1. Concept
1.1 Overview of Distributed Training
Distributed Training: 모델을 여러 개의 GPU로 분산시켜 GPU에 한 번에 들어가지 않는 큰 모델도 학습 가능하도록 함
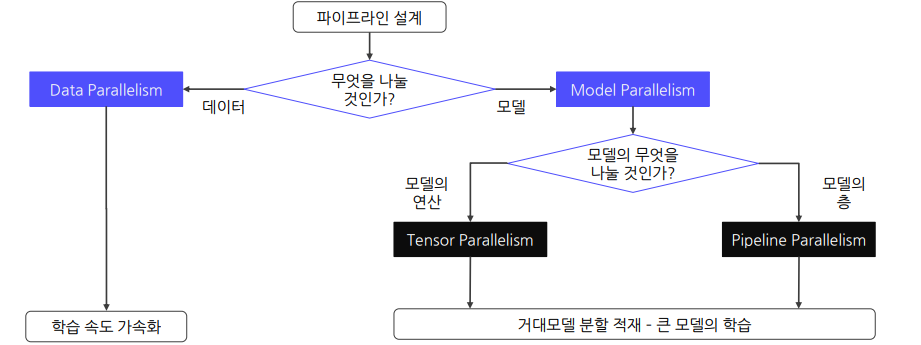
Data Parallelism
큰 데이터를 여러 GPU들에 분할하여 동시에 처리함으로써 학습 속도를 높임
GPU간의 출력값들을 바탕으로 복제된 모델들을 동일하게 업데이트 해주는 과정 필요
다만 모든 GPU로 모델을 복제해야 하기 때문에 메모리 사용량은 증가함!
Model Parallelism
큰 모델을 여러 GPU들에 분할함으로써 하나의 GPU로는 처리할 수 없는 대형 모델도 처리 가능
단일 GPU의 메모리 제약 조건을 해결하면서 평균 GPU 메모리 사용량도 최적화
GPU는 다른 GPU로부터 이전 레이어의 결과값을 이어 받아야 함
| 방법 | Data Parallelism | Model Parallelism |
|---|---|---|
| 병렬처리 대상 | 데이터 샘플 | 모델 파라미터 |
| 목표 | 학습 속도 가속화 | 거대모델 분할 적재 (초거대모델 학습) |
| 학습 속도 | GPU 개수에 비례 | 병목으로 인해 속도 저하 |
| 구현 난이도 | 비교적 쉬움 | 구현 및 관리가 어려움 |
