0. 데이터 분석이 필요한 이유
-
해석(Interpret)
-> 과거/현재 데이터 기반으로 현상태 파악
또는 발견하지 못했던 사실을 데이터분석으로 새롭게 파악 -
의사결정(Decision Making)
-> 특정 목적 하에 구성된 데이터를 바탕으로 의사결정 -
예측(prediction)
-> 과거데이터 패턴을 바탕으로 예측
-> 다양한 통계 모델과 AI/ML 을 통한 다양한 방법론
1. 시각화 종류
1-0) Barplot
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
axes[0].bar(group['male'].index, group['male'], color='royalblue')
axes[1].bar(group['female'].index, group['female'], color='tomato')
plt.show()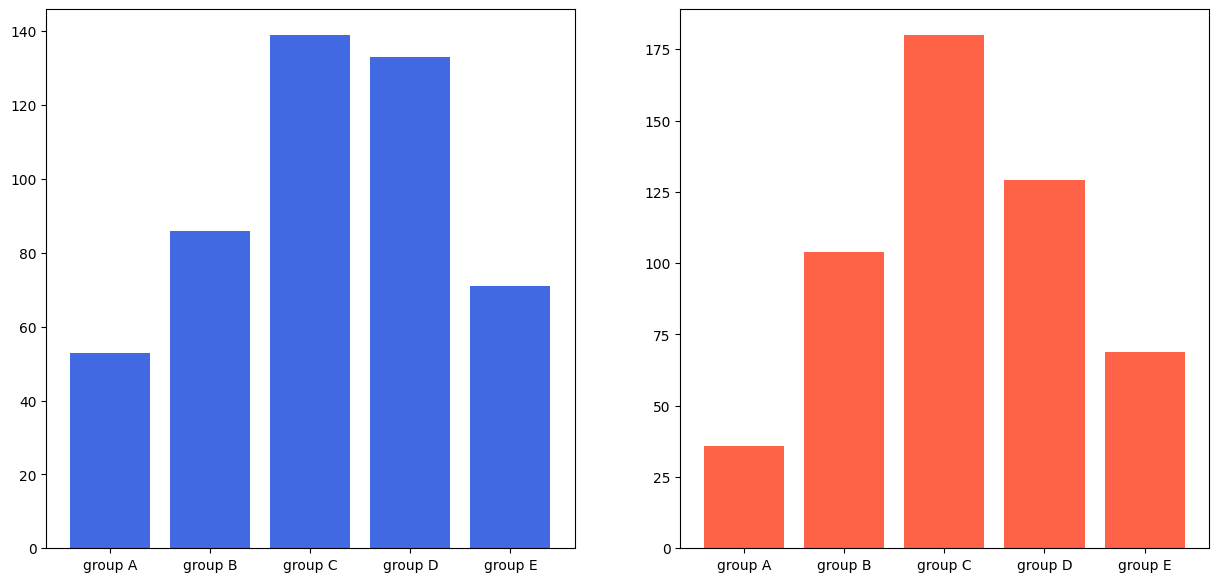
fig, ax = plt.subplots(1, 1, figsize=(12, 7))
