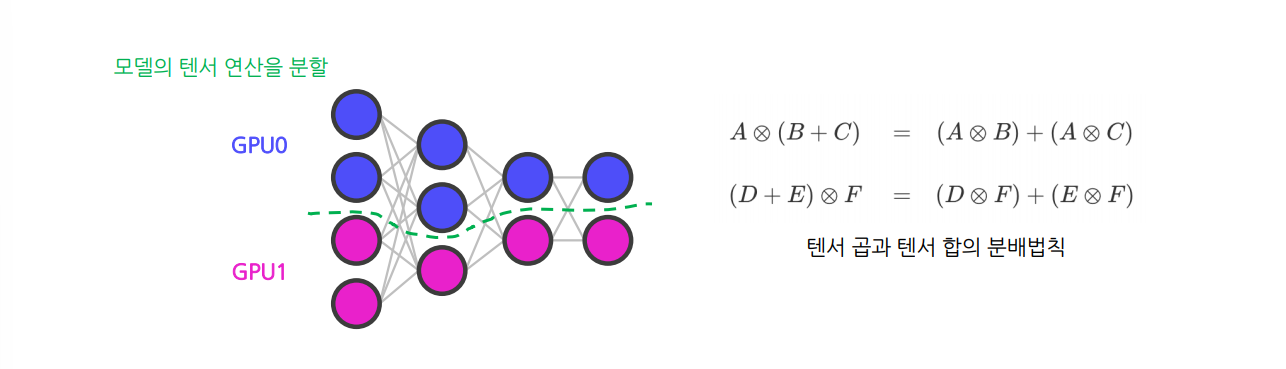
1. Tensor Parallelism
Tensor Parallelism : 모델을 텐서 연산 단위로 여러 GPU에 나누어 계산하는 방식
텐서 연산을 여러 차원의 슬라이스(slice)로 나눈 후 GPU들에 할당하여 처리하는 패러다임
- 텐서 연산을 나누어 수행해도 똑같은 값을 얻을 수 있다는 개념에서 시작
- 크기가 큰 텐서 연산도 수행 가능하지만 적용 과정이 복잡함
AllReduce 연산은 여러 디바이스에 있는 데이터를 하나의 값으로 ‘줄여’ 그 결과를 모든 디바이스에 전송하는 연산이다. 반면 AllGather 연산은 여러 디바이스에 있는 데이터를 그대로 보존한 채로 ‘모아'서 모든 디바이스에 전송하는 연산이다.
열 단위(column-wise) Tensor Parallelism에서는 Forward pass에서 각 GPU의 output 값을 그대로 이어붙여 하나의 전체 output 행렬을 형성한다. 이 때 AllGather 연산을 사용한다. Backward pass에서는 각 GPU의 열 단위 gradients를 모든 GPU에 동일하게 공유하게 되는데, 이 때 AllReduce 연산이 사용된다.