2. Data Parallelism
2.1 Mechanism
큰 데이터를 여러 GPU들에 분할하여 동시에 처리함으로써 학습 속도를 높임
GPU간의 출력값들을 바탕으로 복제된 모델들을 동일하게 업데이트 해주는 과정 필요

2.2 DP(DataParallel)
Backward Pass에서 master GPU가 모든 GPU들에서 계산된 gradient들을 모아 모델 복제본을 업데이트하고, Forward Pass에서 모든 GPU들이 master GPU의 업데이트된 모델을 복사하여 훈련
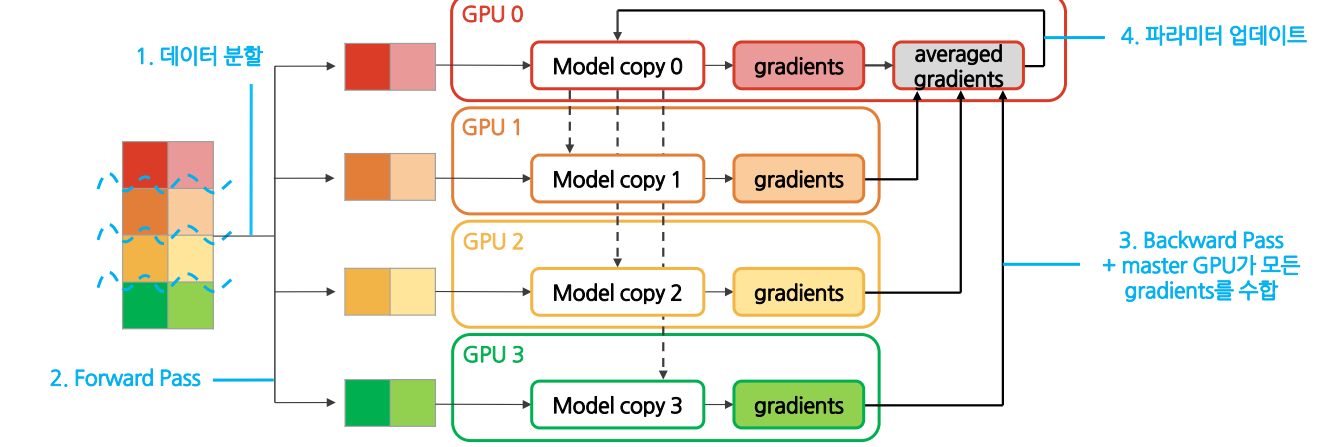
DP workflow
(1) Initialization
A. 데이터셋을 미니배치(minibatch) 단위로 나눔
->GPU개수에 맞춰서 나눔
B. Master GPU가 각 GPU에 모델 전달(이를 scatter이라고 함)
각 GPU는 동일한 weights를 지님
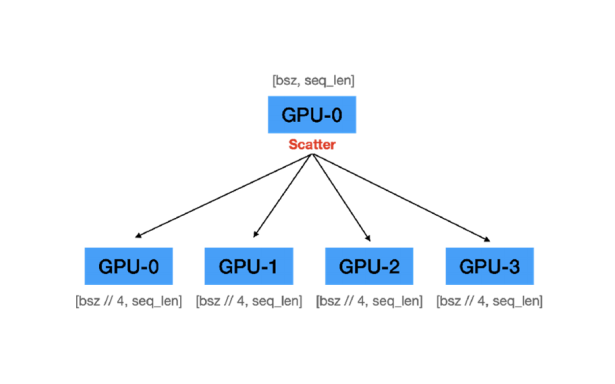
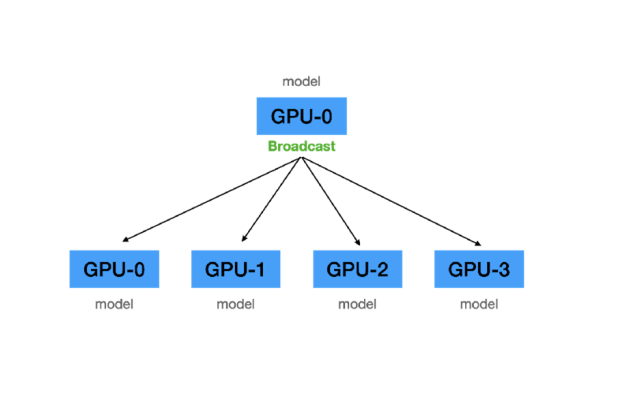
(2) Forward Pass
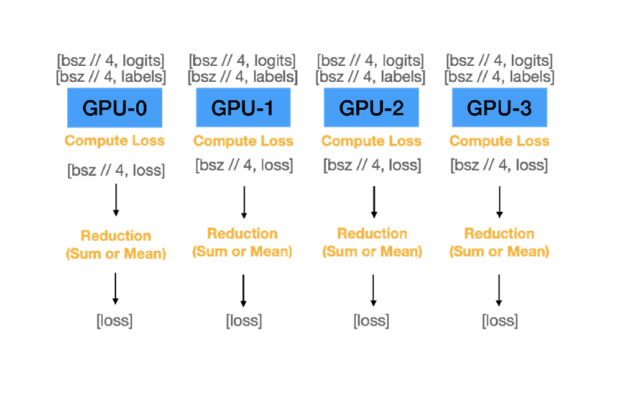
A. 각 GPU에서는 전달받은 데이터의 logit 값 계산