idx = np.arange(len(group['male'].index))
width=0.35
ax.bar(idx-width/2, group['male'],
color='royalblue',
width=width, label='Male')
ax.bar(idx+width/2, group['female'],
color='tomato',
width=width, label='Female')
ax.set_xticks(idx)
ax.set_xticklabels(group['male'].index)
ax.legend()
plt.show()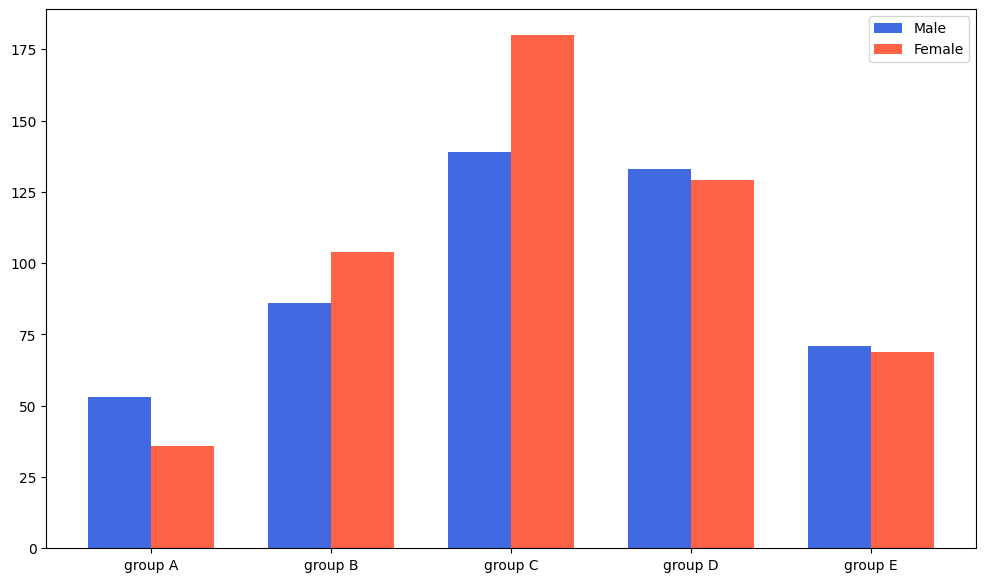
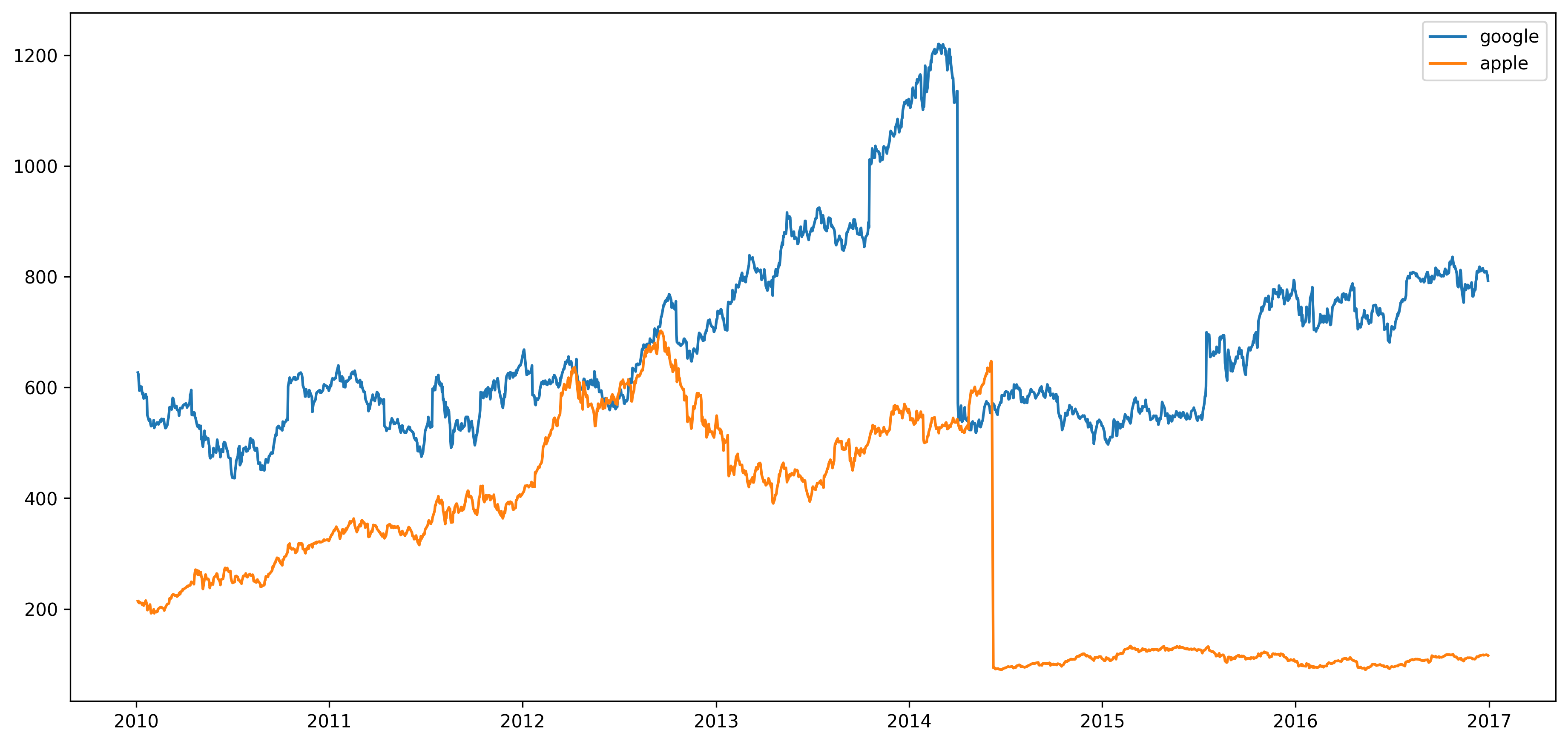
1-1) LinePlot
fig, ax = plt.subplots(1, 1, figsize=(15, 7), dpi=300)
ax.plot(google.index, google['close'], label='google')
