0. CV(ComputerVision)이 중요한 이유?
The human visual system is responsible for up to 80%(?) of sensory data
Almost 50%(?) of our brain is involved in visual processing
The most of information (80%) comes through our eyes
More than 50% of the brain is devoted to processing visual info.
1. CV란?
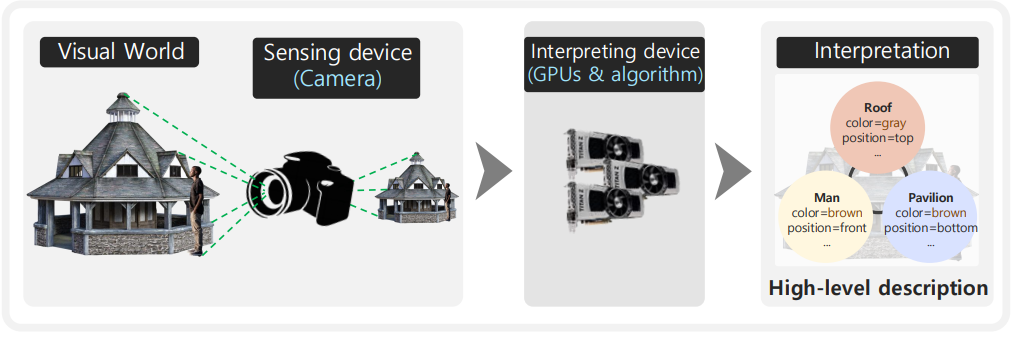
👉 Computer Vision이란, 컴퓨터가 이미지나 비디오를 분석하고 이해할 수 있도록 하는 기술과 학문!!
2. CNN부터 ViT 까지
2-0) FCN(FullyConnected) 문제점
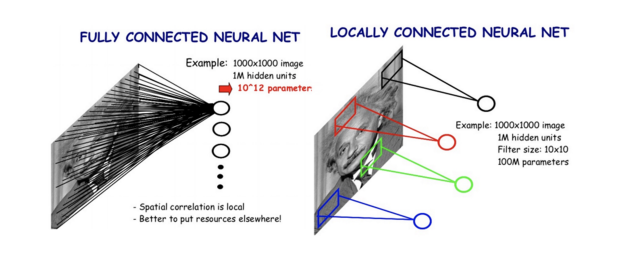
-> Fully Connected layer은 모든 픽셀 정보를 직접적으로 연결하기 때문에 Cropped하거나 조금만 움직여도 classify 를 잘못한다.
FC 레이어는 입력의 특정 공간적 관계를 무시하고, 단순히 모든 입력 뉴런의 값을 가중치와 편향을 통해 처리하므로 이미지의 작은 변형이나 자르는(Cropped) 작업이 입력데이터의 패턴을 크게 변경하므로 잘못된 분류.
2-1) CNN(Convolution Neural Network)
2-1-0) CNN이란 무엇?
📖 CNN이란 합성곱신경망으로, 합성곱레이어와 풀링 레이어를 통해 입력 이미지의 지역적 특징을 학습하고 위치와 형태의 변화에 더 강건함!!
2-1-1) CNN의 모델의 역사
(1) Alexnet
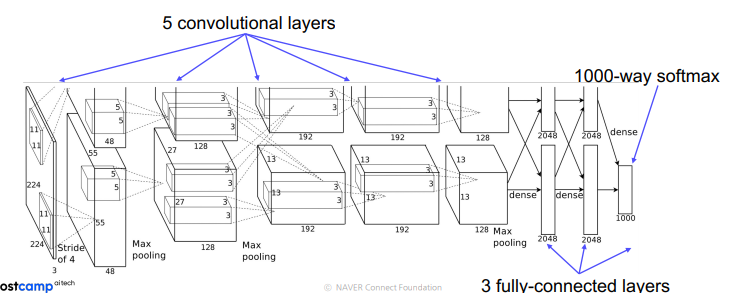
-
활성화 함수로 ReLU(Rectified Linear Unit) 사용
-
데이터 증강(Dataaumentation) 사용
-
완전연결층에서 50% 드랍아웃 적용
-
학습률 0.9, batch 128개의 모멘텀(momentum) 확률적 경사하강법 적용
-
7개의 신경망 사용(Conv-Pool-LRN-Conv-Pool-LRN-Conv-Conv-Conv-Pool-FC-FC-FC)
-
GPU 사용하여 병렬적으로 처리함.