→ 각 GPU는 고유 logits를 가짐
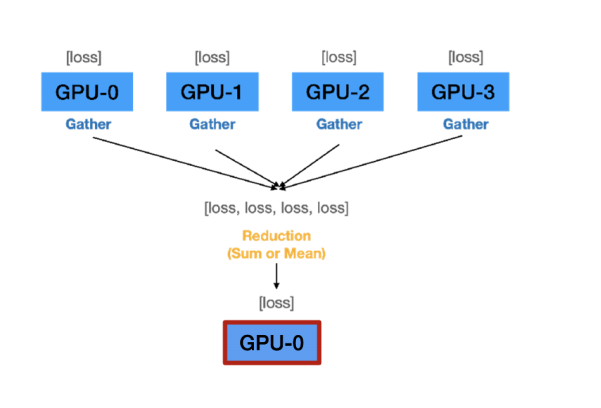
B. Master GPU가 모든 logits 값 취합
C. Master GPU가 전체 logits에 대한 loss 값 계산

(3) Backward Pass
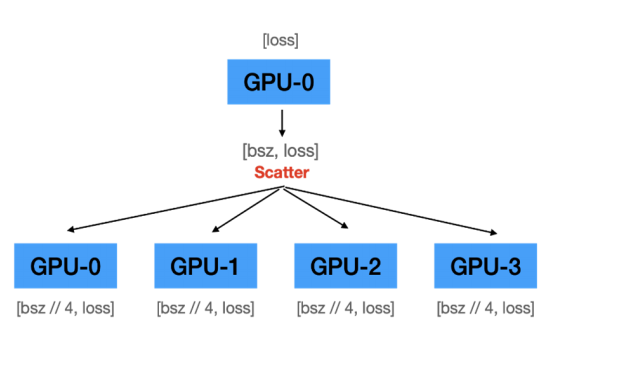
A. Master GPU는 계산한 loss를 각 GPU에 전송
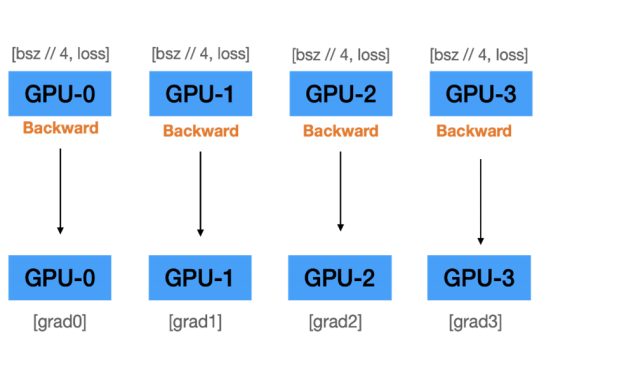
B. 각 GPU에서 gradients 계산
→ Initialization에서 주어진 데이터셋에 대한 고유 gradients 값을 가짐
C. Master GPU가 모든 gradients 값 취합
D. Master GPU에서 모델 weights를 업데이트
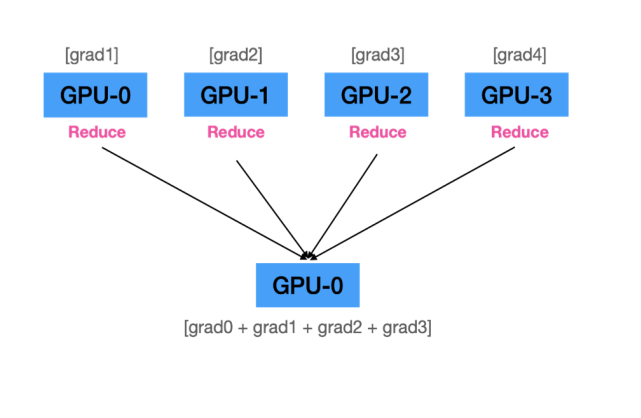
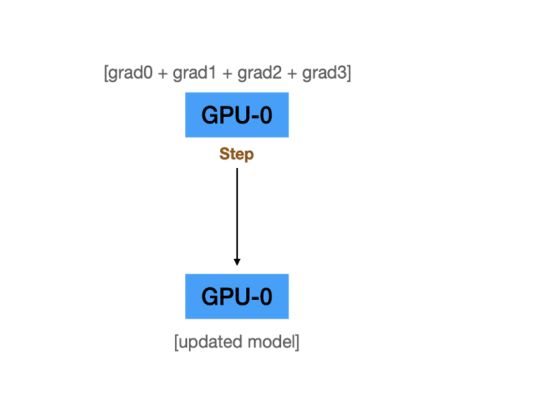
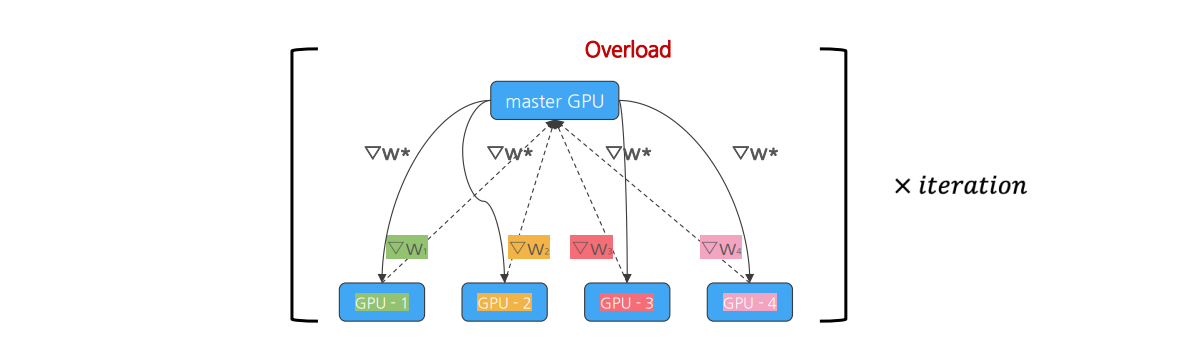
Problem of DP Workflow
Master GPU 부하(병목) 발생
1. 모든 GPU logits, gradients 취합 및 전체 Loss 계산.
2. 모델의 파라미터 업데이트 과정
3. 업데이트된 weights들을 재전송.