ax.plot(apple.index, apple['close'], label='apple')
ax.legend() # 범례를 사용하여 구분할 수 있음
plt.show()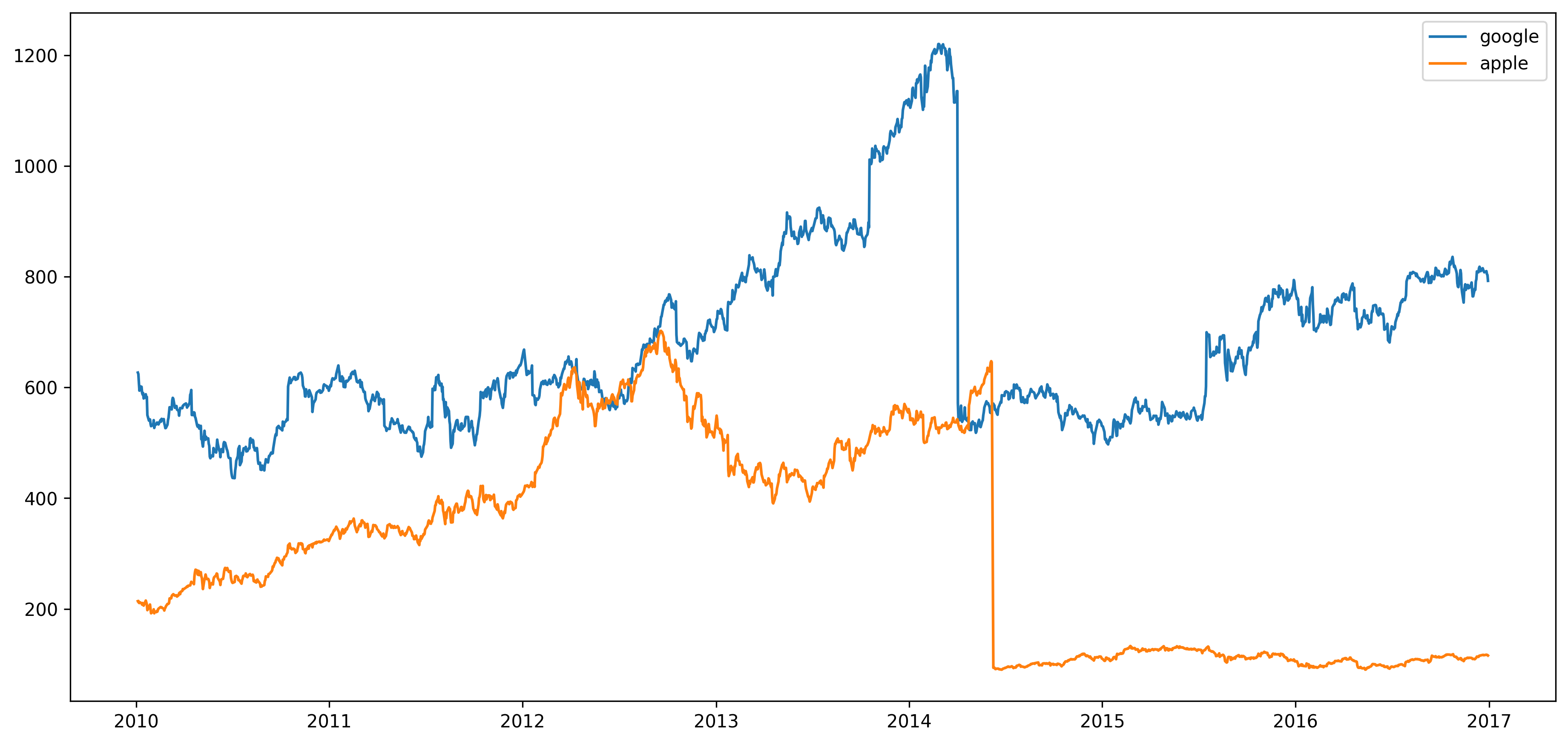
fig, ax1 = plt.subplots(figsize=(12, 7), dpi=150)
# First Plot
color = 'royalblue'
ax1.plot(google.index, google['close'], color=color)
ax1.set_xlabel('date')
ax1.set_ylabel('close price', color=color)
ax1.tick_params(axis='y', labelcolor=color)
# # Second Plot
ax2 = ax1.twinx()
color = 'tomato'
ax2.plot(google.index, google['volume'], color=color)