(2) VGGnet(Visual Geometry Group)
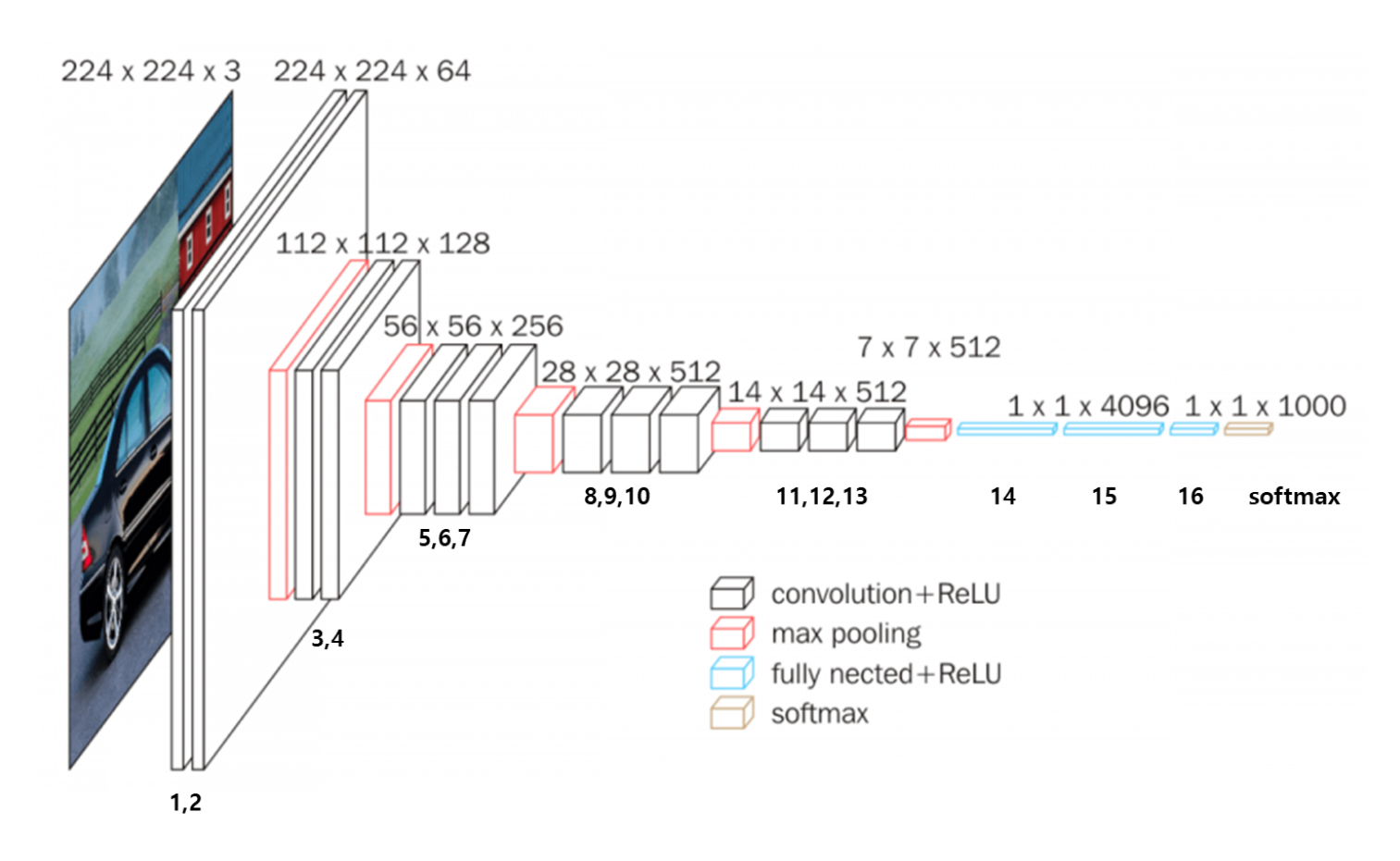
- VGGNet은 층을 깊게 쌓는 것이 층별 뉴런의 수를 늘려서 넓게 하는 것보다 효율적임을 알게 함!