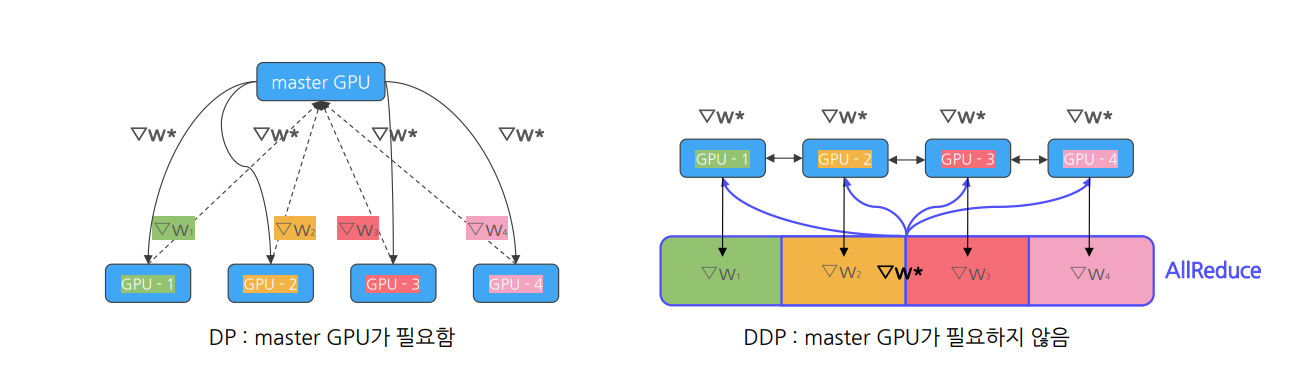
Solution - Distributed Data Parallelism (DDP)
병목의 원인인 마스터 노드 없애고 각자 알아서 모델 업데이트하자!
=> 대신 모델 업데이트에 필요한 값들은 서로 공유하자!
(대표적으로 AllReduce의 Ring 알고리즘 등이 존재_)
2.3 DDP(Distributed Data Parallel)
DDP란, Backward Pass에서 AllReduce 연산을 사용하여 모든 GPU들에서 계산된 gradient들을 동기화한 후, 각 GPU에서 독립적으로 모델 weights를 업데이트하여 모델을 훈련시키는 방법
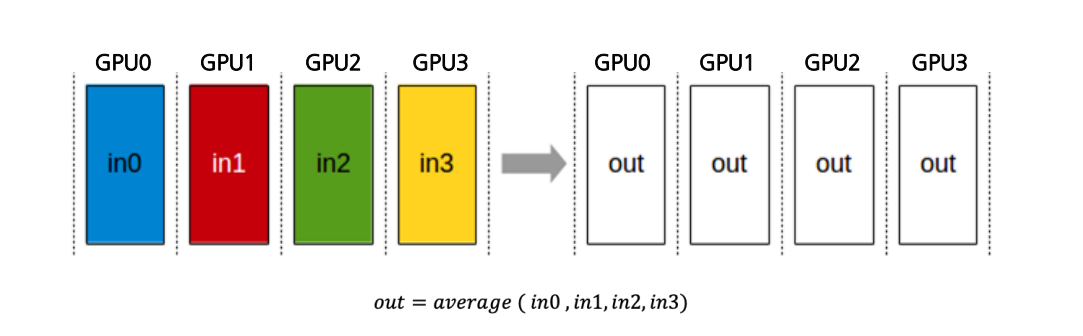
What is AllReduce Operation?
AllReduce는 모든 프로세스의 대상 배열을 단일 배열로 줄이고 결과 배열을 모든 프로세스로 반환하는 작업
- 여러 디바이스에 흩어져 있는 데이터를 서로 동시에 주고받기 위한 Collective Operation 중 하나
- 여러 디바이스에 있는 데이터를 모두 모아 하나의 값으로 줄인 다음 (sum, max, min, average 등) 그 결과를 모든 디바이스에 전송
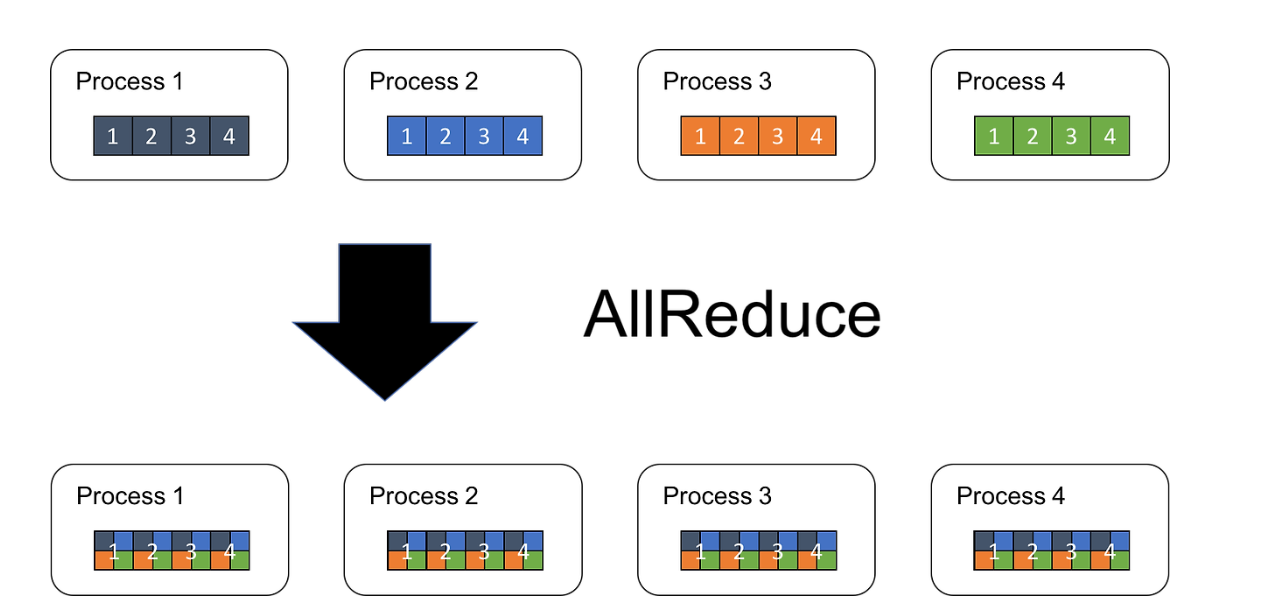
Allreduce 연산 (Allreduce Operation)
분산(병렬) 환경에서, 여러 프로세스(또는 GPU)가 각각의 데이터를 서로 교환하여 집계(reduction) 결과를 모든 프로세스가 갖도록 만드는 통신 패턴을 Allreduce라고 함.
주로 딥러닝의 데이터 병렬 학습에서, 각 GPU가 구한 그래디언트(Gradient)를 모두 합산(또는 평균)한 뒤, 그 결과를 다시 모든 GPU에 전달하기 위해 사용
1. Allreduce의 핵심 개념
-
집계 (Reduction)
- 여러 프로세스가 각자 계산한 결과값(예: 벡터, 스칼라 등)을 하나로 합치는 과정
- 합산, 평균, 최대·최소, 논리연산 등 다양한 연산이 가능
-
브로드캐스트 (Broadcast)
- 집계된 결과를 다시 모든 프로세스에 전달
2. Allreduce의 일반적 수식 표현
다음과 같이 개의 프로세스(또는 GPU)가 있고, 각 프로세스에서 계산된 결과를
라고 할 때, Allreduce는 모든 프로세스가 다음 값을 동일하게 갖도록 하는 연산입니다.