ax2.set_ylabel('volume', color=color)
ax2.tick_params(axis='y', labelcolor=color)
ax1.set_title('Google Close Price & Volume', loc='left', fontsize=15)
plt.show()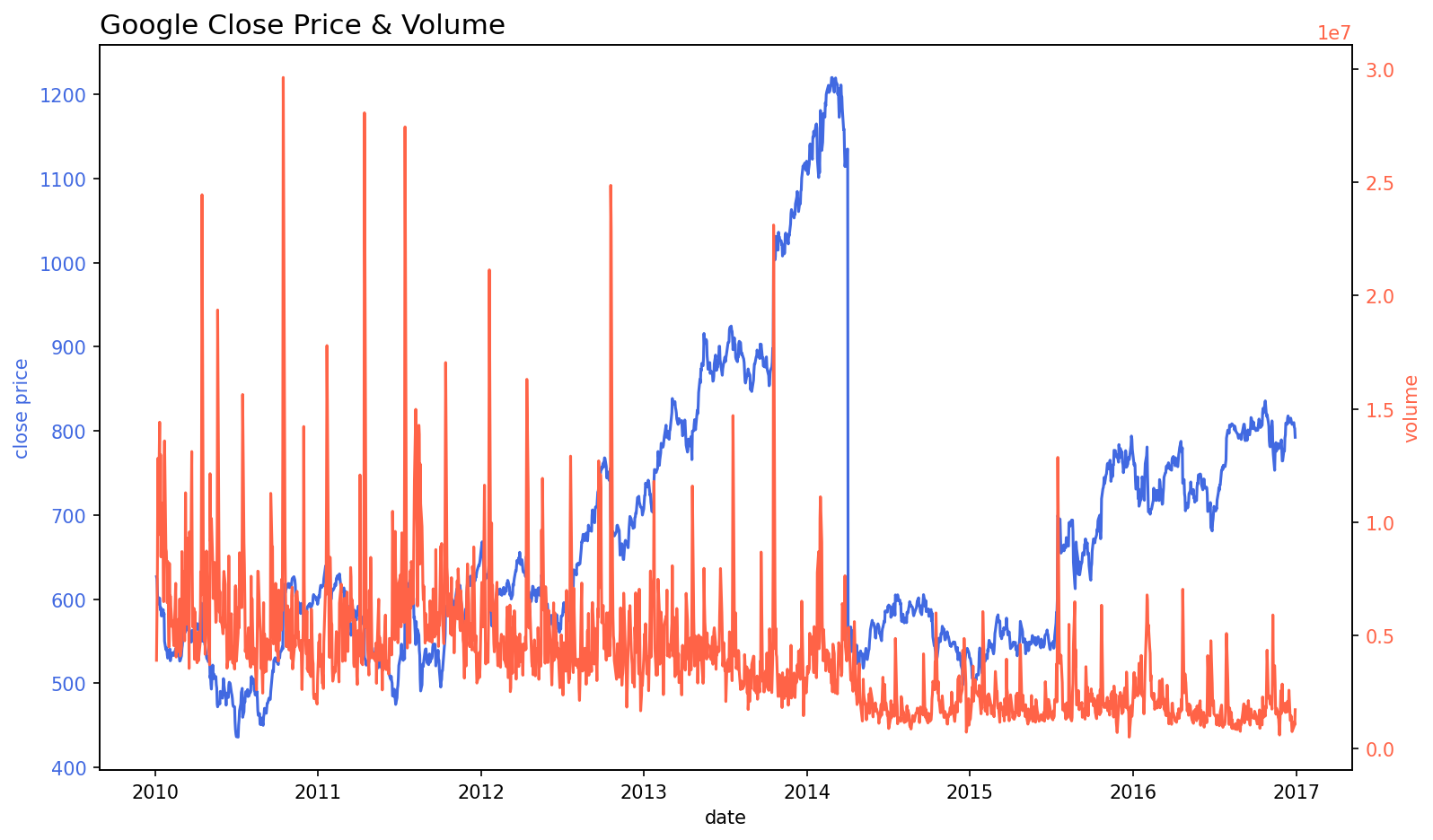
1-2) ScatterPlot
#sepal 데이터씀
fig, axes = plt.subplots(4, 4, figsize=(14, 14))
feat = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm']
for i, f1 in enumerate(feat):
for j, f2 in enumerate(feat):
if i <= j :
axes[i][j].set_visible(False)
continue
for species in iris['Species'].unique():