한편 행 단위(row-wise) Tensor Parallelism에서는 Forward pass에서 각 GPU의 output 값을 합산하여 동일한 값으로 출력하기 위해 AllReduce 연산이 사용된다. Backward pass에서는 각 GPU의 행 단위 gradients를 그대로 이어붙여 전체 gradients를 형성할 때 AllGather 연산이 사용된다
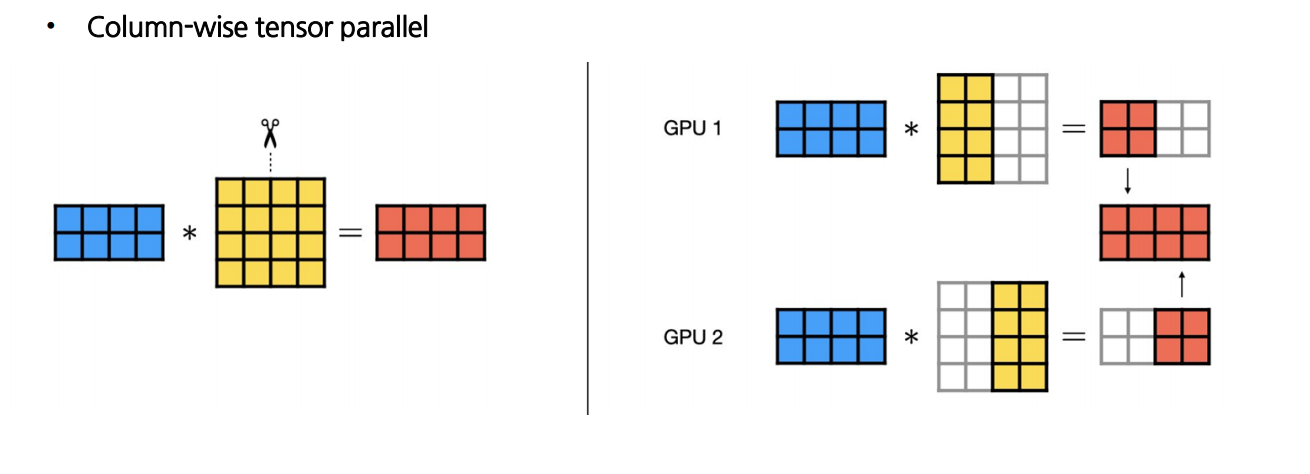
1.1 Column-wise Tensor Parallelism
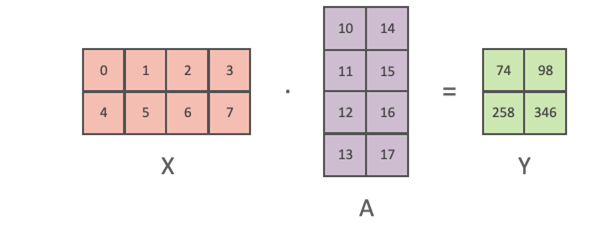
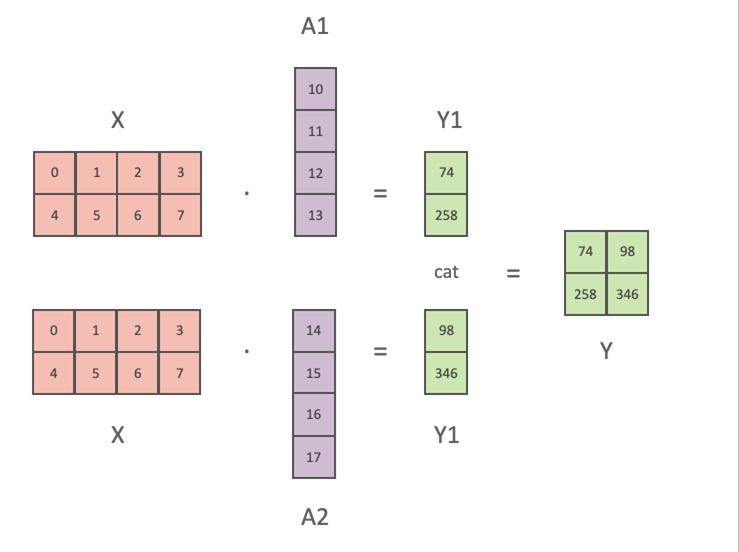
input 행렬이 주어졌을 때, 각 GPU는 weight 행렬의 열 부분을 나누어 계산
- 각 GPU의 output 값의 열 부분만 계산