즉, 모든 프로세스는 최종적으로 값을 얻게 되며, 경우에 따라 합산(sum) 대신 평균(mean), 최댓값(max) 등 다른 연산이 적용될 수도 있습니다.
3. Allreduce 연산의 절차 (예시: 합산 연산)
-
Local Compute
- 각 프로세스 에서 로컬 연산을 통해 를 계산
-
Reduction Phase
- 전체 프로세스들이 통신하며 를 합산
- 결과적으로 어떤 노드(예: 루트 노드 등)에 가 모임
-
Broadcast Phase
- 합산 결과인 를 다시 모든 프로세스에게 전달
- 모든 프로세스의 최종 결과가
4. 예시 (데이터 병렬 딥러닝)
- Forward/Backward Pass
- 각 GPU 에서 입력 배치의 일부분으로 로컬 손실과 로컬 그래디언트 계산
- Allreduce를 통한 그래디언트 합산
- Shared Parameter Update
- 모든 GPU가 을 동일하게 수신, 동일한 파라미터 업데이트 진행
5. 요약
- Allreduce는 Reduction(집계)과 Broadcast(결과 배포)를 결합한 통신 연산
- 딥러닝 분산 학습 시, 그래디언트 집계에 자주 사용
- 구현 수준에 따라 Ring Allreduce, Tree Allreduce, Hierarchical Allreduce 등 다양한 최적화 기법이 존재
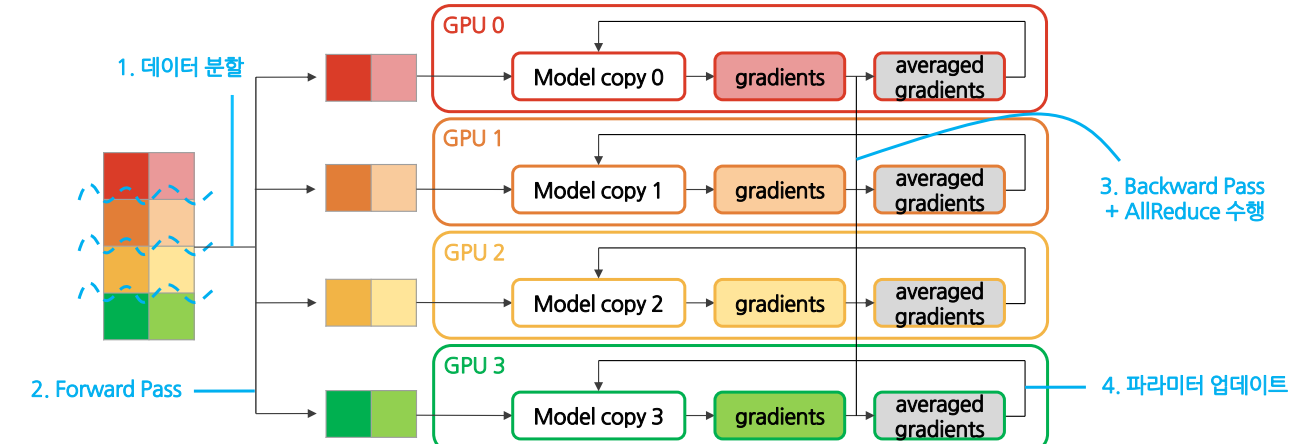
DDP Workflow
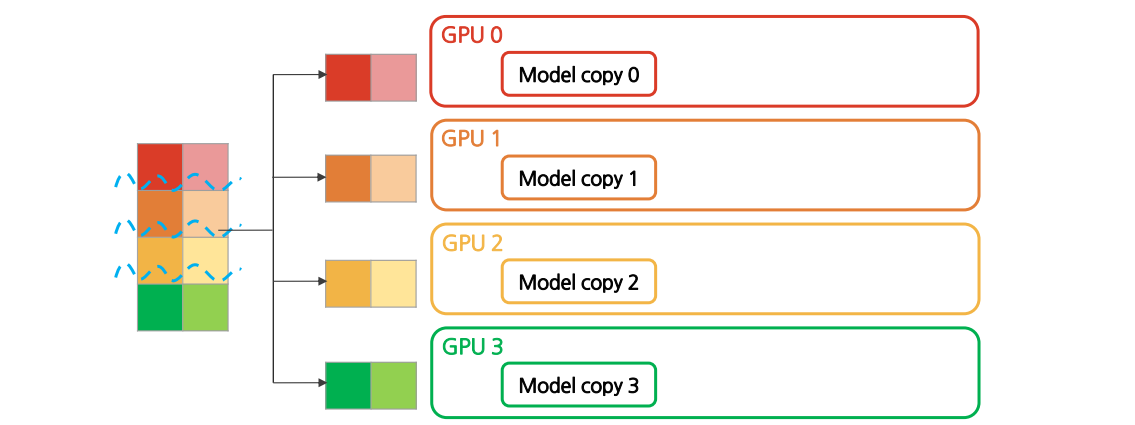
(1) Initialization
데이터셋을 미니배치(minibatch) 단위로 나눔
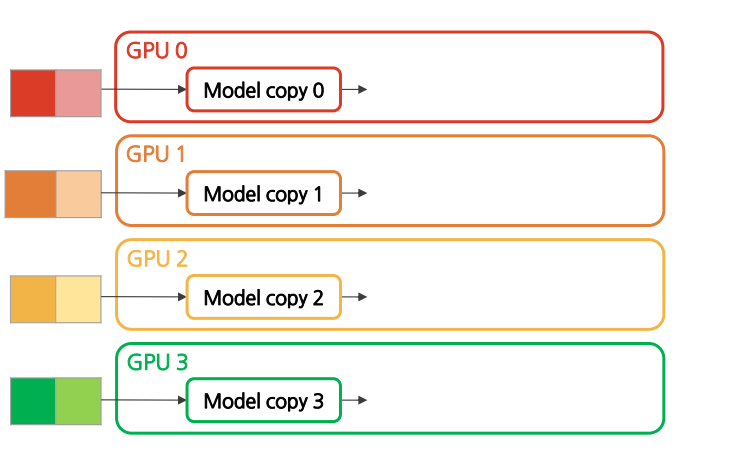
모델을 모든 GPU에 복제함→ 각 GPU에 같은 모델을 복제했으므로 weights들은 모두 동기화된 상태
(2) Forward Pass
- 데이터가 모든 GPU들로 분산됨
- 모든 GPU가 동일한 모델을 복제함→ 각 모델들은 동일한 weights들을 가지고 있음
- 각 GPU는 데이터와 복제된 모델을 통해 독립적으로 logits를 계산→ 각 GPU는 저마다의 logits를 가짐
- 각 GPU는 저마다의 logits를 가지고 loss 계산→ 각 GPU는 저마다의 데이터셋에 대한 loss를 가짐→ master GPU가 logits을 모으는 과정이 필요 없음
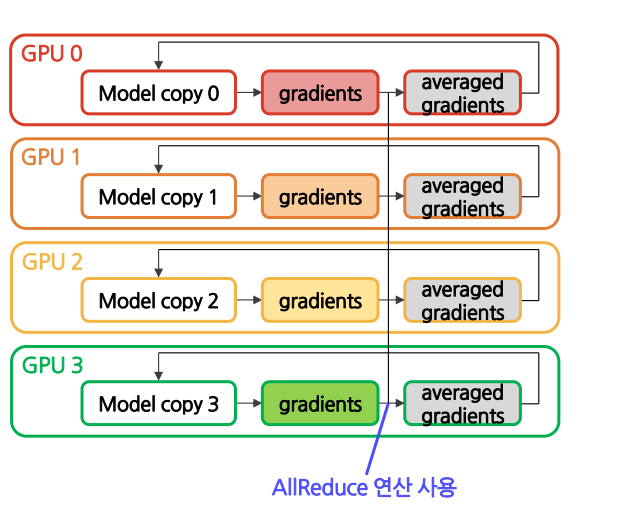
(3) Backward Pass
-
각 GPU는 backpropagation을 통해 gradients들을 계산→ 각 GPU는 저마다의 데이터셋에 대한 gradients들을 가짐