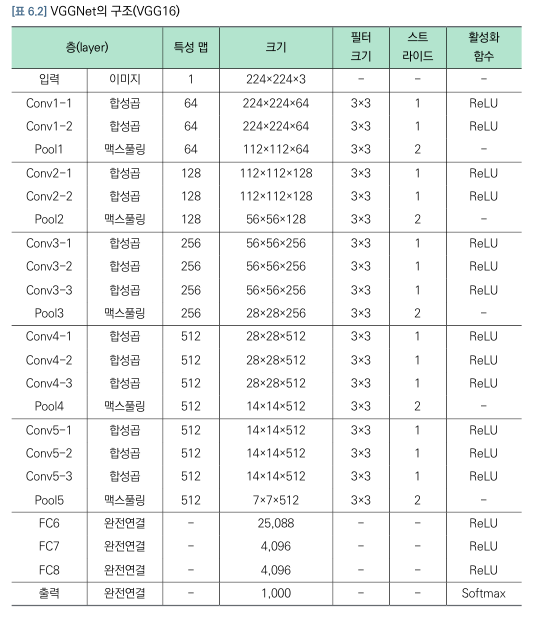
- 3x3 합성곱 필터와 3x3 최대풀링을 연속적으로 적용
- 활성화함수로 ReLU 함수를 모든 층에서 사용함.
- 합성곱 필터의 수가 합성곱 블록별로 64,128,512로 증가하도록 설계됨
- 합성곱 필터를 연속 적용한 후 최대 풀링을 반복 적용하는 과정에서 데이터 크기가 줄어들고 이후 완전연결층을 연속적으로 적용하여 모형 완성
(3) GoogLeNet
(L이 대문자인 이유는 LeNet과 연결되기 위함)
[GoogLeNet의 전반적인 구조]
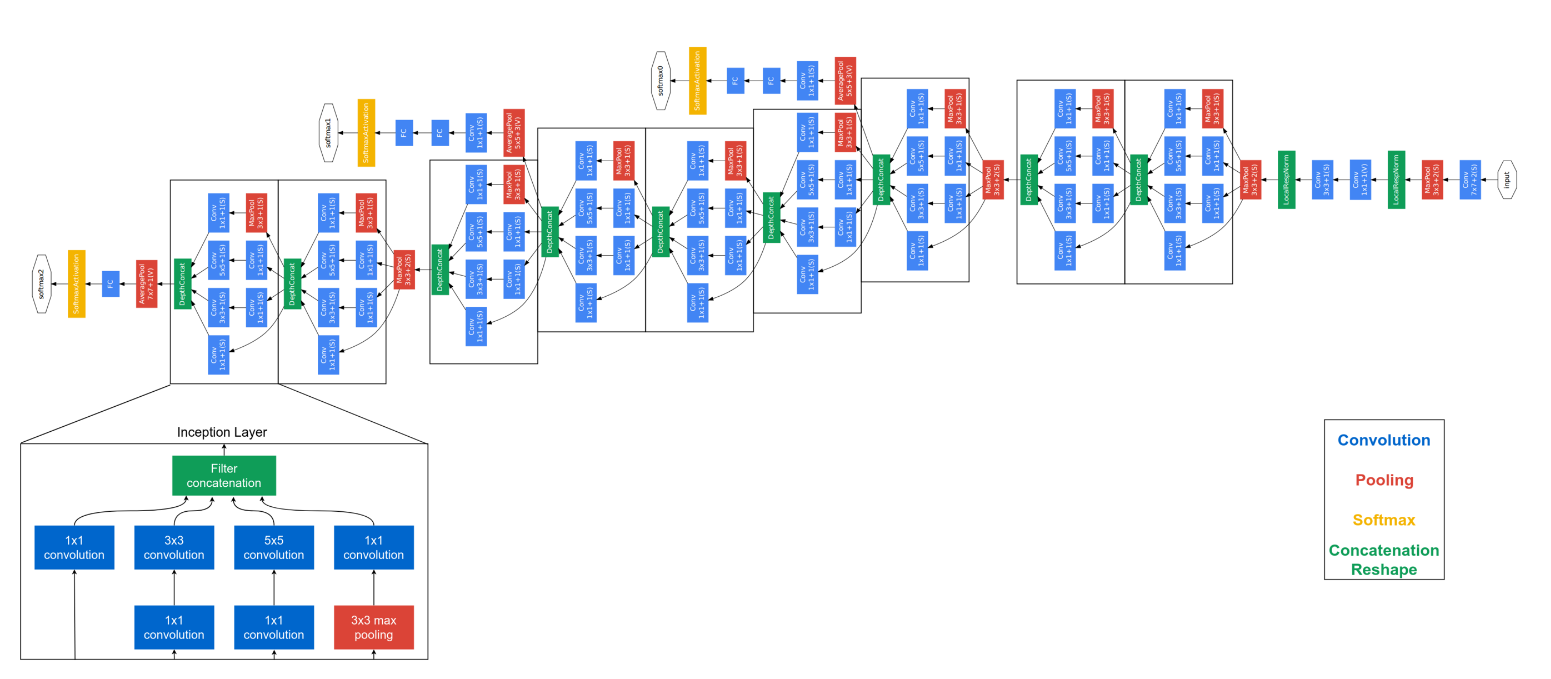
- 22층으로 깊게 설계된 합성곱 신경망으로 인셉션(inception)모듈을 포함에 가중치의 수를 Alexnet의 1/10수준인 600만개 수준으로 낮춤
- 파란색은 합성곱필터가 적용된 부분, 빨간색은 풀링, 노란색은 활성화 함수의 적용한 것이다.