iris_sub = iris[iris['Species']==species]
axes[i][j].scatter(x=iris_sub[f2],
y=iris_sub[f1],
label=species,
alpha=0.7)
if i == 3: axes[i][j].set_xlabel(f2)
if j == 0: axes[i][j].set_ylabel(f1)
plt.tight_layout()
plt.show()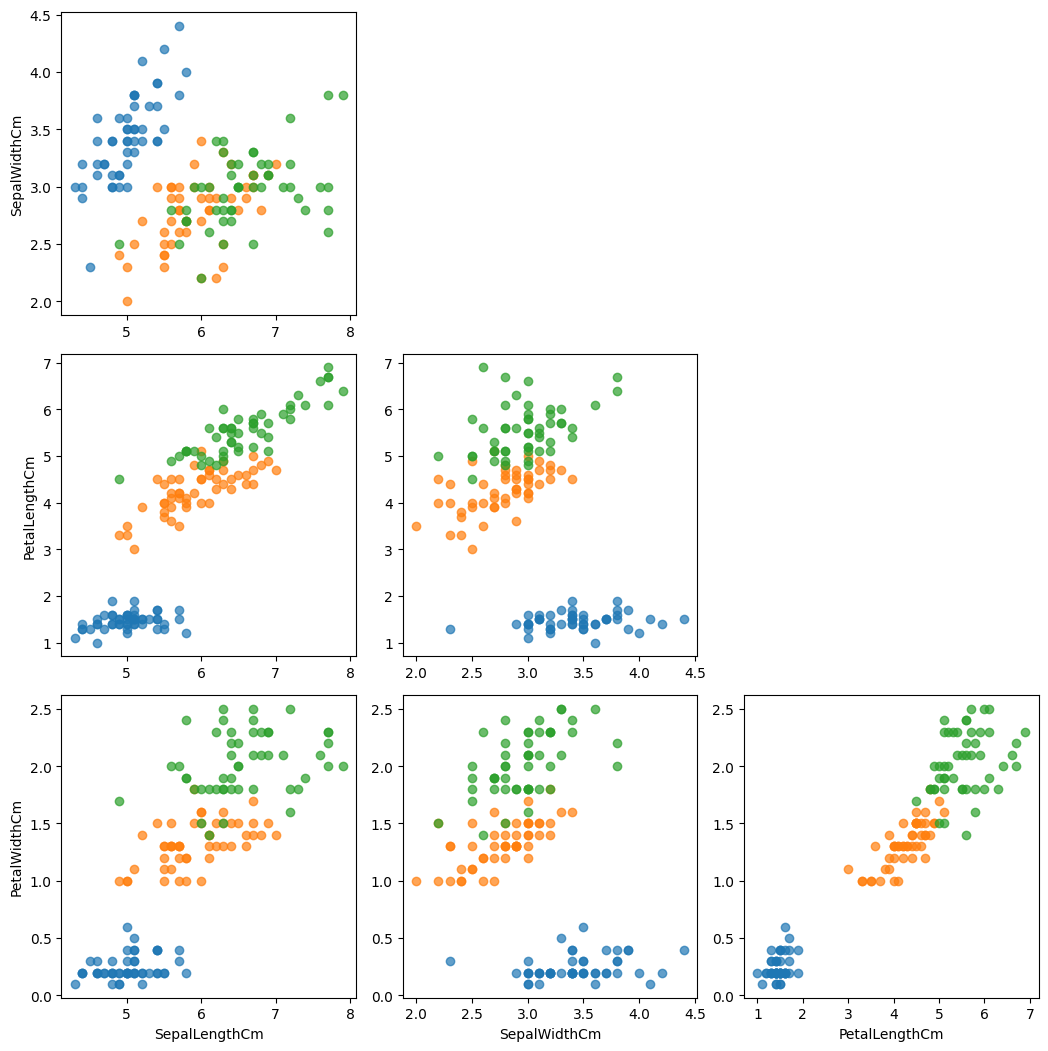
2. 정형데이터
2-0) 데이터종류
2-0-0) 명목형 데이터
-> 순서가 상관없이 항목으로 구분된 데이터
ex) 성별, 국가
-> One-Hot Encoding 으로 처리(대표적) 그외에는 Embedding, Hashing, 특정값에 따른 인코딩 등이 있음.
2-0-1) 순서형 데이터
-> 각 값이 우위 등의 순서가 존재하는 데이터
ex) 리커트 척도, 영화별점표
->
2-0-2) 구간형 데이터
-> 구간의 값이 중요함 (더하기뺄셈은 가능하나 곱하기나누기 불가능)
ex) 온도, 시간
2-0-3) 비율형 데이터
-> 0이 있는 데이터(사칙연산 모두 가능)
ex) 인구수, 횟수, 밀도
2-1) 데이터 전처리
2-1-0) 정규화_표준화
-> 각 데이터가 평균이 0 분산이 1
2-1-1) Min-Max
->데이터를 0과 1사이로 변환.
2-1-2) Box-cox Transformation
-> 데이터의 정규성을 개선하거나 분산의 안정화를 위해 사용되는 변환방법으로
특정 (람다) 값을 사용하여 데이터를 변환함.
3. 결측치와 이상치
3-0) 결측치 처리방법
-> 데이터에 대해서 잘 이해한 상태에서 결측치를 제거하던지 보간하던지 한다. 보통 파이썬으로 결측치 파악하는 코드는 이렇다.
df.isnull().sum()3-1) missingno
결측치를 시각화 하기 위해서 사용하는 패키지로 사용하면 시각적으로 바로 파악할 수 있어서 편하다.
import missingno as msno
msno.matrix(data) 하면됨!!

3-2) 이상치란?