-
각 GPU들이 가지고 있는 local gradients들은AllReduce 연산을 거쳐 averaged gradients 값을 구하는 데에 사용됨→ 모든 GPU가 똑같은 averaged gradients 값을 가짐 → synchronized gradients
-
각 GPU는 이 averaged gradients를 가지고 저마다의 모델 weights들을 업데이트→ 각 GPU는 다시 동일한 모델을 가짐→ 다음 iteration의 forward pass에서 모델을 새로 복제할 필요가 없음
2.4 DP vs DDP
| 라이브러리 | DP (DataParallel) | DDP (DistributedDataParallel) |
|---|---|---|
| Gradient 동기화 | master GPU가 모두 모아 평균내어 모델을 업데이트 | AllReduce 연산을 사용하여 모든 GPU가 동시에 업데이트 |
| 모델 복제 | master GPU의 모델을 매 iteration마다 복제 | 모든 GPU가 Initialization 단계에서 한 번만 복제 |
| 통신 오버헤드 | master GPU에 리소스가 몰려 통신비용 매우 높음 | master GPU가 없어 통신비용 낮음 |
| 장점 | 구현이 쉬움 | 효율적인 통신으로 학습 속도 증가 |
| 단점 | 병목 현상 가능성 | 구현이 상대적으로 복잡 |
2.5 DDP code
# PyTorch DDP 구현 예시 코드 및 설명
아래 코드는 PyTorch의 **DistributedDataParallel (DDP)** 기능을 사용하기 위한 예시입니다.
- **`ddp_setup`**: 프로세스 그룹 초기화
- **`prepare_dataloader`**: `DistributedSampler`를 활용해 데이터를 분할해주는 DataLoader 준비
- **`Trainer` 클래스**: 모델을 DDP로 래핑(wrapping)하고 에폭마다 DistributedSampler 세팅
- **`main` 함수**: 각 프로세스에서 실행되는 함수, 데이터 및 모델 로딩 후 학습 진행
- **`mp.spawn(...)`**: 멀티 GPU를 활용하기 위해 여러 프로세스를 띄우는 함수
---
## 1. 전체 코드 예시
```python
import os
import torch
import torch.multiprocessing as mp