- 중간결과 2개, 최종결과 1개가 나오고
전체손실함수 = 최종손실함수 +0.3x중간1 +0.3x중간2
[GoogLeNet의 인셉션 모듈]
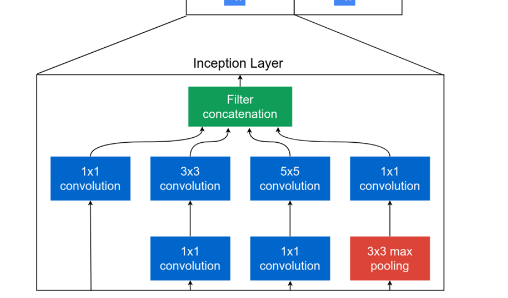
-
인셉션이란 신경망 속에 신경망을 만든 것으로 GoogLeNet에서는 9개의 인셉션 모듈이 포함되어 있다.
-
인셉션 모듈은 신경망을 깊게 하면서도 가중치의 수를 줄일 수 있어서 계산량을 획기적으로 줄일 수 있는 방법
-
인셉션 모듈은 여러 크기의 합성곱 필터를 적용한 후 이를 결합하여 이미지의 여러 특성을 살펴보는 것을 목적으로 만들어 졌다.
(4) ResNet
-
딥러닝 모형에서 층을 깊게 쌓을수록 경사소실의 문제가 남아 있고 계산이 많아지면서 오히려 성능이 낮아지는 문제가 있었다.
-
ResNet은 이러한 한계를 극복하고 인간의 성능보다 우수한 결과를 낸 최초의 모델이다. -> 그 방법이 잔차학습과 스킵연결
-
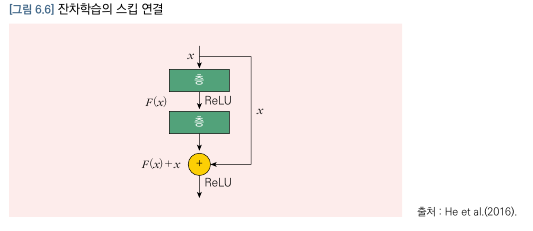
-
위 이미지를 보면 입력데이터 는 2개의 합성곱층을 거쳐서 가 되고, 에 2개의 합성곱층을 거치지 않은 를 더한 가 다음층에 연결된다. 이와 같이 가 합성곱층을 거치지 않고 연결한 것을 스킵연결이라고 한다.
-
실제 신경망의 가중치를 구할 때는 인 를 학습하게 되므로 이를 잔차학습이라고 한다.
📖 수학적 계산으로 좀더 들어가보자.
ResNet의 차 은닉층을 이라 하면 는 로 표현할 수 있다. 즉, 값이 점프하여 로 들어오게 된다. 따라서 스킵연결을 하면 일부 층이 학습되지 않더라도 경사소실 문제가 해결되어 전체 신경망을 학습시킬 수 있는 것이다.
-> 또한, 스킵 연결하여 온 값이 일반적으로 0이 아니므로 오차역전파에 따른 경사소실이 일어나지 않는다.
- ResNet 은 기본적으로 3x3합성곱 필터를 이용하여 완전연결망을 이용하지 않았다.