→ output 행렬의 전체적인 차원을 완성하기 위해 다른 GPU의 계산 결과가 필요 (퍼즐 맞추기) - Forward Pass : 각 GPU의 output 값을 그대로 이어붙여 하나의 전체 output 행렬을 형성
- Backward Pass : 각 GPU의 열 단위 gradients를 모든 GPU에 동일하게 공유
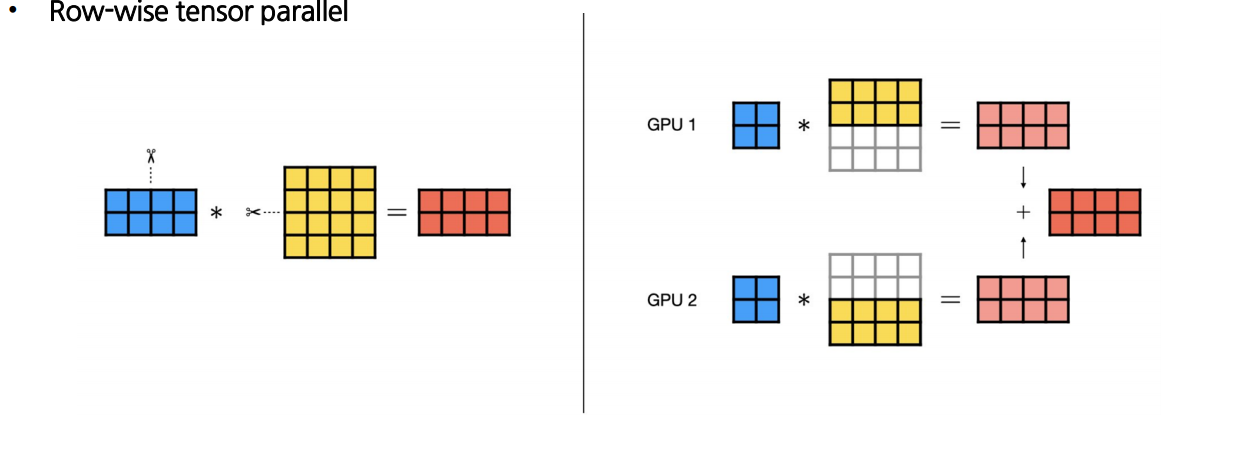
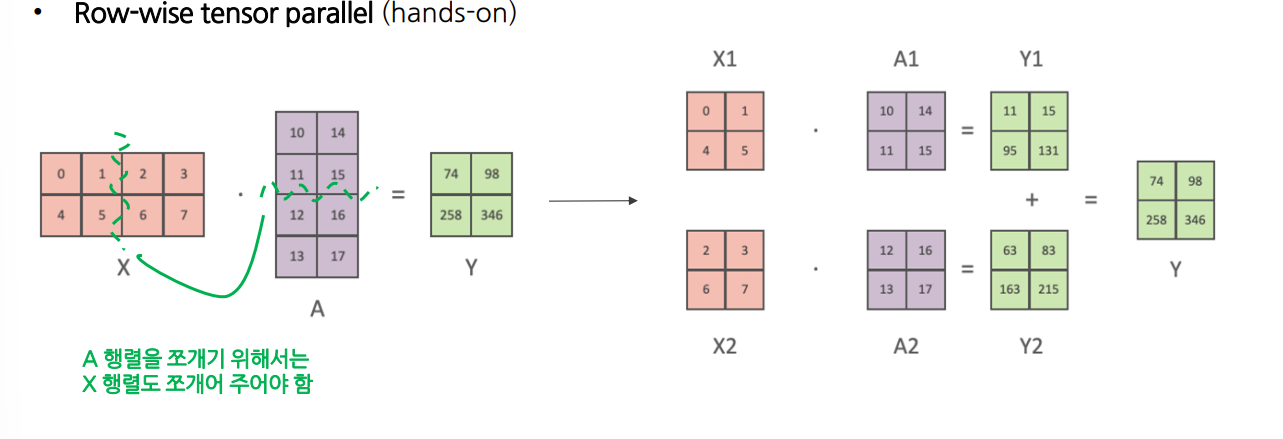
1.2 Row-wise Tensor Parallelism
input 행렬이 주어졌을 때, 각 GPU는 weight 행렬의 행 부분을 나누어 계산
- GPU의 output 행렬 차원은 동일 → output 값을 합산하여 전체를 동기화 해야 함
- Forward Pass : 각 GPU의 output 값을 합산하여 동일한 값으로 출력
- Backward Pass : 각 GPU의 행 단위 gradients를 그대로 이어붙여 전체 gradients를 형성
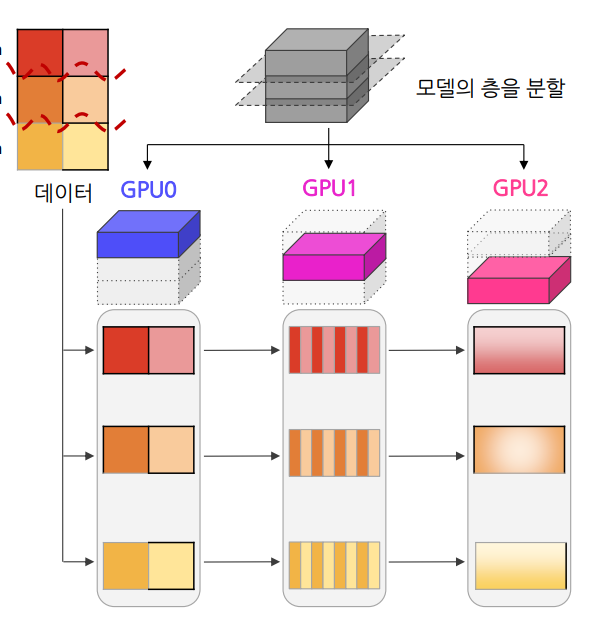
2. Pipeline Parallelism