from torch.utils.data import DataLoader, Dataset, DistributedSampler
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# -----------------------------
# 1) ddp_setup 함수
# -----------------------------
def ddp_setup(rank, world_size, gpu_list):
"""
DDP 환경을 초기화하는 함수
"""
# (1) 환경변수 설정: 호스트 주소 및 포트 정의
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
# (2) 현재 프로세스가 사용할 GPU 할당
torch.cuda.set_device(gpu_list[rank])
# (3) 프로세스 그룹 초기화
dist.init_process_group(
backend="nccl", # CUDA/NVIDIA 환경에서 권장(nccl: nvidia collective communication library)
rank=rank,
world_size=world_size
)
# -----------------------------
# 2) prepare_dataloader 함수
# -----------------------------
def prepare_dataloader(dataset: Dataset, batch_size: int):
"""
분산 학습을 위한 DataLoader를 리턴.
DistributedSampler를 사용해 데이터를 병렬로 나눔.
"""
sampler = DistributedSampler(dataset)
return DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True if torch.cuda.is_available() else False,
shuffle=False, # 샘플러가 셔플을 해주므로 False 설정
sampler=sampler
)
# -----------------------------
# 3) Trainer 클래스
# -----------------------------
class Trainer:
def __init__(self, model, train_data, optimizer, gpu_id, gpu_list):
"""
Trainer 초기화 시 모델을 DDP로 감싸고,
train_data는 DistributedSampler가 적용된 DataLoader여야 함.