- Dropout 을 사용하지 않고 배치정규화를 사용하였다.
- 최대풀링을 사용하지 않고 스트라이드2를 이용하였고
- 스킵연결은 합성곱층마다 진행하였다.
- 때문에 ResNet은 학습하는데 매우 오랜 시간이 걸리지만, 학습 후 만들어진 딥러닝 모형으로 실제 데이터를 예측할 때는 매우 빠르게 실행된다.
2-2) ViT(VisionTransfomers)
2-2-0) Transformer란?
Transformer란 Attention 만을 이용하여 만들어진 Architecture이다.
-> 자세한 것은 Attention is All you need 논문리뷰(https://velog.io/@leejken530/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Attention-is-All-you-need)를 참조하자.
2-2-1) ViT란?
- Vision Transformer 로 CNN대신 Transformer Architecture를 활용하여 이미지를 처리한다.
원래 자연어처리에서 문맥을 이해하고 생성하는데 사용되었지만, ViT는 이 구조를 이미지 인식에 적용한 것!
-> 자세한것은 ViT 논문리뷰 참조!
2-2-2) Scaling law
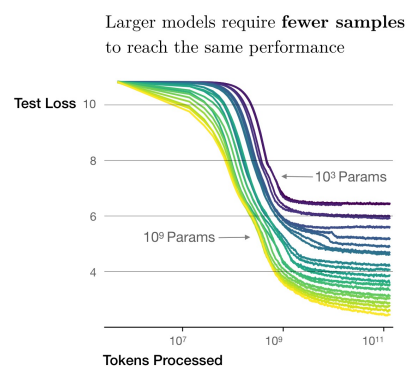
If there is a large amount of data,
o The model size increases,the better performance
o The more data is provided,the better performance
• Scalinglaw is not true for all models
o Transformers are models that follow scaling laws well
📖 Scaling law 란 많은 데이터가 있을 수록 더 좋은 퍼포먼스를 발현한다는 의미! 모든 모델이 그렇지는 않고 Transformer 아키텍쳐일때는 이런 scaling law 가 잘 적용한다는 의미
🤔 왜 Transformer 가 Scaling law 에 잘 적용되는 것일까?
👉 1. 자기회귀(auto-regessive)와 비선형성
-> Transformer는 셀프 어텐션(self-attention)을 사용하여 입력 데이터의 모든 부분을 상호 참조할 수 있다. 이로 인해 데이터의 모든 특징을 학습하여 비선형 함수의 조합으로 다양한 패턴을 모델링 할 수 있다.
- 병렬처리
Transformer 는 병렬 처리가 가능한 구조를 가지고 있어서 입력 시퀀스의 모든 부분을 동시에 처리할 수 있어 효율적!
2-2-3) Swin Transformer
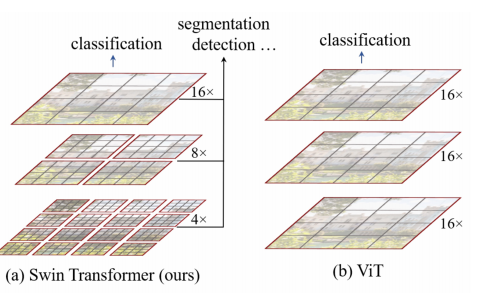
Hierarchical feature maps by merging image patches
Have linear computation complexity due to compute self-attention only with in each local window(redbox)
- Swin은 Shifted Window 의 줄임말고 Shifted Window 기반의 셀프 에텐션 매커니즘을 사용 -> 이는 이미지의 지역적인 정보와 전역적인 정보를 효과적으로 적용시키기위해 위 이미지와 같이 윈도우를 이동시키는 방식.
2-2-4) Self-supervised training
①MAE(Masked AutoEncoder) 사용
During pre-training, a large random subset of
image patches (e.g., 75%) is masked outMask Tokens are introduced after the encoder
Full set{encoded patchs, masked tokens } is processed by a decoder that reconstructs original image in a pixels
📖 이미지의 일부를 숨기고(masked) 그 모델이 숨겨진 부분을 예측하도록 학습함으로써 모델이 이미지의 구조와 내용을 더 잘 이해할 수 있도록 돕는 방법
② DINO(self-Distillation with No Labels)
-모델이 자신을 교사로 남아 자신의 출력과 예측을 바탕으로 학습하는 방법임.
-> 논문참조.