Pipeline Parallelism : 모델을 층 단위로 GPU에 할당하여 순차적으로 처리하는 방식
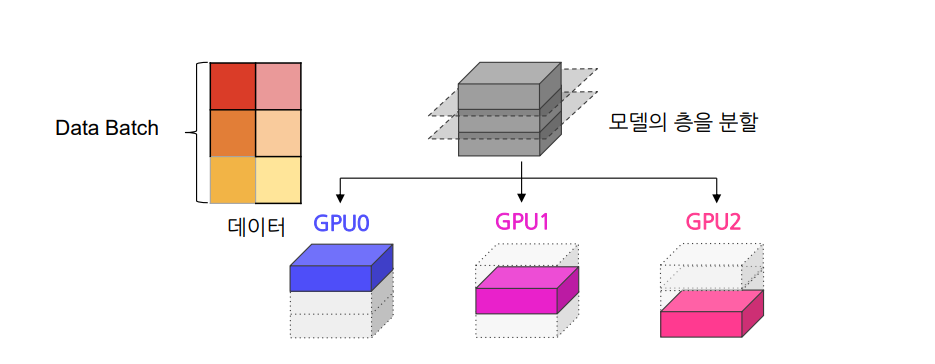
모델의 여러 층을 스테이지 단위로 나눠 각각의 GPU에 분배하고 데이터들을 나누어 순차적으로 넣어 주는 패러다임
- 각 GPU가 서로 다른 레이어를 처리하므로 계산 효율성을 높이고 메모리 사용량을 분산할 수 있음
- 모든 GPU가 일할 수 있게 하는 효율적인 패러다임이지만, 스테이지 간 연산량에 차이가 클 경우 대기시간(latency)이 길어질 수 있음
Pipeline Mechanism
Initialization
모델을 연속적인 여러 스테이지로 나눔
- 각각의 스테이지들을 GPU들에 할당
Forward Pass
데이터 Batch를 더 작은 단위로 쪼갬
- 쪼개진 Micro-batch 데이터를 순차적 주입
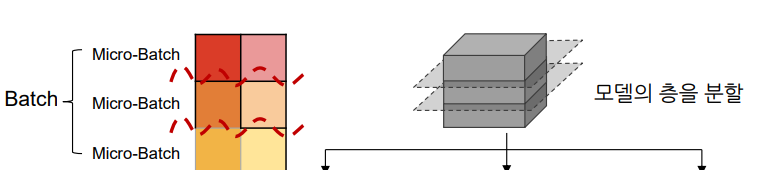
왜 잘게 쪼개서 주입할까?
-> Pipeline Bubble이 있기 때문!
각 GPU에서는 이전의 스테이지가 끝나야지만 연산을 시작할 수 있음