-> 이상치(outlier)란 관측된 데이터의 범위에서 과하게 벗어난 값
그럼 과하게 벗어난 값이란 뭔가?🤔
-> 명확한 기준은 없다!! IQR, DBSCAN, Isolation Forest 이러한 방법론이 있을뿐 정확한 방법은 데이터의 특성에 따라서 알아서 잘 파악해야 한다..
3-3) 이상치 처리방법
① DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
-> 주변 포인트의 개수/경계/노이즈 등을 설정하여 집단 자동설정함.
-> 정규하 필수, 클러스터에 동떨어진 포인트가 생긴다면 자동으로 이상치처리

②Isolated Forest
-> 결정트리와 같이 기준에 따라 그룹 분리
- 루트노드와 거리를 통해 이상치 탐지
- 거리 정규화 필수
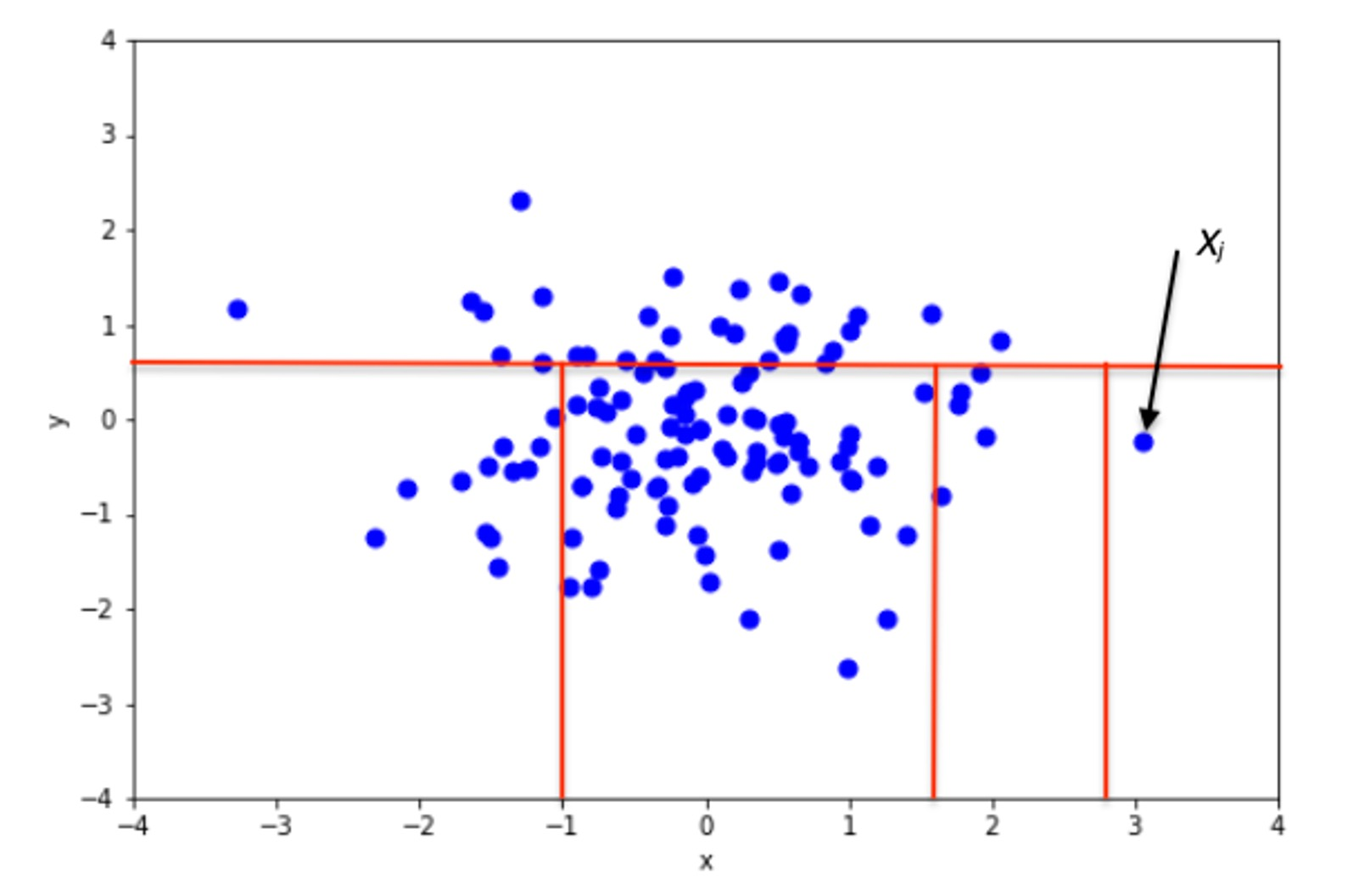
4. 군집분석과 차원축소.