"""
# (1) 모델을 GPU에 로드
self.model = model.cuda(gpu_list[gpu_id])
# (2) DDP로 모델 래핑
self.model = DDP(self.model, device_ids=[gpu_list[gpu_id]])
self.train_data = train_data
self.optimizer = optimizer
def _run_epoch(self, epoch, max_epochs):
"""
에폭 단위 학습 로직
"""
# (1) Sampler에 에폭 설정 (매 에폭마다 다른 미니배치 분산 보장)
self.train_data.sampler.set_epoch(epoch)
# (2) 간단한 학습 루프 예시
self.model.train()
for batch_idx, data in enumerate(self.train_data):
inputs, labels = data
inputs, labels = inputs.cuda(), labels.cuda()
# Forward
outputs = self.model(inputs)
loss = torch.nn.functional.cross_entropy(outputs, labels)
# Backward
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if batch_idx % 10 == 0:
print(f"[GPU{dist.get_rank()}] "
f"Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item():.4f}")
def train(self, total_epochs):
for epoch in range(1, total_epochs + 1):
self._run_epoch(epoch, total_epochs)
# -----------------------------
# 4) main 함수
# -----------------------------
def main(rank, world_size, total_epochs, batch_size, selected_gpus):
"""
mp.spawn()에 의해 프로세스 별로 실행되는 함수
"""
# (1) 현재 프로세스에서 실제로 사용할 GPU ID
actual_gpu_id = selected_gpus[rank]
# (2) DDP 초기화
ddp_setup(rank, world_size, selected_gpus)
# (3) 예시용 dataset, model, optimizer 로딩
# (실제로는 사용자 정의 혹은 torchvision 등에서 로딩)
dataset = DummyDataset() # 예시용 Dataset
model = DummyModel() # 예시용 Model
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# (4) 분산 학습용 DataLoader 준비
train_data = prepare_dataloader(dataset, batch_size)
# (5) Trainer 초기화
trainer = Trainer(model, train_data, optimizer, rank, selected_gpus)
# (6) 학습 시작
trainer.train(total_epochs)
# (7) 프로세스 그룹 종료
dist.destroy_process_group()
# -----------------------------
# 5) mp.spawn을 통한 실행
# -----------------------------
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--total_epochs", type=int, default=10)
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--gpus", nargs="+", type=int, default=None,
help="사용하려는 GPU들을 지정. 예: --gpus 0 1 2")
args = parser.parse_args()
# (1) 사용 가능한 GPU 확인
available_gpus = torch.cuda.device_count()
# (2) world_size와 gpu_list 설정
if args.gpus is not None:
for gpu in args.gpus:
if gpu >= available_gpus:
raise ValueError(f"GPU {gpu} is not available. "
f"Only {available_gpus} GPUs are present.")
world_size = len(args.gpus)
gpu_list = args.gpus
else:
# 모든 GPU 사용
gpu_list = list(range(available_gpus))
world_size = len(gpu_list)
# (3) 멀티프로세스 스폰
mp.spawn(
main,
args=(world_size, args.total_epochs, args.batch_size, gpu_list),
nprocs=world_size,
join=True
)
3. Summary
Distributed Training
여러 GPU간에 데이터를 분할하거나 모델 자체를 분할하여 여러 GPU에 걸쳐 훈련 프로세스를 병렬(Parallelism)화하는 학습 기법
- Data Parallelism : 큰 데이터를 여러 GPU들에 분할하여 동시에 처리함으로써 학습 속도를 높임
- Model Parallelism : 큰 모델을 여러 GPU들에 분할함으로써 하나의 GPU로는 처리할 수 없는 대형
모델도 처리 가능(Tensor Parallelism, Pipeline Parallelism)
Data Parallelism
- GPU간의 출력값들을 바탕으로 복제된 모델들을 동일하게 업데이트 해주는 과정 필요
- General Data Parallelism (DP) : Backward Pass에서 master GPU가 모든 GPU들에서 계산된 gradient들을 모아 모델 복제본을 업데이트하고, Forward Pass에서 모든 GPU들이 master GPU의업데이트된 모델을 복사하여 훈련
- Distributed Data Parallelism (DDP) : DP에서 병목의 원인인 마스터 GPU를 없애고 모든 GPU들이 각자 알아서 모델 업데이트
4. 참고사항
A Brief Overview of Parallelism Strategies in Deep Learning
https://afmck.in/posts/2023-02-26-parallelism/
Data-Parallel Distributed Training of Deep Learning Models
https://siboehm.com/articles/22/data-parallel-training