GPU가 연산을 하지 못하는 유휴 시간을 Pipeline Bubble이라 지칭
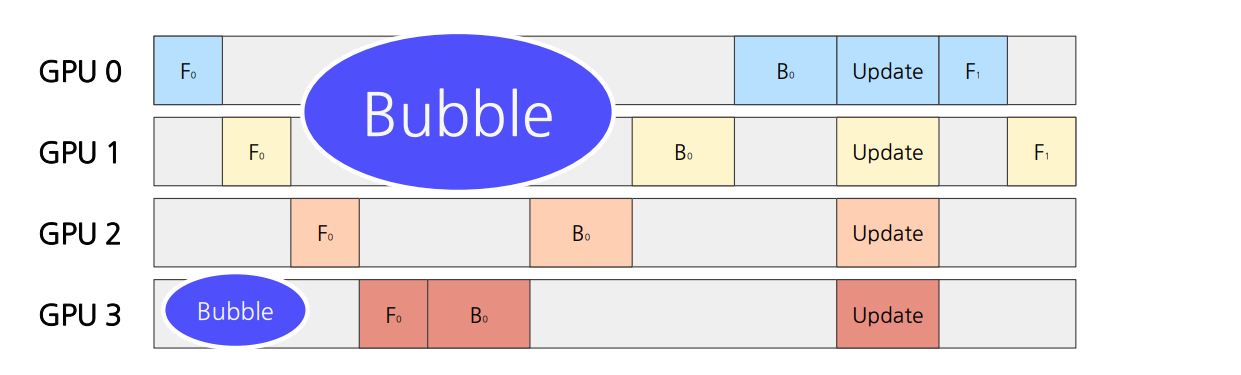
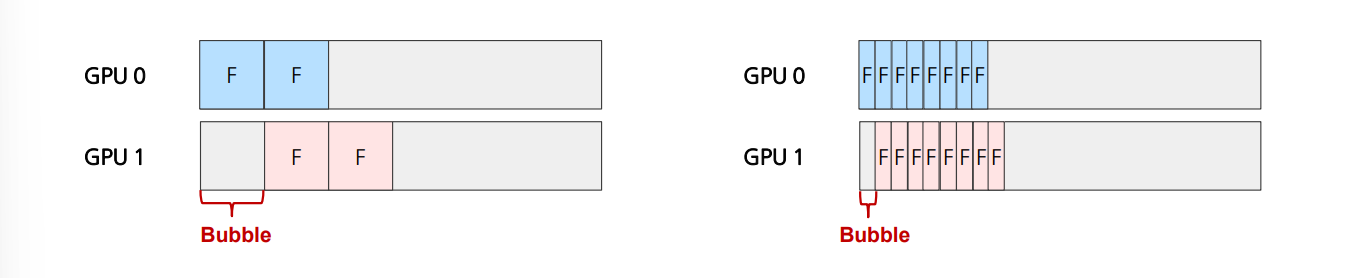
Batch를 작게 쪼개서 연산을 일찍 끝낼수록 뒤에 있는 layer의 bubble이 적게 발생!
(하지만 너무 작게 분해할 경우 스테이지 간 통신이 더욱 빈번해짐 – 오히려 더 오래 걸릴 수 있음)
Backward Pass
마이크로배치들이 스테이지에 들어간 역순으로 gradients 계산 모델 업데이트
각 GPU에서 Forward Pass, Backward Pass의 순서를 지켜 데이터를 처리하는지에 따라 2가지로 분류 -> 순서를 지키면서 하면 Synchronous Pipeline , 번갈아가면서 처리하면 Asynchronous Pipeline
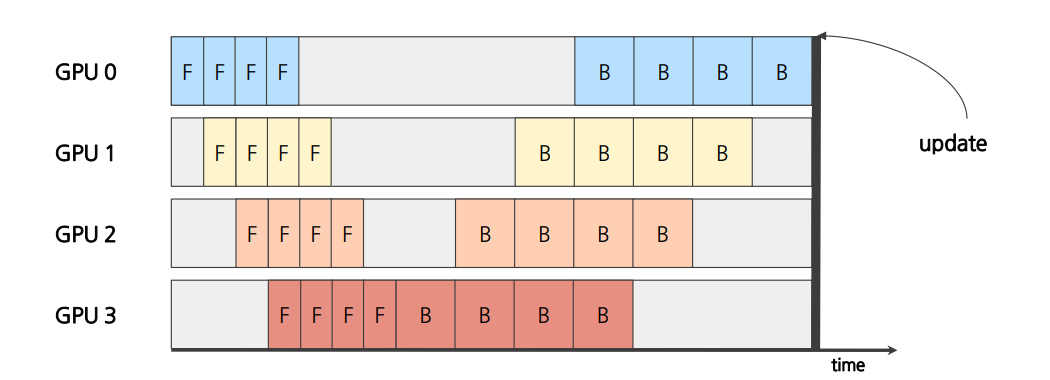
2.1 Synchronous Pipeline Parallelism
Forward 연산을 마치기 전까지 Backward연산을 실행하지 않음.