4-1) 군집분석(클러스터링)
-> 유사한 성격을 가진 데이터를 그룹으로 분류하는 것.
ex) KMean, Hierachical Clustering , DBSCAN 등
4-2) 차원축소란? 그리고 종류
-> 차원축소란 특성 추출(feature extracting) 방법중 하나로 특성N 개를 M개로 줄이는 방법을 통칭함.
ex) PCA, t-SNE, LDA, Autoencoder등 다양함.
5.시계열데이터
5.0) 시계열 데이터란?
-> 시간 순서에 따른 데이터로 시간(time)이 중심임!
- 변화예측과 반복되는 패턴에 대한 인사이트 도출을 목표로 함.
5.1) 시계열 데이터 특징
- 추세(trend): 장기적인 증가 또는 감소
- 계절성(seasonality) : 특정 요일/계절에 따라 영향
- 주기(cycle) : 고정된 빈도가 아니지만 형태적으로 유사하게 나타나는 패턴
- 노이즈(noise) : 측정오류, 내부 변동성 등 다양한요인으로 생기는 왜곡~
5.2) 시계열 데이터 정상성/비정상성
-정상성: 시간에 따라 통계적 특성 변하지 않음
-비정상성: 시간에 따라 통계적 특성 변함 -> 차분(differece)필요!
5.3) 시계열 종류
- 이동평균
- AR, ARMA, ARIMA
- EMA 등
(나중에 따로 다시)
6. 이미지와 텍스트 데이터
6-0) 이미지데이터 처리
from torchvision import transforms
fig, ax = plt.subplots(2, 2, figsize=(9, 9))
transform1 = transforms.ColorJitter(brightness=3) #밝기조정
transform2 = transforms.ColorJitter(contrast=3) #대비도조정
transform3 = transforms.ColorJitter(saturation=3) #채도조정
transform4 = transforms.ColorJitter(hue=0.5) #색상조정
aug_img1 = transform1(test_image)
aug_img2 = transform2(test_image)
aug_img3 = transform3(test_image)
aug_img4 = transform4(test_image)
ax[0][0].imshow(aug_img1)
ax[0][1].imshow(aug_img2)
ax[1][0].imshow(aug_img3)
ax[1][1].imshow(aug_img4)
plt.show()6-1) 텍스트데이터 처리
6-1-0) 정규표현식
data = '안녕하세요 저는 홍길동이고ㅋㅋ 대한민국에서 살고 있어요! <b>개인정보</b> 제 이메일은 kildong@gmail.com이고 제 전화번호는 010-0000-1234 입니다.ㅋㅋㅋ'
import re
def clean_str(text):
pattern = '([a-zA-Z0-9_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+)' # E-mail제거
text = re.sub(pattern=pattern, repl='', string=text)
pattern = '010-(\d{3,4})-(\d{4})' # 전화번호 제거
text = re.sub(pattern=pattern, repl='', string=text)
pattern = '([ㄱ-ㅎㅏ-ㅣ]+)' # 한글 자음, 모음 제거
text = re.sub(pattern=pattern, repl='', string=text)
pattern = '<[^>]*>' # HTML 태그 제거
text = re.sub(pattern=pattern, repl='', string=text)
text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》]','', string=text) # 특수 문자 제거
text = re.sub('\n', '.', string=text)
return text6-1-1) 텍스트 시각화
- 워드크라우드 , 텍스트 네트워크 등 다양함.
