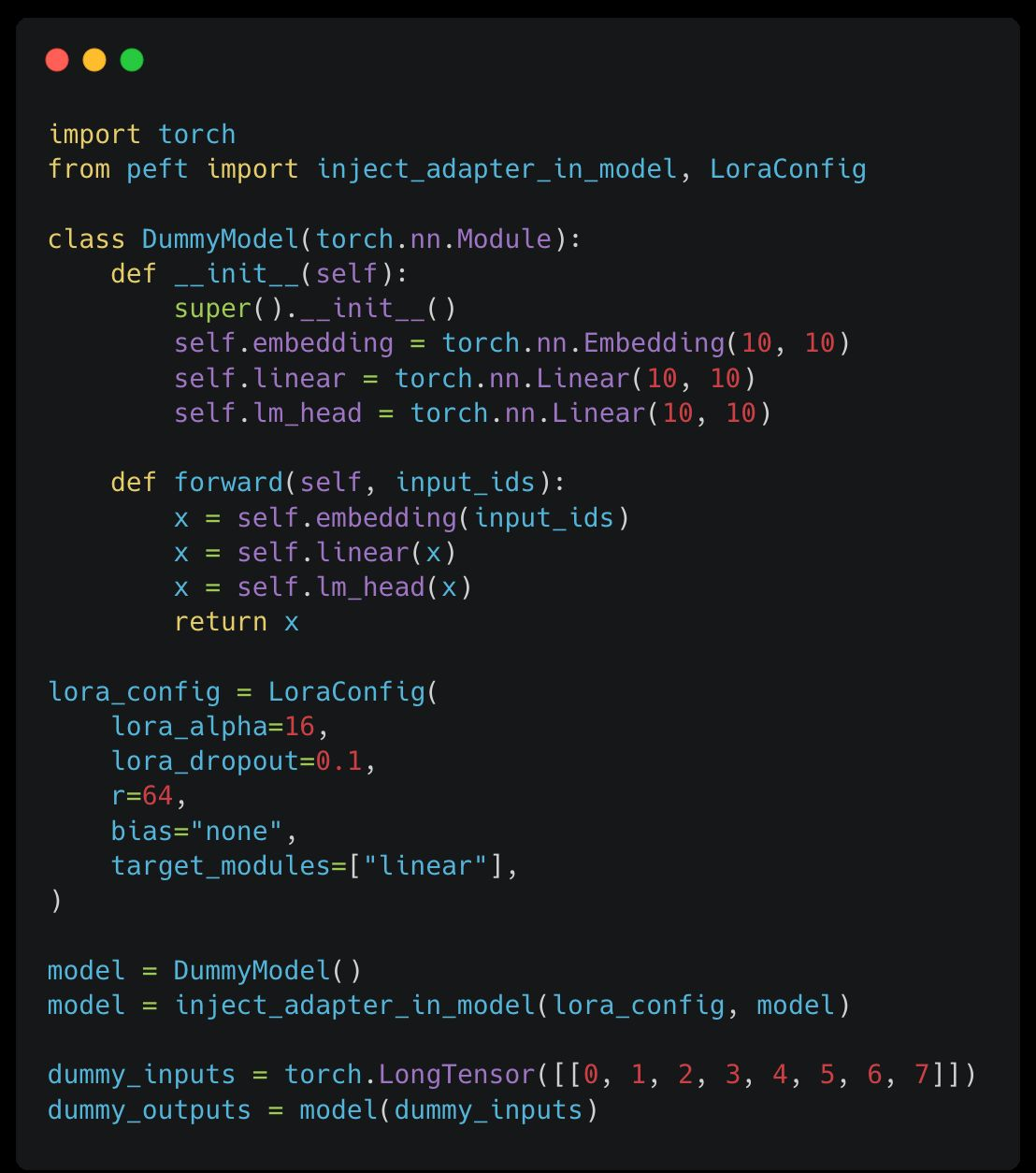
Huggingface