모든 backward연산을 마치면 한번에 모델 update 진행
2.2 Asynchronous Pipeline Parallelism
한 마이크로 배치의 Forward 연산과 (연산가능한 경우) Backward Pass를 번갈아가면서 수행함
- 각 파이프라인 단계가 독립적으로 작동 (다른 GPU 완료 여부에 영향 X)
- 단계 간의 동기화 지점이 없어 더욱 빠른 다음 마이크로배치 처리 ← Bubble 추가 감소
파라미터를 모든 GPU가 공유하지 않고 GPU별로 일부분을 개별 관리 ← DDP와 같은 원리
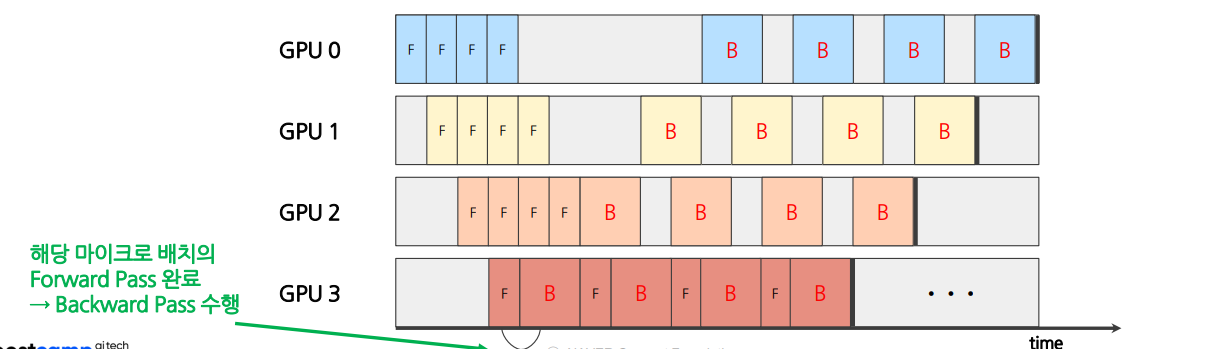
2.3 Synchronous Vs Asynchrounous
Asynchronous Pipeline Parallelism이 일반적으로 더 높은 처리량을 제공할 수 있지만, 항상 Synchronous 방식보다 빠르고 효율적인 것은 아니다.
Asynchronous 방식은 gradient 업데이트의 일관성이 떨어질 수 있어 학습 안정성에 영향을 줄 수 있다. 반면 Synchronous 방식은 더 일관된 gradient 업데이트를 제공하여 특정 상황에서 더 나은 학습 결과를 얻을 수 있다.
따라서 모델 특성, 학습 데이터, 하드웨어 구성 등에 따라 어느 방식이 더 효율적인지가 결정된다.
| 분류 | Synchronous Pipeline | Asynchronous Pipeline |
|---|---|---|
| 학습 속도 | 학습 속도가 크게 증가하지만 동기화 과정에서 병목 현상이 발생할 수 있음 | 동기화 과정이 없으므로 학습 속도 크게 증가 |
| 메모리 효율성 | 모든 GPU에서 gradients들이 동기화되어야 하기 때문에 메모리 효율성이 상대적으로 낮음 | 동기화 과정에서 생기는 idle time을 최소화하기 때문에 메모리 효율성이 높음 |
| 수렴도 | 안정적이고, 모델의 정확도 높음 | 각 GPU에서 비동기적으로 gradients를 업데이트하기 때문에 불안정하고, 정확도도 낮음 |
| 장점 | 구현이 상대적으로 쉬움 | 학습 속도, 메모리 효율성 증가 |
| 단점 | Gradient 동기화 과정으로 인한 idle time 발생 | 구현이 매우 복잡함 |
| 사용 전략 | 동일한 GPU를 여러 개 사용하고, 모델이 안정적으로 수렴해야 할 때 사용 | GPU 환경이 각각 다르고, 메모리 효율성을 최대화할 때 사용 |
3. Parallelism Summary
| 구분 | Data Parallelism | Tensor Parallelism | Pipeline Parallelism |
|---|---|---|---|
| 전략 | 데이터를 여러 GPU에 분산하여 각 GPU가 모델의 복사본으로 병렬 처리 | 모델의 텐서(weights)를 여러 GPU에 분산하여 각 GPU가 모델의 일부만 처리 | 모델의 여러 층을 GPU에 분산하여 각 GPU가 순차적으로 모델 일부를 처리 |
| 장점 | 구현이 쉽고, 큰 데이터셋 처리에 효과적 | GPU당 메모리 사용량 감소 | 매우 큰 모델 처리가 가능하고, 메모리 부담 감소 |
| 단점 | 각 GPU에 모델 전체가 필요해 메모리 한계 존재 | GPU 간 통신이 증가하여 병목(bottleneck) 가능 | 모델 층 간 데이터 전달로 인한 지연 발생 |
| 사용 전략 | 큰 데이터셋과 중간 크기 모델 학습에 적합 | GPT-3와 같은 초대형 모델 학습에 적합 | 깊은 구조의 대형 모델에 적합 |
